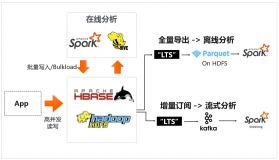
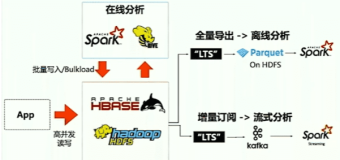
对于thriftserver 我们主要从2个大的方面进行分析:thrift的使用;thriftserver的部署;thriftserver的启动,初始化;thriftserver的读写等请求处理;
一:thrift的使用
Thrift的主要目的是方便各个语言可以使用HBase,java,c++,py,PHP,等等;在我们下载下来的hbase的文件里面的下面的目录:
hbase/hbase-thrift/src/main/resources/org/apache/hadoop/hbase/thrift
你会看到2个文件夹,分别是:
hbase git:(hbase) ll */*
-rw-r--r-- 1 xxxxx xxxx 24K 8 15 09:40 thrift/Hbase.thrift
-rw-r--r-- 1 xxxxx xxxx 16K 8 15 09:40 thrift2/hbase.thrift
2个不同版本的Thrift文件,有不同的区别,具体的区别参考链接的文章大概知道两者的区别,这里主要就一种的用法进行对应的介绍;
1>.首先要在自己的机器上面部署安装thrift软件;注意,服务端的thrift编译环境和client需要一样。我们云HBase的Thrift的版本是0.9.0,所以希望你们编译的thrift版本也是0.9.0,这样以后进行交互才没有问题;具体的安装可以参考Thrift链接,也可以用别的方案,比如我是直接是用brew的命令行。
2>.thrift -gen php Hbase.thrift 会对应的在本地目录下生产gen-py的对应的一个文件夹,如果是生产别的语言的话,使用别的命令,具体命令参考Thrift链接,当然这上面也有介绍thrift的安装。
thrift git:(hbase) ll
total 56
-rw-r--r-- 1 xxxxx xxxx 24K 8 15 09:40 Hbase.thrift
drwxr-xr-x 4 xxxxx xxxx 136B 8 23 16:02 gen-php
我们需要的是gen-php的文件夹,当然,也可以生产c++,py,java等等;
3>.实际上在Hbase.thrift的文件里面已经有告诉我们怎么使用这些函数以及数据结构,不如我最简单的现在需要进行get操作;使用的是php语言的话,那么thrift文档里面有下面的介绍;
/**
* Get a single TCell for the specified table, row, and column at the
* latest timestamp. Returns an empty list if no such value exists.
*
* @return value for specified row/column
*/
list<TCell> get(
/** name of table */
1:Text tableName,
/** row key */
2:Text row,
/** column name */
3:Text column,
/** Get attributes */
4:map<Text, Text> attributes
) throws (1:IOError io)
/**
* TCell - Used to transport a cell value (byte[]) and the timestamp it was
* stored with together as a result for get and getRow methods. This promotes
* the timestamp of a cell to a first-class value, making it easy to take
* note of temporal data. Cell is used all the way from HStore up to HTable.
*/
struct TCell{
1:Bytes value,
2:i64 timestamp
}
上述的东西我们看到了,get方法,你需要人为的输入table的name,row key,column 的name,以及你需要的些属性,解释的意思就是,get 一个单独的cell,一列的数据;当然,如果你需要别的东西的话,那是另外的节后会有的;
4>.需要获取得到thrift相关的依赖的库,比如,Transport,Factory,Protocol等等,这个在thrift的最原始的包里面会有的,但是还是要提醒下,一定要明确client 和服务端的thrift版本要一致,不然会出问题;
ini_set('display_errors', E_ALL);
$GLOBALS['THRIFT_ROOT'] = '/root/hbase';
require_once( $GLOBALS['THRIFT_ROOT'] . '/Thrift.php' );
require_once( $GLOBALS['THRIFT_ROOT'] . '/Thrift/transport/TSocket.php' );
require_once( $GLOBALS['THRIFT_ROOT'] . '/Thrift/transport/TBufferedTransport.php' );
require_once( $GLOBALS['THRIFT_ROOT'] . '/Thrift/protocol/TBinaryProtocol.php' );
require_once( $GLOBALS['THRIFT_ROOT'] . '/gen-php/Hbase.php' );
$ip=xxxx;
$port=xx;
$socket = new TSocket($ip, $port);
$transport = new TBufferedTransport($socket);
$protocol = new TBinaryProtocol($transport);
$client = new HbaseClient($protocol);
$transport->open();
//case test
二:thriftserver的部署
关于hbase的thriftserver的部署,以及参数之类的这篇文章有介绍,这里就不做介绍了。
上述文章中没有对如果部署ThriftServer进行步骤性介绍,这里介绍下,首先你下载了hbase-bin的二进制包以后,你需要在本地搭建thriftservr的话,需要做3件事情:1.配置conf文件,conf文件夹下的的hbase-site.xml文件里面需要配置下远端的zk地址(远端的hbase需要开启本地的白名单);2.配置本地的thriftserver的堆内存,这个基于你的操作属性进行设置,如果你的scan单次会涉及很多的数据,建议设置大等,不过一般都设置个128M就ok了,(ecs如果是内存足够);3.到bin目录下,执行sh hbase-daemon.sh start thrift 当然,这里启动哪个版本的thrift也是基于上面文章的介绍以及个人选择进行的。然后就可以使用了。
四:Thriftserver的初始化启动
最初的话,我们从最基本的启动接口 开始入手看如何启动Thriftserver,我们的启动命令是sh hbas-deamon.sh start thrift/thrif2,启动对应的thriftserver,我们可以进入最终启动的bin目录下的hbase的可执行文件进行查看,基于输入的不同thrit 还是thrift2,启动的是org.apache.hadoop.hbase.thrift.ThriftServer,org.apache.hadoop.hbase.thrift2.ThriftServer的这个class 文件,这里我们以简单的org.apache.hadoop.hbase.thrift.ThriftServer进行对应的源码分析,分析启动的时候做的操作,进入hbase的源码,以thriftserver的main方法进入:
public static void main(String [] args) throws Exception {
VersionInfo.logVersion();
try {
new ThriftServer(HBaseConfiguration.create()).doMain(args);
} catch (ExitCodeException ex) {
System.exit(ex.getExitCode());
}
}
以此为入口调到ThriftServerRunner内部的run方法,在这个函数内部我们会看到Thriftserver的初始化建立本地的server,包括设定使用与thrift的服务端相关信息包括:TProtocolFactory,TProcessor,TTransportFactory等等基本信息初始化完成,此外我们比较关心的就是这个thriftserver的server的初始化,这主要是基于不同的implType去创建,这里默认使用的是THREAD_POOL 的方式的,我们以默认的方式往下看:
// Thread pool server. Get the IP address to bind to.
InetAddress listenAddress = getBindAddress(conf);
int readTimeout = conf.getInt(THRIFT_SERVER_SOCKET_READ_TIMEOUT_KEY,
THRIFT_SERVER_SOCKET_READ_TIMEOUT_DEFAULT);
TServerTransport serverTransport = new TServerSocket(
new TServerSocket.ServerSocketTransportArgs().
bindAddr(new InetSocketAddress(listenAddress, listenPort)).
backlog(backlog).
clientTimeout(readTimeout));
TBoundedThreadPoolServer.Args serverArgs =
new TBoundedThreadPoolServer.Args(serverTransport, conf);
serverArgs.processor(processor)
.transportFactory(transportFactory)
.protocolFactory(protocolFactory);
LOG.info("starting " + ImplType.THREAD_POOL.simpleClassName() + " on "
+ listenAddress + ":" + Integer.toString(listenPort)
+ " with readTimeout " + readTimeout + "ms; " + serverArgs);
TBoundedThreadPoolServer tserver =
new TBoundedThreadPoolServer(serverArgs, metrics);
this.tserver = tserver;
上述的代码,可以看到的就是,获取得到绑定ip,默认是'0.0.0.0',以及基于得到的端口(默认9090),设置的超时时间,设定好对应的TserverTransport,设定好相应的threadpoolserver的参数,然后设置好对应的初始化的server;这里实际上这段代码以及对于thriftserver需要的ip port ,传输的thrift协议都设定好了(threadpoolserve内部也有对应的初始化的线程池),然后serve()方法内部会启动对应的端口绑定以及初始化的线程池的操作,开始接受client的请求,可以理解的thriftserver的服务模型是,单线程的接收客户端的请求,接收到请求,丢给后端的线程池进行操作;
上面大概介绍了默认的情况下,hbase的Thriftserver的启动初始化,的相关操作,大概理顺了一个流程,细节里面的,各个操作的配置哪里去取这些细小的地方,没有描述;
三:thriftserver的调用
前段是thrift的处理,大概是从processer的process方法开始往下查,主要是从HBaseHandler进行观测,比如get请求,落到这里是get操作,我们看下面的代码:
protected List<TCell> get(ByteBuffer tableName,
ByteBuffer row,
byte[] family,
byte[] qualifier,
Map<ByteBuffer, ByteBuffer> attributes) throws IOError {
Table table = null;
try {
table = getTable(tableName);
Get get = new Get(getBytes(row));
addAttributes(get, attributes);
if (qualifier == null) {
get.addFamily(family);
} else {
get.addColumn(family, qualifier);
}
Result result = table.get(get);
return ThriftUtilities.cellFromHBase(result.rawCells());
} catch (IOException e) {
LOG.warn(e.getMessage(), e);
throw getIOError(e);
} finally {
closeTable(table);
}
}
这里往下看的话,实际上就和正常的java api的rpc请求一致了。其他的操作也是类似的。