摘要
许多业务有实时数据处理的需求。相较于传统的数据库+流计算+应用服务器方案,使用基于表格存储实时数据流的Serverless计算方案有自动弹性伸缩及开发简单、部署简单等优点。
本文通过一个想象的物流案例来说明如何实施“基于表格存储实时数据流的Serverless计算方案”。本文更侧重于架构和代码的介绍与解说,更详细的实施步骤请看这里。
一个物流案例
案例介绍
在物流系统运行过程中,在使用扫码枪写入相应的物流信息后,所有用户预设的计算任务将在后台自动的运行。在本文中,扫码枪写入的物流信息最终将体现为物流大屏的实时在线显示。

其中飞线图表示寄出的包裹,飞线图的流动方向为寄件城市到收件城市,飞线图每10s进行汇聚。气泡图用于表示包裹收件城市的实时统计,气泡大小表示在途的包裹数量。
使用传统的数据库+流计算+应用服务器方案来进行设计,将不可避免的遇到以下痛点:
- 峰值极大,单机数据库难以承载
- 峰谷差距大,运维难,容量规划难
- 大屏展示延迟高
- 成本高:成本既体现在低谷时闲置的设备成本,也体现在为了适应峰谷进行设备调整导致的运维成本,还体现在应用层为了可以弹性调整而产生的开发成本等
基于实时数据流的Serverless计算方案
下图为Serverless实时计算方案的简要架构图,更详细的架构细节将在整体架构部分介绍。这个架构最重要的优势是:随着写入并发度的增加,整个系统会自动扩容。

在本方案的实现中,使用了以下的一些成熟的商用产品:
-
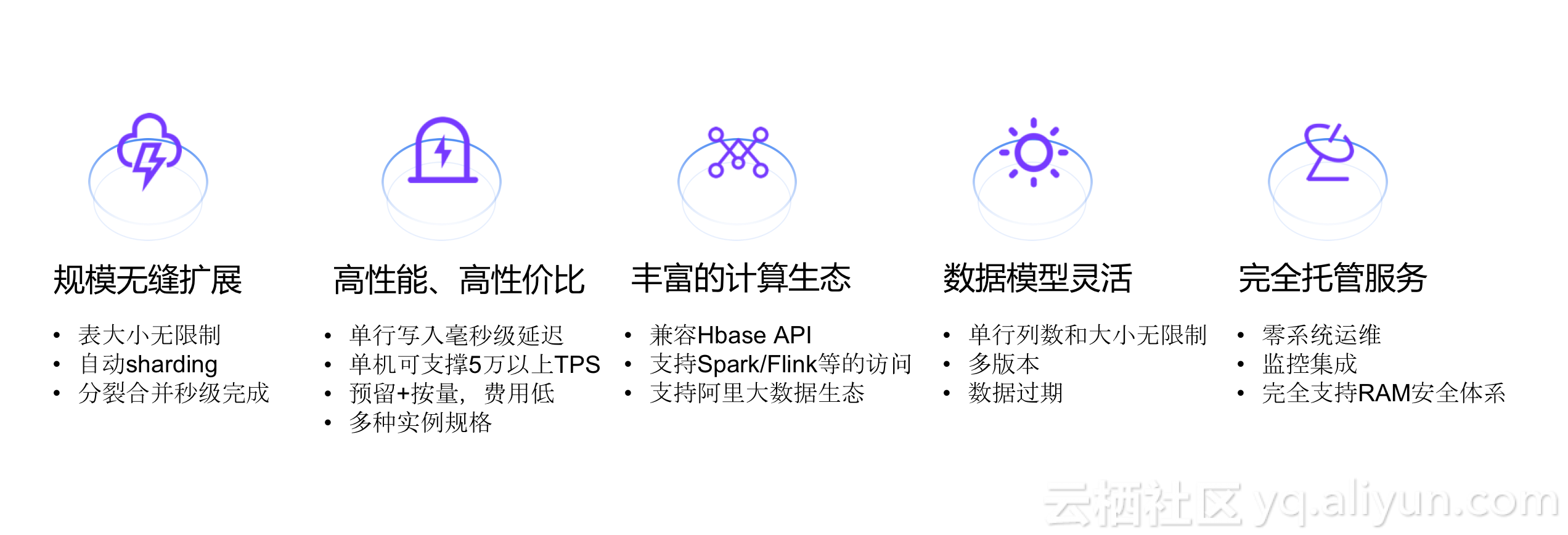
表格存储(TableStore)是阿里云自主研发的专业级分布式NoSQL数据库,是基于共享存储的高性能、低成本、易扩展、全托管的半结构化数据存储平台,支撑互联网和物联网数据的高效计算与分析。下面这张图片展示了表格存储的具体特性。
 - 阿里云函数计算,是一个事件驱动的全托管计算服务。通过函数计算,您无需管理服务器等基础设施,只需编写代码并上传。函数计算会为您准备好计算资源,以弹性、可靠的方式运行您的代码,并提供日志查询,性能监控,报警等功能。借助于函数计算,您可以快速构建任何类型的应用和服务,无需管理和运维。更棒的是,您只需要为代码实际运行消耗的资源付费 - 代码未运行则不产生费用。
- API 网关(API Gateway)提供高性能、高可用的 API 托管服务,,提供完整的 API 发布、管理、维护生命周期管理。用户只需进行简单的操作,即可快速、低成本、低风险地开放数据或服务。
- DataV旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
在整个架构中用户无需触及服务器,用户所需要做的工作主要包括:
- 设计好表格存储中的数据库表结构。
- 编写好函数计算中的函数来处理增量数据流。
- 在阿里云控制台上配置各个产品的连接。
整体架构
下图为基于表格存储实时数据流的Serverless计算方案的整体架构图。

在用户使用扫码枪写入包裹信息到包裹流水表后,产生的增量数据流将自动触发流水转换函数。流水转换函数依据包裹基础信息表清洗并转换包裹流水信息,然后异步调用飞线聚合函数和气泡聚合函数。飞线聚合函数根据预设的时间间隔(本文为10s)聚合包裹飞线数据,并将数据存于飞线聚合表内。气泡聚合函数用于聚合气泡数据,并将结果写入气泡聚合表中。
尤其值得指出,随着扫描枪写入并发量的增加,表格存储会自动sharding。而随着表格存储的分区数的增加,流水转换函数的实例数也会相应增加,下游的飞线聚合函数和气泡聚合函数的实例数于是也相应增加。这样一来,整个系统实现了自动扩容。
在DataV的大屏实时展示中,飞线图的更新通过API网关调用飞线展示函数来获取飞线聚合表中的数据并进行处理,以获得飞线起始位置和结束位置。呼吸气泡图的更新将通过DataV与表格存储的直连方式从气泡聚合表中实时获取所需的经度、纬度、在途数量等数据。
数据表设计
设计前言
在设计好数据表的结构后,可以通过TableStore官网控制台或客户端便捷的创建所需的数据库实例和表。也可以使用TableStore提供的丰富SDK(Java、NodeJS、Go、Python、.NET、C++)来进行相应的数据表操作。
包裹流水表
包裹流水表主要用于记录包裹的流水信息。每次扫码枪扫一次包裹都会产生一条记录。该表的特征是(峰值)并发写入量巨大,总数据量巨大,数据批量过期,随机读取较少。故而选用表格存储的容量型实例,在保证业务的性能需求的情况下大幅降低成本。
包裹流水表的结构如下表所示,主键列包括快递单号(DeliveryId)和SeqNum(操作流水号), 其中DeliveryId是一个UUID,SeqNum设置为自增主键列以进一步提高写入并发的能力。属性列包含扫码枪号(Scanner)和操作类型(OpType)。我们在示例中定义四种操作类型:收件入库(SignIn)、客户签收(SignOff)、转运出库(TransferOut)和转运入库(TransferIn)。
| 列名 | 类型 | 说明 |
|---|---|---|
| DeliveryId | 主键列(String) | 快递单号 |
| SeqNum | 自增主键列(Integer) | 操作流水号 |
| Scanner | 属性列(String) | 扫码枪号 |
| OpType | 属性列(String) | 操作类型 |
包裹基础信息表
包裹基础信息表用于记录包裹的基础信息,比如寄件人、收件人、收件地址等。在我们的示例中,我们关心寄件城市和收件城市。在流水转换函数中,我们需要低延迟地读取寄件城市和收件城市,故选用表格存储的高性能实例。包裹基础信息表的结构如下表所示,主键列为快递单号(DeliveryId), 属性列包括寄件城市(SourceCity)和收件城市(DestinationCity)。得益于表格存储的NoSQL,用户可以添加其他业务需要的属性列而不会影响现有的业务。
| 列名 | 类型 | 说明 |
|---|---|---|
| DeliveryId | 主键列(String) | 快递单号 |
| SourceCity | 属性列(String) | 寄件城市 |
| DestinationCity | 属性列(String) | 收件城市 |
飞线聚合表
飞线聚合表用于DataV飞线图的实时读取。其特征是读写并发以及延迟需求都较均衡,并且由于存放清洗处理后的数据,数据量也不大。示例中我们选用表格存储的高性能型实例。我们将以10s对齐的时间戳作为唯一主键列。我们将寄件城市和收件城市拼接后作为属性列列名(比如Shanghai_Chengdu)。我们利用这个NoSQL特性将传统上需要范围扫描的操作转变成了单行上的读写,进一步提高了吞吐量。
| 列名 | 类型 | 说明 |
|---|---|---|
| Timestamp | 主键列(Integer) | 按特定间隔对齐的时间戳 |
| SourceCity_DestinationCity | 属性列(Boolean) | 寄件城市_收件城市 |
由于DataV的飞线图绘制所需的数据为飞线的起始位置和结束位置的列表,例如[{"from":"116.46,39.92","to":"114.06,22.55"}],无法直接从表格存储中直接读取特定的列来获取绘制飞线图所需的数据。在我们的示例中,我们引入了飞线展示函数完成这个转换。并且在DataV和飞线展示函数中间我们插入了API网关来方便管理。于是,只要在DataV中配置好对应的API网关数据源,即可以实时获得所需的飞线数据。

气泡聚合表
气泡聚合表用于DataV呼气气泡图的实时读取,选用的同样是表格存储的高性能实例。呼吸气泡图用于表示特定目标城市的实时在途包裹数量,所以对于气泡聚合表而言,只需要进行包裹在途数量的实时更新,其余字段都可以预先置于数据表内。该表的结构如下表所示,主键为目标城市(DestinationCity), 属性列包含经度(lat)、纬度(lng)、气泡类型(type)和在途数量(value)。
| 列名 | 类型 | 说明 |
|---|---|---|
| DestinationCity | 主键列(String) | 目标城市 |
| lat | 属性列(Double) | 经度 |
| lng | 属性列(Double) | 纬度 |
| type | 属性列(Integer) | 气泡类型 |
| value | 属性列(Integer) | 在途包裹数量 |
对于DataV的呼吸气泡图而言,如下面动图所示,气泡图所需获取的属性包括lat、lng、type和value,这些字段可以通过使用DataV直连TableStore的方式来获取。首先配置好TableStore的数据源,接着选定getRange操作方式,指定所需的主键范围和限制,同时指定所需获取的列名,最后设定好自动更新间隔时间,就可以自动的获取到更新呼吸气泡所需的配置信息。

关于DataV直连TableStore更详细的介绍,可参见DataV 配置 OTS 数据源。
函数代码实现
文中所有的代码都可以在 https://github.com/aliyun/tablestore-demo-delivery 下载。示例中的代码都使用Python语言编写。Python语言也许不是最适合计算类需求的编程语言,阿里云函数计算也不止支持Python,不过Python却非常适合展示。这一点需要在具体实施的过程中注意。
流水转换函数
函数入口:
def main(event, context):
records = cbor.loads(event)[u'Records']
otsc = new_ots_client(context)
fcc = new_fc_client(context)
flywire(otsc, fcc, records)
on_delivery(otsc, fcc, records)其中event的格式请参考表格存储官方文档。CBOR是一个序列化标准(RFC-7049)。它类似JSON,但和JSON不同的是,它是一个二进制格式,并且它原生支持二进制数据块。
这两个特点使得它特别适合表格存储实时数据流。
- 表格存储原生支持二进制数据列
- CBOR的编解码较JSON更快,这样可以省出时间给用户的计算逻辑
将event解码后得到一个映射,其中u'Records'项包含一组记录。
在本示例中,每条记录都是一条扫描枪产生的流水数据,列如:
{"Info": {"Timestamp": 1506667478896000},
"Type": "PutRow",
"PrimaryKey": [{"ColumnName": "DeliveryId",
"Value": "e006bea0-4794-4153-a468-3306232096bc"},
{"ColumnName": "SeqNum",
"Value": 1506667478897000}],
"Columns": [{"ColumnName": "OpType",
"Type": "Put",
"Value": "NewDelivery",
"Timestamp": 1506667478897},
{"ColumnName": "Scanner",
"Type": "Put",
"Value": "2b985a71-1908-45d8-8e34-f8d528ae916d",
"Timestamp": 1506667478897}]}context中包含了用户的认证鉴权信息。我们以此构造了表格存储的客户端(otsc)和函数计算的客户端(fcc)。然后分别执行飞线相关逻辑和气泡相关逻辑。
飞线相关逻辑如下:
def flywire(otsc, fcc, records):
xs = [{'Timestamp': x[u'Info'][u'Timestamp'],
'DeliveryId': x[u'PrimaryKey'][0][u'Value'],
'OpType': op_type(x)}
for x in records]
xs = [x for x in xs if x['OpType'] == u'SignIn']
deliveries = set() # pairs from source city to destination city
for x in xs:
deli_id = codecs.encode(x['DeliveryId'], 'utf-8')
delivery = fetch_delivery_info(otsc, deli_id)
deliveries.add((delivery.source_city,
delivery.destination_city,
x['Timestamp']))
deliveries = list(deliveries)
LOGGER.info('flywire paylod: %s', deliveries)
if len(deliveries) > 0:
fcc.async_invoke_function(
FC_SERVICE,
'flywireUpdater',
payload=cbor.dumps(deliveries))气泡相关逻辑如下:
def on_delivery(otsc, fcc, records):
xs = [{'DeliveryId': x[u'PrimaryKey'][0][u'Value'],
'OpType': op_type(x)}
for x in records]
xs = [x for x in xs if x['OpType'] in [u'SignIn', u'SignOff']]
acc = {}
for x in xs:
deli_id = codecs.encode(x['DeliveryId'], 'utf-8')
delivery = fetch_delivery_info(otsc, deli_id)
dest = delivery.destination_city
if dest not in acc:
acc[dest] = 0
if x['OpType'] == u'SignIn':
acc[dest] += 1
elif x['OpType'] == u'SignOff':
acc[dest] -= 1
acc = [(k, v) for k, v in acc.items() if v != 0]
LOGGER.info('accumulator paylod: %s', acc)
if len(acc) > 0:
fcc.async_invoke_function(
FC_SERVICE,
'accumulator',
payload=cbor.dumps(acc))这两者的处理逻辑都是类似的:
- 清洗原始流水
- 结合包裹基础信息表将对下游无意义的id转换成下游需要的数据,并聚集
- 异步调用下游。这里异步的作用除了减少本函数执行时间之外,也可以进一步提高整个系统的弹性。
飞线聚合函数
def main(event, context):
deliveries = cbor.loads(event)
LOGGER.info('deliveries: %s', deliveries)
otsc = new_ots_client(context)
rows = to_rows(deliveries)
req = to_req(rows)
resp = otsc.batch_write_row(req)
puts = resp.get_put()
for _, fails in puts:
for x in fails:
LOGGER.error('put error: %s', x)程序主体的逻辑是将上游流水转换函数传来的寄件城市-收件城市对(以及该寄件动作发生的时间点)组织成若干行(通常仅一行)。然后将这些行打包成一个批量更新请求发给表格存储。具体组织这些行以及请求的代码如下:
def align_timestamp(ts):
return ts / 1000000 / 10 * 10
def to_rows(deliveries):
deliveries = [('%s_%s' % (codecs.encode(x, 'utf-8'), codecs.encode(y, 'utf-8')),
align_timestamp(z))
for x,y,z in deliveries]
rows = {}
for x,y in deliveries:
if y not in rows:
rows[y] = set()
rows[y].add(x)
rows = [(x, list(y)) for x, y in rows.items()]
return rows
def to_req(rows):
cond = ots.Condition(ots.RowExistenceExpectation.IGNORE)
rows = [ots.Row([('Timestamp', x)],
{'put': [(z, True) for z in y]})
for x, y in rows]
row_items = [ots.UpdateRowItem(x, cond) for x in rows]
table_item = ots.TableInBatchWriteRowItem(OTS_TABLE, row_items)
req = ots.BatchWriteRowRequest()
req.add(table_item)
return req飞线展示函数
LOCATIONS = {
'Beijing': '116.46,39.92',
'Shanghai': '121.29,31.13',
'Chengdu': '104.06,30.67',
'Shenzhen': '114.06,22.55'}
def main(event, context):
otsc = new_ots_client(context)
now = datetime.now() - datetime(1970, 1, 1)
aligned_now = (int(now.total_seconds()) / 10 - 1) * 10
_, row, _ = otsc.get_row(OTS_TABLE, [('Timestamp', aligned_now)], max_version=1)
result = {'isBase64Encoded': False,
'statusCode': 200,
'headers': {'Content-Type': 'application/json'}, 'body': []}
if row is None:
return json.dumps(result)
else:
attrs = row.attribute_columns
names = [x[0] for x in attrs]
cities = [x.split('_') for x in names]
locs = [{'from': LOCATIONS[x], 'to': LOCATIONS[y]} for x,y in cities]
result['body'] = locs
return json.dumps(result)飞线展示函数的逻辑更为直白。当DataV周期性的请求到达后,飞线展示函数从飞线聚合表上读取上一个10秒对应的行,将其中的寄件城市-收件城市转换成地理坐标返回给DataV。
气泡聚合函数
def main(event, context):
random.seed()
incr = cbor.loads(event)
LOGGER.info('payload %s', incr)
otsc = new_ots_client(context)
for city, inc_val in incr:
city = codecs.encode(city, 'utf-8')
last_backoff = 1
max_backoff = 512
while True:
_, row, _ = otsc.get_row(OTS_TABLE,
[('DestinationCity', city)],
columns_to_get=['value'],
max_version=1)
old_val = extract_row_value(row)
new_val = old_val + inc_val
new_row = ots.Row([('DestinationCity', city)], {'put': [('value', new_val)]})
try:
_ = otsc.update_row(OTS_TABLE,
new_row,
ots.Condition(ots.RowExistenceExpectation.IGNORE,
ots.SingleColumnCondition('value',
old_val,
ots.ComparatorType.EQUAL,
pass_if_missing = False)))
break
except ots.OTSError as ex:
last_backoff = backoff(last_backoff, max_backoff)上游流水转换函数传来的是收件城市以及该城市的在途包裹数量的增量。所以气泡聚合函数的逻辑是
- 读取某城市的旧值
old_val - 若该城市的当前值等于
old_val,则更新为新值new_val。
此“比较再更新”动作必须原子地完成,因为气泡聚合函数有可能同时有多个实例同时在运行。也就是说,当多个函数实例同时修改同一个收件城市的包裹数量时,只有一个能够成功。失败者则需要退避重试。
原子“比较再更新”直接使用表格存储提供Conditional Update这个特性实现。表格存储正在开发Atomic Increment特性,可以使得这里的退避重试不再必要,进一步简化逻辑。
总结
传统的数据库+流计算+应用服务器方案有四大痛点:
- 峰值极大,单机数据库难以承载
- 峰谷差距大,运维难,容量规划难
- 大屏延迟高
- 成本高
相应地,基于表格存储实时数据流的Serverless计算方案有针对以上痛点的优势:
- 随业务量自动增长的弹性
- 无需触及机器。无需规划集群容量。
- 亚秒级延迟
- 低成本
- 代码简单,直达核心业务逻辑
从本文描述的场景扩展开去,不难发掘出类似的一些场景,也能发挥表格存储+函数计算的优势:
- 物流的包裹流水及处理
- 智能家电的操作信息收集及处理
- 车联网的车辆轨迹信息收集及处理
- 实时交易大屏
- 物联网场景的异常数据实时预警
