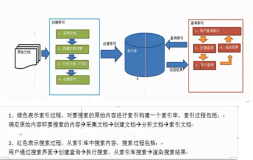
项目中需要用到全局搜索的功能,因为服务器流程审核比较严格,所以选择了lucene。总体来讲,个人感觉lucene主要有几个重点,分词器(我们用的中文IK分词),索引文件,索引查询几块。这里主要截取代码稍微介绍。还有一个问题就是Lucene貌似没有做向下兼容的操作,每个版本的API都不一定相同。附上jar包,demo,ik分词器jar包,分词器操作手册等,仅供参考和新手共同了解学习进步。
如下代码片段,指定了索引文件生成的位置,使用的分词器,lucene版本,索引的生成模式等。
OpenMode.CREATE是重新生成
OpenMode.APPEND是增量更新
项目中主要用的着两种,API里面还有各种其它的方式。
IndexWriter writer = null;
try {
directory = FSDirectory.open(new File("C:/lucene/testIndex"));
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig conf = new IndexWriterConfig(Version.LUCENE_40,
analyzer);
conf.setOpenMode(OpenMode.CREATE);
conf.setMaxBufferedDocs(100);
writer = new IndexWriter(directory, conf);
下面是生成索引的代码片段。
1主要有Document document = new Document();(新建一个doc对象,往里面添加索引用的)
2其中对分词有StringField,TextField,IntergerField等等,主要决定字段的类型,以及精细度,实际操作发现比如 “我爱北京”,String会分成“我|爱|我爱|北京”,Text直接就是“我爱北京“,当然具体如何分词跟选用的分词器也有关系。
String query = "。。。";
ResultSet result = st.executeQuery(query);
while (result.next()) {
Document document = new Document();
document.add(newStringField("id",result.getString("id"),Field.Store.YES));
if(result.getString("theme") != null){
if("userInfo".equals(result.getString("type"))){
document.add(new StringField("theme", result.getString("theme"), Field.Store.YES));
}
document.add(new TextField("theme", result.getString("theme"), Field.Store.YES));
}
if(result.getString("content") !=null){
document.add(new TextField("content", result.getString("content"), Field.Store.YES));
}
document.add(new StringField("type", result.getString("type"), Field.Store.YES));
System.out.println(document.getFields()+"--------------------");
writer.addDocument(document);
索引生成完毕之后就是查询了,如下是查询的。获取查找reader的实例
public IndexSearcher getSearcher() throws IOException {
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
return searcher;
}
单条件查询的代码块如下,传入需要查找的字段,num为支持数量筛选
WildcardQuery 模糊查找,TermQuery 精确查找
public void searchByTerm(String field, String name, int num) throws IOException {
IndexSearcher searcher = getSearcher();
// WildcardQuery 模糊查找
// TermQuery 精确查找
Query query = new WildcardQuery(new Term(field, name));
TopDocs tds = searcher.search(query, num);
System.out.println("count:" + tds.totalHits);
for (ScoreDoc sd : tds.scoreDocs) {
Document doc = searcher.doc(sd.doc);
System.out.println("id:" + doc.get("id"));
System.out.println("theme:" + doc.get("theme"));
System.out.println("content:" + doc.get("content"));
System.out.println("type:" + doc.get("type"));
}
}
多条件需要用到布尔查询,布尔组合条件查询的时候
主要有Occur.SHOULD(相当于or),Occur.MUST(相当于and),Occur.MUST_NOT(相当于!)列如代码中,就是要查找主题和正文中包含人名为陈洁的内容,但是排除news(资讯)
public void booleanQuery() throws Exception {
IndexSearcher searcher = getSearcher();
Term term = new Term("theme", "陈洁");
WildcardQuery wildcardQuery = new WildcardQuery(term);
Term term3 = new Term("type", "news");
TermQuery termQuery2 = new TermQuery(term3);
Term term2 = new Term("content", "陈洁");
WildcardQuery wildcardQuery2 = new WildcardQuery(term2);
TermQuery termQuery = new TermQuery(term2);
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.add(wildcardQuery, Occur.SHOULD);
booleanQuery.add(termQuery2, Occur.MUST_NOT);
booleanQuery.add(termQuery, Occur.SHOULD);
TopDocs topDocs = searcher.search(booleanQuery,null, 10);
System.out.println("共检索出 " + topDocs.totalHits + " 条记录");
System.out.println();
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scDoc : scoreDocs) {
Document doc = searcher.doc(scDoc.doc);
System.out.println("id:" + doc.get("id"));
System.out.println("theme:" + doc.get("theme"));
System.out.println("content:" + doc.get("content"));
System.out.println("type:" + doc.get("type"));
}
}