


大模型时代的下半场,AI Agent(智能体)的瓶颈正在从“推理算力”转向“上下文供给”。
在企业落地场景中,知识散落在 Wiki、代码注释、API 文档与共享网盘中。传统的 RAG(检索增强生成)频繁面临“切片噪声大、拼凑上下文易出错”的困境。本质上,这不是大模型不够聪明,而是知识供给侧缺乏一套面向 AI 的“标准化知识接口”。
为此,Google Cloud 发布了 Open Knowledge Format (OKF v0.1) 规范(位于 knowledge-catalog 仓库的 okf/SPEC.md)。而在两个月前,前 OpenAI 科学家 Andrej Karpathy 刚刚提出了 LLM Wiki 概念。这两大风向的交汇,标志着 AI 知识资产治理正式进入标准化深水区。
深度解构 OKF:专为 Agent 设计的“知识包装规范”
OKF(Open Knowledge Format)不是一个需要安装的重型软件,也不是一个复杂的运行库(SDK),而是一个极简的、人类与 AI 共同可读的“知识包装规范”。
它倡导一种“去中心化、原子化”的知识管理方式:将复杂的知识点打碎成一个个独立的 Markdown 文件(称为 Concept,概念),并组织在一个文件夹(称为 Bundle,知识包)中。
站在技术架构的角度,OKF 实现了三个极简结构:
Just Markdown(纯文本主体):主体基于标准的 Markdown。规范鼓励使用 Heading(标题)、Table(表格)、Code Block(代码块)等强结构化排版,因为这种天然的“语法锚点”能极大地帮助 AI Agent 准确提取语义。
Just YAML Frontmatter(元数据索引卡片):每个 Markdown 文件的顶部都有一段 YAML 格式的元数据,就像图书馆的索引卡片:
唯一必填项:type(定义该概念的资产属性,如 Metric 指标、Table 数据库表、Runbook 运维手册)。
高频推荐项:title(标题)、description(描述)、resource(指向实体资产的 URI 链接,如 BigQuery 链接)、tags(标签)。
Reserved Files(保留系统文件):
index.md(动态目录):支持 渐进式披露(Progressive Disclosure) 机制。Agent 检索时可以先阅读目录了解全局,再精准打开相关文件,有效避免一次性加载成百上千个文档导致的“中间迷失”与高昂的 Token 成本。
log.md(审计日志):记录知识包的版本变更历史。
OKF 样例文件示范: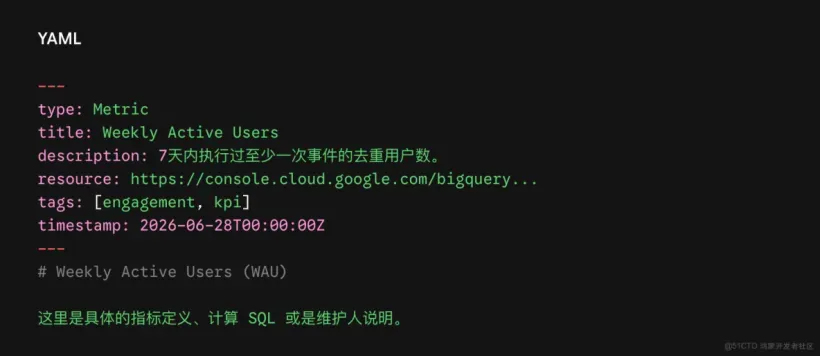
OKF 采用了极其务实的容错消费模型 (Permissive Consumption Model)。规范指出,Agent 不能因为文件缺少可选字段或存在失效的交叉链接而拒绝解析。即便格式不够严谨,Agent 也应当将其退化为通用文档继续读取,极大地降低了数据生产者的门槛。
双雄并立:OKF 与 Karpathy 的 LLM Wiki 深度对比
在 OKF 发布的两个月前,Karpathy 提出了 LLM Wiki 概念,核心理念是 “先编译,后查询”(Compile-first, instead of RAG)。
传统 RAG 是临时从海量碎片中检索切片喂给大模型,知识无法在系统内部沉淀和有机演进。而 LLM Wiki 提倡新资料进来时,先让 LLM 将其“编译”成一个由 Markdown 构成、相互链接的本地知识图谱(如 Obsidian),形成 输入 -> 查询 -> 结构性体检(Lint) 的自主进化闭环。
从底层技术谱系来看,Google 的 OKF 本质上是对 Karpathy 的 LLM Wiki 中“媒介层”的一种工业化与标准化落地。
CTO 视角的技术资产启示:大模型时代的“文本返祖”
无论是 Karpathy 掀起的 LLM Wiki 风潮,还是 Google 迅速跟进标准化的 OKF,都揭示了 AI 时代知识形态的重大转变:知识正在向“对机器友好,对人类透明”的方向演进。
知识即代码 (Knowledge as Code):过去我们把企业资产锁在 Confluence 或专有数据库中。OKF 告诉我们,未来最好的知识形态,就是用 Git 进行版本控制的纯文本(Markdown)。它可以无缝进入 CI/CD 管道,合并、Diff、代码审查等成熟的软件工程工具链全部可以平移过来。
事前治理(KAG)将彻底颠覆事后缝补(RAG):单纯靠向量数据库把垃圾资产切片,然后寄希望于大模型在提问时去大海捞针的“粗暴 RAG”路子越来越窄了。未来的趋势一定是利用大模型或自动化流水线,在输入端将技术、业务资产“编译、重构”成标准 OKF 格式的知识图谱。
“机器可读性”成为衡量技术债的新指标:未来评估一个系统的架构好坏,不仅要看高并发、低延迟,更要看它的机器可读性(Machine-readable)。谁能率先把企业内部那些隐性知识转化为满足 OKF 标准的显性数字资产,谁就能在 AI-native 的研发管理中占据绝对的先发优势。
如果说 OpenAPI 统一了 AI 智能体调用工具(Tools)的接口,那么 OKF 与 LLM Wiki 正在尝试统一 AI 智能体获取知识(Knowledge)的接口。对于技术负责人和开发者而言,及早布局标准化的文本知识组织方式,将是构建下一代高表现力 Agent 的核心护城河。

