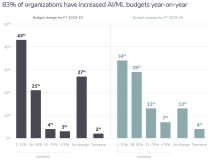
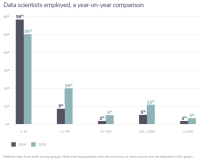
为了成为一个机器学习公司,你需要工具和流程去克服数据、工程和模型方面的挑战。
在过去的这些年,为了构建基础设施,数据社区专注于聚集和收集数据,并使用数据来改进决策。我们现在可以看到,对先进的分析和机器学习的兴趣在许多行业的垂直方领域上激增。
在这篇文章中,我分享了我去年9月在纽约Strata Data 公司发布的一篇演讲中的幻灯片和笔记,为大家提供一些对增强公司机器学习能力的建议。这些信息来自于在许多不同的问题领域中,应用机器学习的前沿的实践者、研究人员和企业家的对话。

与其他技术或方法一样,一个成功的机器学习项目从确定正确的用例开始。例如,机器学习推荐和减少客户流失的应用有很多,但对于应用程序来说,一个有用的分类有如下几点:
1.提高决策的应用程序
2.改进商业运营的应用程序
3.产生收入的应用程序
4.可以帮助预测或防止欺诈或风险的应用程序

为了成为一个“机器学习公司”,当你开始构建模型时,首先你要熟悉你将要面对的关键障碍是什么。如果你咨询主要的从业者,通常会有三件事:
1.数据:现在大多数应用都依赖于监督学习,所以一切都从质量良好的标记(训练)数据集开始。
2.工程:你如何使用一个原型并生产它?在部署到生产环境之后,如何监视模型?
3.模型:虽然现代的机器学习库使你更容易将模型与你的数据匹配,但仍然存在一些挑战
在这篇文章的剩余部分,我将讲解如何面对这些挑战。

在构建用于训练机器学习模型的标记数据集时,使用已访问的数据非常重要。随着新的数据源不断地出现在网络上,对大多数公司来说,数据集成是一项正在进行的工作——你目前对数据基础设施的投资甚至可以让你获得足够的数据来启动。你还可以使用公开的(开放的)数据或你可以从第三方提供商购买的数据来丰富现有的数据集。

好消息是机器学习社区意识到训练数据是一个主要的瓶颈。所以研究人员一直致力于那些让你从较少的训练数据(弱监督)开始或者允许你将一个问题中得到的知识用于另一个环境(转移学习)的研究。

随着数据越来越重要,有一些初创公司和公司在探索数据交换。数据交换使组织可以在保护隐私和机密的同时共享一些数据。同时,也有一些类似的研究,致力于开发安全的机器学习算法。在消费者金融领域存在应用欺诈检测,例如,如果隐私和安全能够得到保证,那么在机密数据上共享学习可能是有价值的。

今年早些时候,我们观察到,公司开始在构建机器学习模型和监控他们的行为方面创造了一个新的角色。但是机器学习工程师的新角色真的是必要的吗?

对于越来越多的公司来说,答案是:是的,这样的专家很需要。如果你创建了一个你需要知道的关于生产和监控模型的清单,那么你将得到一组广泛的工具和技术。

机器学习的研究正在飞速发展。公平地说,大多数公司都无法跟上研究人员发布的所有新技术和新工具。想象以下的实验:在接下来的五年里,进展会停滞不前(非常不可能,自我幽默一下)。我认为,有足够的工具可以让公司在很长一段时间里保持忙碌。

深度学习,一种已经成功应用于计算机视觉和语言问题的技术。大多数公司仍处于将深度学习应用于熟悉的数据类型(文本、时间序列、结构化数据)或使用它来替换现有模型(包括它们当前推荐系统)的早期阶段。我希望在接下来的几年里能看到许多有趣的,涉及到深层神经网络(DNN)的案例研究,。

随着关于深度学习的所有激动人心的一面,我们有时会忘记有很多有趣的,不依赖于神经网络的新数据应用。
随着模型被推向先进设备,我对最近在协作学习方面的工作感到兴奋。展望人工智能,在线学习和持续学习的工具将是必不可少的。

数据社区开始认识到,除了优化定量或业务指标之外,还需要更多的模型。模型是否强大到能抵御对抗性攻击?在某些应用程序模型中必须是可解释和可理解的。
公平:你了解你的训练数据的分布情况吗?如果你不了解,请注意过去的忽视可能会导致未来的忽视。
透明度:随着机器学习变得越来越流行,用户对那些被最优化的计量机构的了解和发言权越来越感兴趣。
尽管近年来这一领域取得了很大进展,但研究人员和理论家们仍不清楚这一点。我们仍然处在一个“试错”的时代。深度学习可能减少了对人工特征工程的需求,但是仍然有很多决策倾向于建立一个DNN(包括网络架构和许多超参数的选择)。

我们可以把模型构建看作是探索机器学习算法的空间。企业需要能够以一种有原则和高效的方式进行探索。这意味着维护可重复的管道,从实验中节省元数据,协作工具,并利用最近的研究成果。

那么,公司在做什么来让这种探索成为可能呢?大多数机器学习都需要标记(训练)数据,因此任何平台都从输入数据存储系统的强大数据管道开始,数据科学家和机器学习工程师可以访问这个数据存储系统。对于所有公司来说,数据集成是一项重要的、持续的练习。
公司还允许数据科学家共享特征和生成这些特征的数据管道。让你了解特性的相对重要性:让公司告诉你他们使用的是什么算法通常会容易得多;而要让他们描述什么对他们的模型是最重要的,则困难得多。
领先的公司让他们的数据科学家使用几个机器学习库。强迫你的数据科学家使用一两个“开发中的”库是很疯狂的。他们需要能够进行实验,这可能意味着让他们使用各种各样的库。
有些公司为生产机器学习模型提供工具,并在部署后监控它们。公司还在使用开源技术构建自己的部署和监控工具。如果你正在寻找一个用于模型部署和监控的开源工具,Clipper是加州大学伯克利分校的崛起实验室的一个新项目,它现在可以让你轻松地部署使用几个流行的机器学习库编写的模型。更重要的是,Clipper团队很快就添加了模型监控。(几家公司将在2018年3月的Strata Data San Jose,描述他们如何实现模型部署和监控)。
要成为一个“机器学习公司”,你需要工具和流程来克服数据、工程和模型方面的挑战。公司刚刚开始在他们的产品中使用和部署机器学习。工具仍在不断完善,最佳实践才刚刚开始出现。
作者介绍:Ben Lorica 是O'Reilly Media的首席数据科学家,同时也是Strata Data 会议和O'Reilly Artificial Intelligence 会议的项目负责人。

原文网址:
https://www.oreilly.com/ideas/how-companies-can-navigate-the-age-of-machine-learning