
我们平时说 AI 回答慢,一般是遇到这两种情况:一个是问题发出去之后,它隔了一会儿才开始回复;另一个是它已经开始回复了,但输出速度很慢,像是一个字一个字往外蹦。
这两种体验都叫“慢”,但在模型推理服务中,它们对应着两个不同阶段。第一个叫 Prefill,就是模型先把你的输入读完;第二个叫 Decode,是模型开始逐步生成回答。
简单说,Prefill 影响的是你多久能看到第一个回复;Decode 影响的是模型开始回答之后,输出速度有多快。
AI 回答分成两步
我们和模型的一次对话,可以粗略拆成两个阶段。先看这张时间轴:
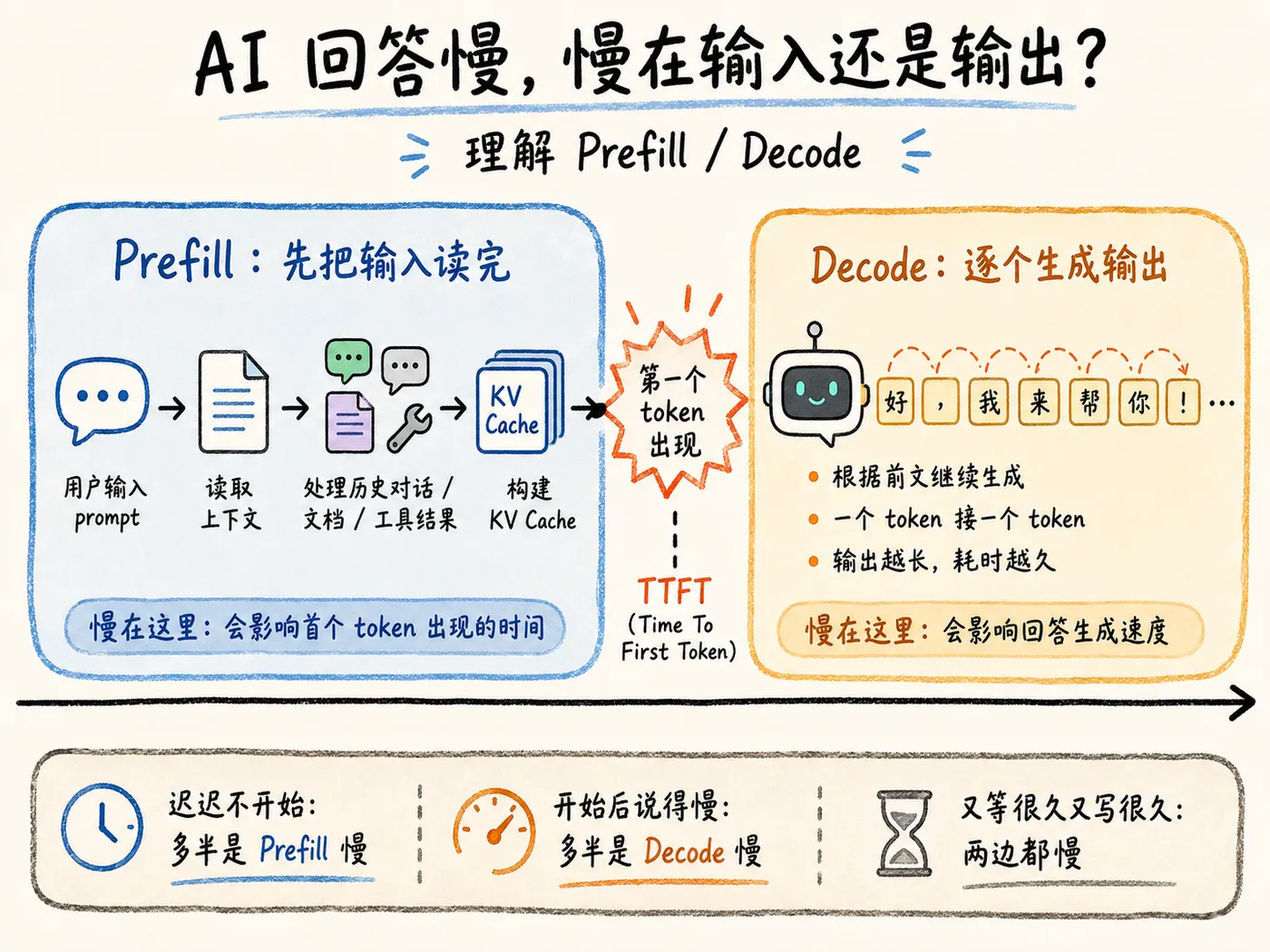
第一个阶段是 Prefill,它有点像“读题”。当你把 prompt 发给模型时,里面可能不只有这一次的问题,还包含了系统提示词、上下文、历史对话、工具返回结果、检索到的文档,甚至是一整段代码或日志。模型要先把这些输入内容处理完,才能准备后面生成回答要用到的中间状态,也就是常说的 KV Cache。
第二个阶段是 Decode,它有点像“写答案”。模型读完输入后,才会开始生成回复。但这个回复通常没法一次性全部生成出来,而是要一个 token 一个 token 往后写。第 10 个 token 的生成,会依赖前面已经生成的 9 个 token;第 100 个 token,也要接着前面 99 个结果继续往后推。
所以,一次请求花了多久,粗略看就是两部分:把前面处理输入的时间,加上后面生成答案的时间。
Prefill 慢是“迟迟不开始”
只要问题发出去,对话界面一直空着,模型迟迟没开始输出。这段时间,一般是模型在处理输入,就是 prefill 阶段。
在 API 指标中,这段等待时间常用 TTFT 来衡量。TTFT 的全称是 Time To First Token,是从请求发出,到第一个 token 出现之前所消耗的时间。
如果你发给模型的 prompt 很长,Prefill 阶段就会被拉长。像是让模型读一整篇论文、分析一个代码仓库、总结一大段会议记录,或者是 Agent 把大量工具调用结果和历史轨迹都塞进上下文里,模型都要先把这些输入处理完,才会进入生成回答的阶段。
这就是为什么有时候你只让 AI 回答一句话,它会让你等很久。因为慢点不在回答的难易,而在于你给的输入太长。模型在真正开口之前,得花时间把上下文读完了。
Prefill 还有一个特点,在这个阶段模型已经接收了完整的输入,可以把一批 token 放在一起处理,也就比较容易把 GPU 算力用起来。但上下文越长,开口前要读、要算的内容就越多,长 prompt 带来的前置成本会明显增加。
因此,很多推理优化都会盯着 Prefill 阶段做文章,参考:prompt caching、prefix caching、chunked prefill。它们要解决的问题是让模型少读重复内容,以及更稳地拆超长输入。
Decode 慢是“说得很慢”
Decode 对应的是另一种慢:模型开始回复了,但输出速度很慢。这时候你会看到它一个 token 一个 token 往外生成。短回答通常还好,但如果你让它写长文、写代码,或者生成一份完整分析报告,Decode 阶段的时间就会明显变长。
原因在于模型生成回答本身是一个顺序过程。它没法直接跳到最后一句,也没法一次性把整篇内容全部算完。前一个 token 生成出来之后,后一个 token 才能接着往下生成。
所以,Decode 阶段的耗时和输出长度有关系。让模型回答 50 个 token,和让它回答 2000 个 token,体验一定不一样。因此,即使输入很短,只要输出很长,总处理时间也会被拉长。
在 API 指标中,Decode 常常会对应 TPS,也就是 tokens per second,表示模型每秒能生成多少 token。用户看到的模型“打字速度”,和这个指标有关。
两种不同的慢
理解 Prefill 和 Decode 之后,我们就能清楚地判断一次 AI 请求到底慢在哪了。
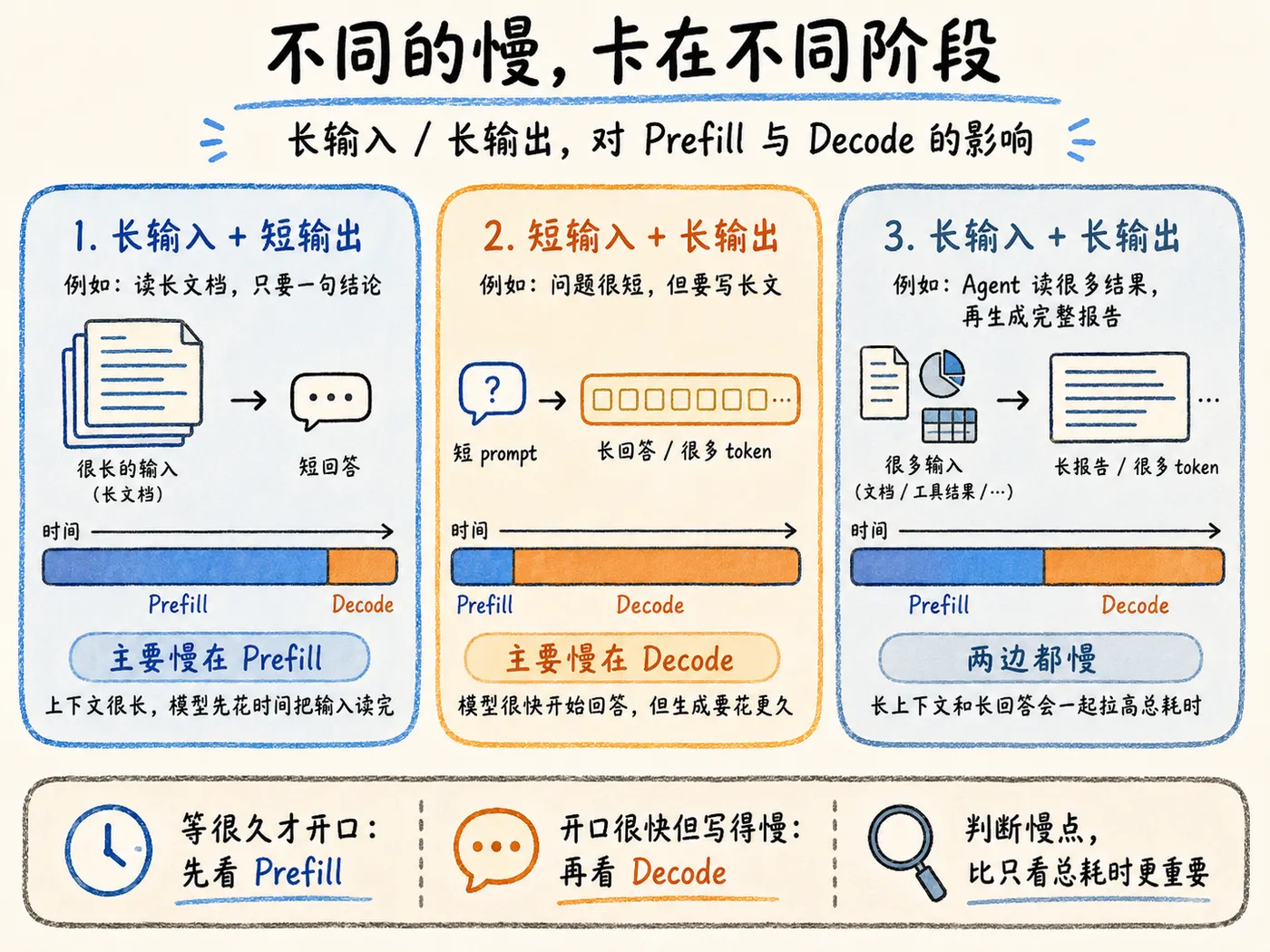
如果你给了很长的上下文,但只需要一个很短的答案,慢点通常更偏向 Prefill。
举个例子,“请根据这份 10 万字资料,告诉我里面有没有提到项目 A。”这种请求可能要等模型一会,它才会开始输出。但一旦模型开始回答,回复的内容就会很快结束。因为它真正耗时的地方,是模型在开口前要处理大量输入。
反之,你的问题很短,但让模型生成的回复很长,慢点会偏向 Decode。
举个例子,“帮我写一篇 30,000 字文章。”这种请求可能很快就开始输出,但完成生成会花很多时间。因为模型要沿着前面的内容,一个 token 一个 token 往后生成,输出越长,Decode 阶段拖得越久。
其实,还有一种情况是两边都慢。
举个例子,你让 Agent 读取大量工具调用结果,再生成一份完整报告。前面的长输入会增加 Prefill 压力,后面的长报告又会拉长 Decode 时间。这就是为什么很多 Agent 任务看起来比普通聊天更慢。因为它的上下文更长,要处理的步骤更多,最后还要给出更完整的回答。
长上下文让事情慢上加慢
现在很多模型都在强调长上下文,几十万 token、上百万 token 的上下文窗口不再稀奇。但上下文变长,并不代表模型读取这些内容是免费的。
上下文越长,Prefill 阶段要处理的输入就越多,生成出来的 KV Cache 也就越大。KV Cache 本身会占用显存,后续进入 Decode 阶段时,模型每生成一个新 token,也还要不断利用这些缓存。因此,长上下文带来的影响不只发生在输入阶段,也会延续到输出阶段。
所以,在实际工程中,通常不会把所有内容一股脑塞进 prompt。无论是 RAG、上下文压缩、记忆筛选,还是工具结果清理,其重点都是控制模型每次要读取的内容,减少不必要的输入和缓存负担。
对 Agent 来说,这一点尤其关键。如果每一步都带上完整历史、所有工具返回和全部中间过程,模型看起来拿到的信息是多了,但延迟和成本跟着上升了。比较合理的做法,是保留必要上下文,把可复用、可缓存、可摘要的内容整理好,让模型少读冗余信息。
只改善“开始速度”的优化
有些优化可以让模型更快地开始回答,但对后续的输出速度帮助有限。
prompt caching 就是这种。如果一段系统提示词、工具说明或固定模板经常重复出现,服务端就可以复用之前处理过的前缀,减少 Prefill 阶段的重复计算。这样一来,模型开口前的等待时间会缩短,首个 token 也会更快出现。
不过,模型进入 Decode 阶段之后,仍然需要一个 token 一个 token 往外生成。缓存可以减少“读题”的重复成本,但不能让一篇长回答瞬间生成完。
所以,当你看到某个模型或服务强调“缓存命中后延迟降低”时,要看它主要在优化哪个阶段。很多时候,它改善的是 TTFT,就是模型开始输出前的等待时间。
要想提高输出阶段的速度,就涉及另一种优化:speculative decoding、批处理调度、KV Cache 管理、模型结构优化和推理引擎优化。这些优化关注的是 Decode 阶段,目标是让模型更高效地生成 token。
一个简单判断方法
简单判断就看一点:AI 是迟迟不开口,还是开口之后写得慢。
如果很久没有开始回复,问题多半出在 Prefill,也就是模型还在处理输入;如果开始回复很快,但后面生成很慢,问题多半出在 Decode,模型还在逐步生成输出。前者更接近 TTFT,看的是多久出现第一个 token;后者更接近 TPS,看的是开始输出后每秒能生成多少 token。
所以,“AI 回答慢”要先拆开看:慢在输入,还是慢在输出。下一次看到 AI 卡住时,先看它卡在哪一段,就能大致判断背后的原因。







