
尼恩说在前面
在45岁老架构师尼恩的读者交流群(50+人)里,最近不少小伙伴拿到了阿里、滴滴、极兔、有赞、希音、百度、字节、网易、美团这些一线大厂的面试入场券,恭喜各位!
前两天就有个小伙伴面腾讯, 问到 “ 听说过 自主协调 Agent 吗?你们 的Agent 都是固定编排 的? ”的场景题 ,小伙伴没有一点概念,导致面试挂了。
小伙伴 没有看过系统化的 答案,回答也不全面 ,so, 面试官不满意 , 面试挂了。
小伙伴找尼恩复盘, 求助尼恩。
通过这个 文章, 这里 尼恩给大家做一下 系统化、体系化的梳理,写一个系列的文章组成 尼恩编著 《Harness 架构与源码 学习圣经》 深入剖析 Harness AI 平台级 架构的 架构思维与 核心源码,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
同时,也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典PDF》V176版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
尼恩编著 《 分布式 “自主协调” 多智能体范式 AG2 学习圣经》
下面是尼恩团队的 AG2 学习圣经系列电子书, pdf可以找尼恩免费获取
【尼恩 AG2 圣经 第 1 章】分布式自主协调 框架全景认知: AG2 是什么、为什么、怎么跑.pdf
【尼恩 AG2 圣经 第 2 章】分布式自主协调 之 最小对话:两 Agent 的一次完整交互.pdf
【尼恩 AG2 圣经 第 3 章】分布式自主协调 之 回复引擎: ConversableAgent 的决策机制.pdf
【尼恩 AG2 圣经 第 4 章】分布式自主协调 对话控制:人类何时介入、对话何时终止.pdf
【尼恩 AG2 圣经 第 5 章】工具调用:让 Agent 连接外部世界.pdf
【尼恩 AG2 圣经 第 6 章】分布式自主协调 之 群聊协作:多 Agent 的发言秩序.pdf
【尼恩 AG2 圣经 第 7 章】分布式自主协调 之 对话编排:流水线编排 vs 嵌套编排 的两大对话编排方式详解.pdf
【尼恩 AG2 圣经 第 8 章】 Agent 与 LLM 集成:基础设施层配置、容错配置与多模态数据封装.pdf
【尼恩 AG2 圣经 第 9 章】 记忆与上下文:长对话的精简之道.pdf
【尼恩 AG2 圣经 第 10 章】 Actor 模型:事件驱动与分布式.pdf
本文依托 10 份 【尼恩团队的 AG2 学习圣经 】技术文档,从项目起源、分层架构、核心组件、通信协议 A2A、各模块底层原理、落地选型、实战场景多维度展开,细致拆解AG2 框架整体架构以及A2A(Agent-to-Agent)智能体通信协议和 AG2 的深度绑定关系。
本文 完整关联 尼恩 AG2 圣经 1~10章系统知识点, 对 分布式 “自主协调” 多智能体 框架 AG2 深度详解。
本文的基础知识:
A2A 的基础知识,请参考尼恩的《 A2A 学习圣经 系列pdf》
前言:新一代Agent范式: 分布式 “自主协调” 多智能体范式
尼恩 基于完整 AG2 全栈体系、A2A 通信规范、Actor 异步内核、AG2 与 LangChain/LangGraph 生态差异,归纳出 + 凝练出 AG2 新一代分布式核心范式:自主协调多智能体 范式 。
区别于传统「人工硬编码流程、固定节点编排」的旧式智能体开发模式,是面向企业级 SaaS、高并发、开放式 AI 集群的新一代 Agent 协调的 工程范式。

1、分布式 自主协调 范式本质:从 人工编排 -》升级为 自主协调/自主涌现协作
传统 LangChain+LangGraph 范式属于 开发者驱动的确定性图编排:业务流程、节点流转、角色分工全部由人工硬编码定义,Agent 仅作为执行工具,无自主决策、无动态协商能力,适合固定流水线,但无法适配开放式、动态化、多人评审、自主决策的 AI 场景。
AG2 多智能体新范式核心:对话即计算、事件即驱动、通信即协作。不依赖人工写死流程,通过标准化 A2A 通信 + Actor 异步消息驱动,让多智能体根据任务上下文、角色定位、事件触发规则 自主协商、自主选责、自主流转、自主并行、自主容灾,真正实现 AI 驱动业务流程涌现,而非代码驱动流程。
2、 “自主协调” 范式 三大核心特征: 分布式 + 自主协调 + 多智能体

2.1. 多智能体:去中心化角色协作,流程动态涌现
AG2 彻底摒弃传统固定节点硬编码模式,依托 agentchat GroupChat 与 autogen-core 事件路由实现开放式多角色协作:
角色热插拔:新增专家 Agent 仅需加入集群/群聊列表,无需修改任何流转代码、无需配置节点边关系,极大降低迭代成本;
自主发言人决策:支持轮询、随机、AI 智能选型三种模式,针对头脑风暴、方案评审、多方辩论等不确定场景,由 LLM 动态判断最优执行角色;
分层协作体系:简单一对一任务依赖 Assistant/UserProxy 乒乓对话,复杂多角色业务依赖群聊中心化调度,高并发业务依赖事件广播并行协作,全覆盖多粒度场景。
2.2. 自主协调:基于 A2A 协议的无代码动态协同
自主协调是 AG2 范式的核心竞争力,完全依托标准化 A2A 跨智能体通信协议实现,区别于传统框架的内存硬引用、自定义私有消息格式:
统一通信标准:A2A 作为行业通用智能体协议,统一消息格式、寻址规则、异常处理,支撑单机对话、群聊广播、跨机通信全场景;
双模式自主协同:点对点 RPC-A2A 完成精准任务委派、权限隔离(思考/执行分离),Pub/Sub 广播 A2A 完成事件扇出、多任务并行;
无侵入协调:无需人工定义任务依赖,上游事件自动触发下游订阅 Agent 执行,模块完全解耦,实现「新增业务只加订阅、不改存量代码」的工程架构。

2.3. 分布式架构:全异步 Actor 内核,企业级集群能力
AG2 基于经典 Actor 理论构建 autogen-core 全异步内核,是支撑大规模多智能体集群的底层基石,彻底突破单机性能与部署限制:
全异步事件驱动:摒弃同步函数调用,所有 Agent 行为仅由入站消息触发,无阻塞、无轮询,单 Agent 支持多消息并行处理,资源利用率远超同步框架;
一套代码双环境适配:业务代码无需修改,替换 Runtime 即可在单机调试、Grpc 分布式集群之间无缝切换;
多租户集群原生支持:依托 AgentId/TopicId 全局寻址、租户事件隔离、gRPC 跨机通信,天然支撑 SaaS 多租户、弹性扩缩容、单点故障隔离;
异构生态互通:基于标准 A2A 协议,可与 LangChain、谷歌 Vertex 等第三方智能体跨框架、跨机器协同。

3、新旧智能体范式核心对比
| 维度 | 传统范式(LangChain+LangGraph) | AG2 分布式自主多智能体范式 |
|---|---|---|
| 流程驱动 | 人工硬编码 DAG 固定流程 | 消息/事件驱动,流程自主涌现、自主协调 |
| 多Agent协作 | 手动拆分节点、配置流转边,迭代成本高 | 角色热插拔,AI 自主调度协作 |
| 通信能力 | 框架私有链路,不支持跨机跨框架 | 标准 A2A 协议,分布式、异构互通 |
| 运行模型 | 同步链式/状态机调度 | 全异步 Actor 事件驱动,高并发并行 |
| 部署形态 | 仅限单机,无原生分布式 | 单机/集群一键切换,SaaS 多租户原生支持 |
| 适用场景 | 固定流程、断点审批、标准化 RAG | 开放式协作、事件并行、企业级分布式 AI |
AG2 分布式自主协调多智能体范式,是面向生产级、企业级 AI 应用的新一代开发标准:以 A2A 标准化通信为底座、Actor 全异步事件为驱动、多智能体自主协商为核心、分布式集群部署为能力上限,彻底解决传统智能体框架流程僵化、协作能力弱、无法分布式扩容、多租户隔离缺失的痛点。
其本质是:简单业务快速落地、复杂业务自主协同、大规模业务分布式扩容,实现从「人工定义 AI 流程」到「AI 自主驱动业务」的范式升级。

一、基础总览:AG2 项目由来与双层整体架构
1. AG2 项目发展背景
2023 年微软发布 AutoGen 框架,凭借对话式多智能体设计迅速成为业界标杆,但 2024 年末微软开发团队与社区开发者在技术路线上出现严重分歧:微软选择舍弃原有 0.2 同步对话架构,基于 Actor 模型从零重构 AutoGen0.4 新版本,API 全量不兼容;社区核心维护者分叉原有稳定 0.2 代码,迭代出AG2(ag2)社区版,保持 100% 向下兼容 AutoGen0.2 原有代码,用户仅需修改安装指令pip install ag2,原有import autogen代码无需改动即可无缝迁移。
二者路线分化:
- 微软新版 AutoGen0.4: 全新架构、全异步 Actor、强类型消息,学习成本高,存量项目迁移成本巨大;
- AG 社区版: 保留成熟 agentchat 对话 API,在原有架构基础上新增 autogen-core 分布式内核、A2A 标准化通信、MCP 远程工具、全链路可观测等企业级能力,兼顾易用性与生产分布式能力,也是文档整套讲解的核心主体。
2. AG2 双层整体架构
AG2 采用上层应用层 + 底层内核引擎的分层解耦架构,遵循软件工程分层设计思想,两大模块共享 Runtime 运行时接口,实现业务代码一套、运行环境自由切换。

【1】上层 agent 对话层(agentchat): 面向开发者快速落地业务,主打同步对话、低学习门槛,核心基类ConversableAgent衍生 AssistantAgent、UserProxyAgent、GroupChatManager 等常用智能体,使用字典格式消息、点对点硬编码实例引用通信,适配单机原型、中小型项目,覆盖 80% 常规业务场景。
【2】底层内核层(autogen-core): 基于经典 Carl Hewitt Actor 理论 + Erlang 工业落地思想开发,全异步事件驱动,采用 dataclass 强类型结构化消息、全局 AgentId/TopicId 寻址、RPC+PubSub 双通信原语,支持单机 / 分布式两套 Runtime 无缝切换,面向分布式集群、百万 Agent 动态扩缩、事件流式编排等 20% 复杂生产场景。
A2A 与 agentchat 的关系:
- A2A(Agent-to-Agent)智能体通信协议定义:AG2 社区使用了 标准化 A2A 协议,全称 Agent-to-Agent,统一规范不同智能体、不同进程、不同服务器之间的消息格式、寻址规则、传输方式、异常处理逻辑,
- agentchat 隐式依赖 A2A 基础规范完成消息收发,autogen-core 原生以 A2A 作为底层通信底座,是 AG 区别于旧版 AutoGen 最关键的新增企业级能力。
二、AG2 与 A2A 全维度深度关联
A2A 是独立第三方协议,也是深度内嵌在 AG2 通信标准中,从上层对话到下层分布式内核,所有 Agent 消息交互全部遵循 A2A 约束,分应用层落地、内核落地、落地场景、新旧版本差异四大模块详细说明。
1. A2A 标准官方出身:谷歌发起,Linux 基金会中立托管
A2A 协议完整溯源:谷歌主导、Linux 基金会托管(纠正概念:分外部标准 A2A、AG 内部封装 A2A 实现)
Agent-to-Agent (A2A) v1.0 正式协议由 Google 在 2025 年 4 月正式对外发布,同年 6 月捐赠至 Linux 基金会,由跨厂商技术委员会(TSC)统一治理,属于开放中立的 AI 智能体互联行业标准,并非 AG2 自研私有协议。
项目发展时间线
- 2025.04: Google Cloud 首发 A2A 草案,定位 AI 领域的「TCP/IP 协议」,解决不同厂商、不同框架 Agent 孤岛问题,对标 MCP(Model Context Protocol)工具协议:MCP 解决 Agent 调用外部工具,A2A 解决 Agent 之间跨框架通信;
- 2025.06: 谷歌将 A2A 规范完整捐赠 Linux 基金会,开放标准版权,无厂商锁定,首批合作方包含 AG2、LangChain、CrewAI、Google Vertex、Anthropic 等 50 + 智能体生态厂商;
- 2026.03: A2A v1.0 正式生产版定稿,成为全球智能体跨交互通用规范,AG2 同步完成全栈原生适配,是最早落地商用的框架之一。
A2A 协议五大原生标准能力(谷歌官方定义)
| 能力项 | 官方标准说明 | AG2 落地实现形式 |
|---|---|---|
| Agent 能力发现(Agent Card) | 标准化元数据卡片,描述 Agent 名称、能力、接口、协议版本,实现自动寻址发现 | AG2 AgentId绑定 AgentCard 元数据,注册 Runtime 时自动上报能力信息 |
| 结构化任务委派 | 支持同步 RPC、异步延迟任务、流式分段消息三种交互范式 | send_message(RPC)/publish_message(广播)双原语分别落地两种模式 |
| 多轮会话规范 | 统一多轮对话消息格式、上下文携带规则 | dataclass 强类型消息封装,自动绑定会话source字段 |
| 实时推送通知 | SSE 长连接异步事件推送 | Topic 订阅 + 事件扇出,长耗时任务状态广播 |
| 企业级安全鉴权 | OAuth2、自定义身份认证、消息加密规范 | 分布式 Grpc Runtime 内置传输加密、接入鉴权中间件 |
2. 标准 A2A 与 AG2 内部A2A区分
【1】外部: 行业标准 A2A(谷歌 / Linux 基金会出品,跨框架通用):跨厂商通用通信协议,AG2、LangChain、谷歌 Vertex、CrewAI 的 Agent 可以跨进程 / 跨机器通过该协议互通,解决异构智能体互联互通,是生态级标准;【2】内部:AG2 框架内置 A2A 通信实现:AG2 基于谷歌 A2A 标准做框架内部封装实现,agentchat层、autogen-core层所有 Agent 收发消息均遵循 A2A 协议规范,是 A2A 标准在 AG 的具体落地,前文提到的点对点、PubSub 通信本质都是遵循 A2A 规范的框架内部实现。
简单概括:A2A 标准由谷歌制定,AG2 是落地实现方之一;AG 内部 A2A 通信逻辑 = 谷歌 A2A 规范的工程化落地。
3. agentchat 上层中 A2A 落地实现
agentchat 虽使用简易字典消息,但其点对点initiate_chat发起对话、群聊广播的底层消息流转逻辑,全部遵循 A2A 基础通信范式:
【1】点对点、一对一 A2A 通信: 两个 Agent 通过initiate_chat发起乒乓式对话,Assistant 发消息→UserProxy 接收执行,消息从发送方流转至接收方的过程,本质是同步型 A2A 点对点通信,也是日常开发最频繁的 A2A 使用场景,经典助手 + 执行者协作模型完全基于该模式。
【2】GroupChat 群聊 A2A 广播通信: 群聊采用中心化星型架构,所有消息必须经由 GroupChatManager 中转,发言人消息统一发送给 Manager,再由 Manager 通过 A2A 协议全群广播给所有参与者,非发言人收到消息仅存入上下文、不自动回复(request_reply=False),实现一对多 A2A 消息分发。
【3】跨角色工具调用 A2A 通信: Caller(LLM 决策 Agent)生成 tool_calls 工具调用消息,通过 A2A 协议发送给 Executor 执行 Agent,执行结果再经由 A2A 原路回传,是工具分离架构的通信根基。
4. autogen-core 底层 A2A 标准化落地(生产分布式核心)
autogen 作为 Actor 内核,整套通信体系完全基于标准化 A2A 协议构建,依托两套 A2A 通信原语 + 两套全局寻址 ID,分化出同步 RPC-A2A、异步 Pub/Sub-A2A 两种通信形态。
(1)双 A2A 通信原语
【1】send_message: RPC 式 A2A 通信依托AgentId精准寻址单个 Agent 实例,属于同步阻塞 A2A 通信,调用方发送消息后协程挂起等待对方返回结果,对应 gRPC 同步调用场景,适用工具调用、双人协商、需要结果反馈的串行任务,是一对一精准 A2A。【2】publish_message:Pub/Sub 广播式 A2A 通信
依托TopicId事件主题寻址,属于异步非阻塞 A2A 通信,发布方推送消息后立刻结束,由 Runtime 根据订阅关系自动扇出分发给所有订阅 Agent,发布方无需等待任意接收方结果,适配多 Agent 并行处理、日志上报、事件触发等场景,是一对多广播 A2A。
(2)A2A 配套全局寻址体系
A2A 通信依赖两套全局唯一 ID 完成目标定位,全集群单机、跨机器通用:
- AgentId:
type+key二元结构,type 代表 Agent 类型,key 代表实例编号,用于 RPC-A2A 点对点精准定位单个智能体; - TopicId:
type+source二元结构,type 代表事件分类,source 代表会话 / 租户标识,用于 Pub/Sub-A2A 主题寻址,天然实现多租户、多会话数据隔离。
(3)订阅机制支撑 A2A 路由
TypeSubscription 精确订阅、TypePrefixSubscription 前缀订阅作为 A2A 消息路由规则,Runtime 收到 A2A 发布消息后,匹配订阅规则自动映射目标 AgentId,完成消息自动分发,实现事件驱动 A2A 流转,支撑事件链、扇出并行两大高级架构。
4. A2A 四大落地业务场景
【1】双 Agent 基础协作: 思考型 Assistant 与执行型 UserProxy 依靠点对点 A2A 来回传递需求、代码、运行结果,构成 AG 最基础自动化工作流;
【2】工具调用隔离架构: 决策端 Caller 与执行端 Executor 跨角色通过 A2A 通信,实现 LLM 决策和代码 / 工具执行权限物理隔离,满足最小权限安全规范;
【3】事件驱动流水线: 上游 Agent 处理完成后发布 A2A 事件,下游多个订阅 Agent 并行消费,依靠 Pub/Sub-A2A 实现无硬编码流式任务;
【4】跨服务器分布式集群: autogen 的 GrpcWorker 分布式 Runtime 基于 gRPC+A2A 协议,Host 中心节点管控路由,多台机器上的 Worker 节点依托标准化 A2A 跨机器收发消息,突破单机硬件资源上限。
5. 新旧版本 A2A 演进差异
【1】老版 AutoGen0.2: 无标准化 A2A 协议,消息是自定义 Python 字典,Agent 交互依赖内存实例硬引用,无法跨进程、跨机器,无统一消息校验规则,字段写错极易线上报错;
【2】AG2 社区版: 原生落地完整 A2A 通信规范,上层 agentchat 隐性封装简化调用,底层 autogen-core 强约束消息格式、寻址规则,从单机到分布式全链路统一通信标准,也是 AG 面向商业化 SaaS 多租户平台的核心升级。
三、autogen-core 全异步 Actor 模型:理论 + 底层架构 + 分层落地(大幅扩充全异步细节)

3.1 Actor 基础理论溯源(Carl Hewitt 1973 原理论 + Erlang 工业落地)
autogen-core 的全异步 Actor 基于经典 Actor 数学模型三大铁律,同时结合 Erlang OTP 分布式实践、云原生 CloudEvents 规范做 AI 场景定制,三大原生准则:
【1】状态私有隔离: 每个 Actor(RoutedAgent/BaseAgent)独占私有内存状态,外部无法直接读写,仅能通过外部传入消息变更内部数据,彻底规避多线程共享内存竞态问题(Python GIL 瓶颈完美解决);
【2】消息唯一驱动: Actor 无主动循环执行逻辑,所有业务动作仅靠入站消息触发,无主动轮询、无后台死循环,天然全异步;
【3】异步消息通信: Actor 之间无直接内存函数调用,所有交互全靠消息投递,进程 / 机器隔离也不改变交互逻辑,是分布式的底层根基。
区别:普通同步框架(agentchat)是函数调用驱动;autogen-core 全异步 Actor 是事件消息驱动,所有执行被动由消息触发,这是同步 / 异步最本质分界线。
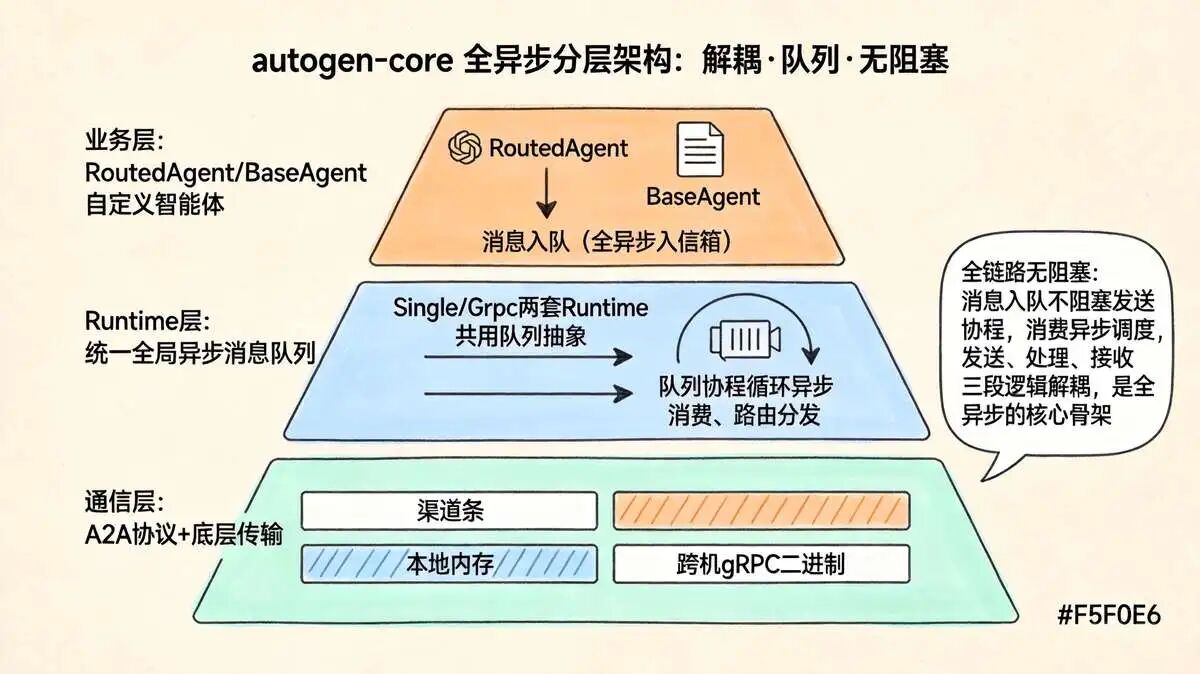
3.2 autogen-core 全异步整体分层架构
```Plain Text
【业务层:RoutedAgent/BaseAgent 自定义智能体】
↓ 消息入队(全异步入信箱)
【Runtime层:统一全局异步消息队列】(Single/Grpc两套Runtime共用队列抽象)
↓ 队列协程循环异步消费、路由分发
【通信层:A2A协议+底层传输】(本地内存/跨机gRPC二进制)
全链路无阻塞:消息入队不阻塞发送协程,消费异步调度,发送、处理、接收三段逻辑解耦,是全异步的核心骨架。
### 3.3 三层全异步落地细节(消息层→Agent 层→Runtime 调度层)
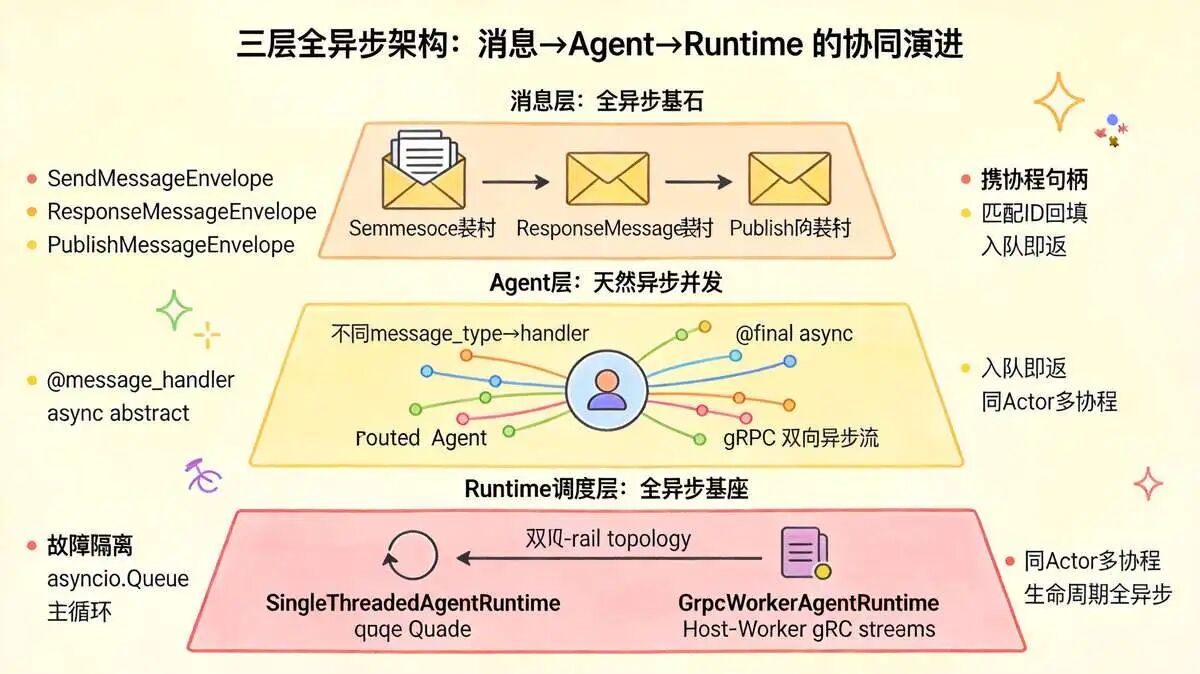
#### 1)消息层:强类型消息 + 异步信封封装(全异步基石)
autogen 全部消息基于`dataclass`定义,遵循 A2A 消息规范,Runtime 内部统一封装三类异步消息信封:
- **SendMessageEnvelope(RPC 请求信封,A2A 同步):** 携带请求协程句柄,收到结果后异步唤醒阻塞协程;
- **ResponseMessageEnvelope(RPC 返回信封,异步回调):** Runtime 匹配原始请求 ID,异步回填数据、解除等待;
- **PublishMessageEnvelope(广播信封,A2A 异步):** 无等待回调,入队后立刻返回,Runtime 后台异步扇出分发。
> 全信封入队全部使用 asyncio 异步 IO,无同步阻塞代码,从消息源头实现全异步。
>
#### 2)Agent 层:BaseAgent/RoutedAgent 全异步实现
**【1】BaseAgent:** 顶层抽象 Actor
- **`on_message(@final async)`:** 框架统一异步入口,final 禁止重写,内部统一日志、异常埋点、上下文注入;
- **`on_message_impl(async abstract)`:** 子类实现异步业务逻辑,**所有处理逻辑强制 async 函数**,天然支持异步 IO(联网、LLM 异步调用、数据库 IO);
- `send_message/publish_message`全是 async 方法,调用时仅把消息封装入 Runtime 异步队列,自身立刻释放协程,不阻塞当前 Agent 执行,实现发送方全异步。
**【2】RoutedAgent:** 带消息路由的增强 Actor
依托`@message_handler`装饰器 + 运行时反射,启动时预生成「消息类型→异步处理函数」路由表;消息抵达 Runtime 异步投递后,自动匹配对应 async 处理方法,不同消息并行调度协程,同一 Agent 不同类型消息可异步并发处理(同 Actor 内部多协程,突破单任务串行限制)。
> 重点:**同一个 RoutedAgent 收到多条不同类型消息,可异步并行执行多个 handler,这是全异步带来的并发收益,agentchat 同步架构完全做不到**。
>
#### 3)Runtime 调度层:两套全异步运行时实现
##### 3.1) SingleThreadedAgentRuntime(本地全异步,asyncio 原生实现)
【1】内部维护**单协程异步消息队列(asyncio.Queue)**,全局唯一消息缓冲池,所有 RPC、广播消息统一入队;
**【2】后台常驻一个异步消费主循环`async run()`,循环从队列取出信封、区分类型分发:**
- **RPC:** 异步寻址 Agent、调用 Agent 的 async on_message,结果异步原路回调;
- **广播:** 遍历订阅表,批量异步推送至目标 Agent 信箱;
**【3】生命周期全异步:** `start()`启动异步循环、`stop_when_idle()`异步等待队列清空再退出,无 sleep、无阻塞等待。
**【4】拦截器 Intervention 全异步:** 消息入站前后异步执行日志、鉴权、过滤钩子,中间件链路全异步串联。
##### 3.2) GrpcWorkerAgentRuntime(分布式全异步,Host+Worker 主从)
**全链路基于 gRPC 双向异步流 + Protobuf 二进制 + A2A 协议,全异步跨机器通信**:
**【1】Host 节点(中心调度,全异步路由):**
- 异步维护全集群 Agent 注册表、订阅注册表(可对接 etcd 异步注册中心);
- 所有跨机器消息通过 gRPC 双向异步流下发对应 Worker,发送协程入队后立刻返回,后台异步传输;
**【2】Worker 节点(业务执行,全异步 Agent 容器):**
- 每个 Worker 和 Host 维持一条 gRPC 长异步流,消息收发全非阻塞;
Worker 内部复用 SingleThread 的异步消息队列,本地 Agent 全异步处理入站 A2A 消息;
**【3】分布式全异步优势:** 一台 Worker 宕机不阻塞全集群消息流转,Host 异步重路由消息至其他可用实例,天然故障隔离。
### 3.4 全异步 Actor 两大通信原语(结合 A2A 标准再细化)
#### 1. send_message(A2A 同步 RPC,异步等待)
```python
# 伪全异步执行链路
async def send_message(msg, aid):
1. 封装A2A标准RPC消息信封,注册当前等待协程
2. 信封异步入Runtime队列,函数让出CPU(不阻塞)
3. Runtime异步寻址投递目标Agent
4. 目标Agent异步处理on_message_impl
5. 结果异步封装返回信封,Runtime唤醒原协程
表面同步等待、底层全异步调度:用户代码res=await send_message()看似等待,实际协程挂起让出事件循环,Runtime 可以调度其他 Agent 任务,无 CPU 空等,高并发下资源利用率远高于同步阻塞。
2. publish_message(A2A 异步广播,即发即走)
async def publish_message(msg, tid):
1. 封装A2A广播信封
2. 异步入队,方法立刻return
3. Runtime后台异步遍历订阅列表,逐个投递Agent信箱
发布方完全零等待,消息分发全在 Runtime 后台协程执行,实现经典扇出(Fan-out):一条 A2A 事件,异步触发 N 个 Agent 并行处理,是事件驱动流水线核心底层。
3.5 全异步 Actor 五大落地业务场景(生产实战)
(1) 多 Agent 并行数据分析(扇出场景)
用户数据事件通过publish_message(A2A 广播),同时异步触发数据清洗、指标统计、报表生成三类 Agent,三个 Actor 异步并发执行,对比同步串行效率提升数倍;
(2) 跨机器分布式 SaaS 多租户
不同租户 Agent 部署在不同 Worker 节点,依托 A2A + 全异步 gRPC 通信,租户事件通过 Topic 隔离,消息异步路由,动态扩容新增 Worker 接入租户 Agent,不用停机改代码;
(3) 长耗时后台任务(如爬虫、批量推理)
任务 Agent 收到指令后异步发起批量 LLM 推理,主协程立刻释放,Runtime 继续处理其他消息,任务完成后异步推送结果 Topic,通知汇总 Agent;
(4) 事件链式流水线(Event Chain)
上游 Agent 处理完异步 publish A2A 事件,下游订阅 Agent 被动异步触发,上下游完全解耦,新增下游消费 Agent 仅需注册订阅,无需修改上游代码;
(5) 异构跨框架协作(A2A + 全异步)
谷歌 Vertex 云端 Agent 异步发送 A2A 标准任务消息至 AG2 集群,AG 分布式 Worker 异步接收、调度本地 Actor 处理,结果再按 A2A 规范异步回传谷歌侧。
四、AG2 全模块系统化知识点拆解(尼恩AG2学习圣经 1~10 章 知识总结)
模块 1: 双 Agent 最小对话模型(AG 最基础运行逻辑) 【来自 尼恩AG2学习圣经第二章】
1. 两大原生预设 Agent 角色
【1】AssistantAgent(思考方): 默认开启 llm_config、禁用 code_execution、human_input_mode=NEVER,依靠 LLM 生成方案、代码,只动脑不执行;内置系统提示词强制任务完成输出 TERMINATE 关键词,作为终止标识。
【2】UserProxyAgent(执行方): 默认 llm_config=False 无大模型能力、开启代码执行配置,human_input=TERMINATE,负责接收代码、沙箱运行、反馈结果、触发人工确认,只执行不思考。
进阶开发推荐直接使用原生 ConversableAgent 自定义配置,摆脱默认参数隐性约束,生产环境可控性更强。
2. 乒乓式对话底层循环逻辑
单次initiate_chat开启完整对话,全流程标准化链路:send(发送消息)→receive接收→_append_oai_message标准化存历史→generate_reply生成回复→send回传
【1】_prepare_chat双向初始化: 发起方调用初始化时自动递归重置双方计数器、清空双向历史,clear_history=True默认清空二者对话记录,不同 Agent 间历史独立隔离,_oai_messages以对方实例为 key 分组存储,A 和 B、A 和 C 对话记录互不干扰。
【2】_append_oai_message自动角色转换: A 发给 B 的消息在 B 的历史里自动转为 role:user,B 的回复自动标记 assistant,保证每个 Agent 本地消息永远符合 OpenAI 交替格式,不用手动修改角色。
【3】ChatResult: 对话最终返回结构化结果,包含 chat_history 全量消息、summary 摘要、cost 分层 token 账单、human_input 人工记录,summary 支持 last_msg、LLM 总结、自定义函数三种生成策略,cost 区分缓存 / 真实计费两套统计口径,方便成本核算。
模块 2: 对话人机控制与三层终止体系
1. 三种 human_input 人机介入模式(由 check_termination_and_human_reply 顶层函数管控,回复链最高优先级)
【1】ALWAYS: 每轮对话均可人工输入,回车自动 AI 回复,输入 exit 直接终止,适合实时交互式答疑机器人;
【2】TERMINATE(UserProxy 默认): 常规对话全自动,仅触发终止条件时弹窗确认,适合半自动化代码评审、单据审核;
【3】NEVER: 全程无任何人工弹窗,全自主运行,适配 CI 自动化、批量离线处理任务。
计数器规则:人工输入有效内容时,对应 sender 的连续自动回复计数器清零;空回车、exit 终止不重置计数。
2. 三层递进终止防护机制(优先级从高到低)
【1】is_termination_msg(内容终止): 自定义回调函数,检测消息关键词 / 结构化字段,灵活自定义终止规则,优先级最高;
【2】max_consecutive_auto_reply(连续回复上限): 按发送方独立计数器,防止两个 Agent 无限闲聊死循环,可全局定值或分角色差异化配置;
【3】max_turn(单次会话轮次): initiate_chat 入参,仅约束当前单次对话总往返轮次,顶层成本熔断,避免超长对话消耗 token。
3. 自定义 Human 输入源
通过重写 get_human_input 或 UserProxy 专属 input_func,脱离控制台输入,对接 WebSocket 网页、消息队列、自动化 Mock 数据,实现 Web 端人机交互、后端审批系统接入。
模块 3: generate_reply 五层责任链引擎(Agent 决策内核)【来自 尼恩AG2学习圣经第三章】
Conversable 生成回复遵循固定优先级五层责任链,自上而下依次匹配,匹配成功直接终止后续函数,整体设计遵循「安全 > 兼容 > 结构化执行 > 代码 > LLM 兜底」原则:
【1】第一层: check_termination_and_human_reply(最高优先级):终止判定 + 人工输入处理,全链路安全闸门,优先管控会话生命周期,任何场景最先执行;【2】第二层:旧版 function_call 解析:兼容 OpenAI 早期函数调用格式,存量老模型、旧项目适配;
【3】第三层: 新版 tool_calls 标准工具处理:当前主流标准化工具调用解析,解析 JSON 格式 tool_calls,匹配函数执行;【4】第四层:代码块提取执行:正则提取 ```包裹代码,交由代码执行器运行,确定性运算优先于 LLM 生成;
【5】第五层: generate_oai_reply 兜底 LLM 推理**:前面四层全部无法处理才调用大模型,无 llm_config 直接跳过。
自定义扩展:register_reply 注册函数
可通过 position 自定义插入优先级(0 最高,- 最低),支持按发送方名称 / 实例 / 自定义函数做 trigger 触发,轻松实现敏感词拦截、LLM 空回复自动重试、定向应答等自定义逻辑,无需修改框架源码。
返回规范:(True, 内容) 结束链路、(True,None) 终止对话、(False,None) 放行至下一层处理器。
模块 4: 工具调用 + 代码执行(Agent 对接外部世界双方案)【来自 尼恩AG2学习圣经第5章】
一、工具调用(预定义接口,白名单管控)
【1】Caller-Executor 分离安全架构(核心):
Caller(带 LLM)仅保存工具描述 JSON Schema,只能决策调用哪个工具;Executor(无 LLM)持有真实函数,负责运行,二者通过 A2A 消息交互,实现推理和执行权限隔离,规避提示注入越权风险。
【2】三种工具注册方式
- 双层装饰器: 同一函数分别注册 LLM 侧、执行侧;
- register_function 一站式注册: 生产批量工具首选,一行完成双端挂载;
- @tool 装饰器: 先封装 Tool 实例,再按需绑定 Agent。
【3】Annotated 注解自动生成 Schema: 依靠参数类型 + 注释自动生成 OpenAI 规范工具入参文档,摒弃易出错的手写 Docstring 解析。
二、代码执行(动态逻辑,沙箱兜底)
【1】LocalCommandLine: 本地开发调试,直接本机进程运行,无强隔离;
【2】DockerCommandLine: 生产唯一推荐,容器级隔离,可限制 CPU / 内存 / 网络,禁用外网、资源超限熔断,隔离恶意代码;
【3】选型规范: 固定 API、数据库查询用工具;非标数据清洗、绘图、自定义运算用代码执行,工业项目普遍采用「工具取数 + 代码加工」混合架构。
模块 5: GroupChat 多智能体群聊协作【来自 尼恩AG2学习圣经第六章】
1. 两大核心组件
- GroupChat: 纯数据类,存储成员、全局统一 messages、max_round、流转规则、发言配置,全 Agent 共享一份上下文,消除信息孤岛;
- GroupChatManager: 中心化调度 Agent,所有消息必经 Manager 中转,禁止 Agent 点对点私自通信,靠 request=False 实现非发言人静默接收不抢答。
2. 四种发言人选择策略
【1】round_robin 轮询: 固定顺序,标准化流水线首选,无 LLM 开销;
【2】random 随机: 头脑风暴、方案对比;
【3】auto 智能选型: 依靠各 Agent 的 description 角色描述,LLM 动态选最合适角色,灵活业务场景;
【4】自定义回调函数: 定制化业务路由,可根据对话内容动态切换发言人。
3. 流转约束与护栏
allowed 白名单 /disallowed 黑名单配置发言跳转规则,锁定消息流向;Guardrails 消息中间件可拦截、替换敏感内容,实现群聊内容安全管控。
4. description 规范:auto 选型关键
区分 system_message(自己怎么干活)、description(什么场景需要我上场),description 写清楚触发关键词,是 LLM 精准选人的关键。
模块 6: autogen-core Actor 分布式内核【来自 尼恩AG2学习圣经第10章】
1. 智能体基类
BaseAgent:基础 Actor 模板,on_message 固定入口;RoutedAgent+@message_handler 依靠消息类型自动路由,不同消息绑定不同处理函数,替代原生 if 判断。
2. 消息升级:废弃字典,采用 dataclass 强类型消息,编译期即可校验字段,分布式跨机传输不易出错。
3. 两套 Runtime 运行环境
【1】SingleThreadedAgentRuntime: 单线程 asyncio,本地调试、单元测试,代码直接运行;
【2】GrpcWorkerRuntime: Host+Worker 主从分布式架构,Host 统一管理路由表,多台机器部署 Worker,Agent 跨机器靠 gRPC+A2A 通信;
核心优势:同一套业务 Agent 代码,更换 Runtime 实例即可单机切集群,不用改业务逻辑。
4. 两种订阅:TypeSubscription 精准匹配单事件,TypePrefixSubscription 批量匹配前缀事件,实现日志全量监听、领域事件聚合。
模块 7:7/8/9 章补充配套能力
【1】对话编排: 分为串行编排(ChatResult 摘要传递上下文)、嵌套子对话(任务拆分子会话),实现复杂任务分层拆解;
【2】LLM 基础设施: OpenAIWrapper 统一封装全厂商大模型,支持超时、重试、多级缓存、多密钥轮询,兼容 Ollama/Anthropic/Gemini 等全系列模型;
【3】长文本记忆: 依托 summary_method 三种摘要方案压缩历史消息,裁剪冗余上下文,解决超长上下文超限、token 成本过高问题。
五、AG2落地选型全指南
【1】简单问答、一对一协作、小 Demo: agentchat + Assistant+UserProxy;
【2】固定步骤多角色流水线: agentchat+GroupChat+round_robin + 流转白名单;
【3】头脑风暴多方案评审: GroupChat+random/auto 模式;
【4】事件驱动、多 Agent 并行任务: autogen-core+Publish 广播 A2A;
【5】跨机器集群、SaaS 多租户平台: autogen-core+Grpc 分布式 Runtime+A2A 跨机通信;

在AutoGen(AG2)的实际工程落地中,正确的架构选型直接决定了系统开发的效率、维护成本与最终性能。
以下是对六种典型模式的深度扩展与工程化解析。
5.1. 简单问答、一对一协作与小规模演示场景
核心架构:agentchat+ Assistant+ UserProxy
适用场景边界
- 单一任务目标的对话式交互,如代码解释、文档摘要、数据分析查询
- 开发者与AI的结对编程(Pair Programming)会话
- 产品演示、技术原型验证等非生产环境
- 总对话轮次通常少于20轮,无复杂状态依赖
架构原理深度展开
在此模式下,UserProxy代理充当用户意图的中继器与工具执行器。它不主动发起话题,而是:
(1) 接收用户输入(文本或文件)
(2) 决定是否触发工具调用(如执行代码、查询数据库)
(3) 将工具执行结果格式化后传递给Assistant
(4) 在需要用户确认时暂停对话流
Assistant则是纯推理引擎,专注于:
- 理解任务上下文
- 生成解决方案(代码、分析、计划)
- 决定何时需要调用工具
- 解释执行结果并提供下一步建议
关键配置与工程考量
# 典型配置示例
assistant = AssistantAgent(
name="primary_assistant",
llm_config={"config_list": [...]},
system_message="你是一个专业的Python数据分析助手..."
)
user_proxy = UserProxyAgent(
name="user_proxy",
human_input_mode="ALWAYS", # 关键决策点:何时需要人工介入
code_execution_config={
"work_dir": "temp",
"use_docker": False, # 安全与便利的权衡
"timeout": 30
},
max_consecutive_auto_reply=5 # 防止无限自动对话循环
)
模式边界警告:当对话开始涉及“先做A,等结果B,再决定C”的条件逻辑,或需要超过3个专业角色协作时,此模式会迅速变得难以维护。此时应升级到更结构化的模式。
5.2. 固定步骤多角色流水线
核心架构:agentchat+ GroupChat+ round_robin+ 流转白名单
适用场景特征
- 有明确阶段划分的审批流程(如需求评审→技术设计→代码审查→测试验收)
- 数据预处理→特征工程→模型训练→评估的机器学习流水线
- 客服工单的标准化处理流程(受理→分类→解决→回访)
- 每个步骤的输出是下一步的明确输入,顺序基本固定
工作流引擎的替代实现
虽然GroupChat提供了基础编排,但在复杂流水线中,更推荐使用有状态的工作流引擎:
class StatefulPipeline:
def __init__(self):
self.current_stage = "requirements"
self.stage_handlers = {
"requirements": [business_analyst],
"design": [architect, tech_lead],
"review": [reviewer],
"test": [qa_engineer]
}
def get_next_speaker(self, current_speaker, messages):
# 基于当前状态而非对话历史决定下一参与者
stage_agents = self.stage_handlers[self.current_stage]
if current_speaker in stage_agents:
# 仍在当前阶段内轮转
return self._next_in_stage(current_speaker, stage_agents)
else:
# 阶段完成,推进到下一阶段
self._advance_stage()
return self.stage_handlers[self.current_stage][0]
流转白名单的精细控制
白名单不应仅是“谁能说话”,而应定义为“在什么状态下谁能对谁说”:
transition_matrix = {
"requirements_done": {
"from": ["business_analyst"],
"to": ["architect", "tech_lead"],
"condition": "requirements_doc_approved == True"
},
"design_done": {
"from": ["architect", "tech_lead"],
"to": ["reviewer"],
"condition": "design_doc_submitted and not has_critical_issues"
}
}
工程化建议:为每个阶段定义明确的输入验证规则和输出验收标准。使用结构化数据(如JSON Schema)而非自然文本来传递阶段结果,可显著降低解析错误。
5.3. 头脑风暴与多方案评审场景
核心架构:GroupChat+ random/auto模式
模式本质:这是群体智能的模拟实验,目标不是达成一致,而是最大化创意发散与多样性。
random模式的动力学设计
完全随机选择下个发言者看似简单,但需添加防主导机制:
class BrainstormScheduler:
def __init__(self, agents):
self.agents = agents
self.speaker_counts = {agent.name: 0 for agent in agents}
self.last_speakers = []
def select_next_speaker(self, current_speaker, messages):
# 避免同一代理连续发言
available = [a for a in self.agents
if a.name != current_speaker.name]
# 鼓励发言少的代理参与
weights = [1.0 / (self.speaker_counts[a.name] + 1) for a in available]
selected = random.choices(available, weights=weights, k=1)[0]
self.speaker_counts[selected.name] += 1
return selected
auto模式的智能激发策略
当使用auto模式(由LLM决定下个发言者)时,需精心设计系统提示词来激发创造性冲突:
你是一个创意讨论的主持人。当前讨论主题是:{topic}
请根据以下原则选择下个发言者:
**(1) 如果上一个观点很具体,选择一个能提供相反视角或补充维度的专家**
**(2) 如果讨论陷入细节,选择一个能抽象升华的思考者**
**(3) 如果气氛过于和谐,故意选择一个常提出挑战性问题的角色**
**(4) 确保每个专家在3轮内至少发言一次**
当前已发言分布:{participation_stats}
创意收敛机制:在充分发散后(如8-10轮),需要从random/auto模式切换到收敛阶段:
(1) 指定一个主持人代理总结所有观点
(2) 让每个专家对总结进行“同意/补充/反对”投票
(3) 基于投票进行聚类分析,识别主流方案
(4) 最终由决策者代理基于预设标准(可行性、创新性、成本)做出推荐
5.4. 事件驱动、多Agent并行任务
核心架构:autogen-core+ Publish广播 + A2A通信
适用场景特征
- 实时监控与告警处理(如一个代理检测异常,多个专家并行分析)
- 市场事件的多维度即时分析(新闻、社交情绪、价格数据需并行处理)
- IoT设备集群的协同决策
- 需要松耦合、高并发、低延迟响应的分布式系统
架构范式转变
此模式与前述所有模式有本质不同:从中心化调度转向事件驱动架构。每个Agent既是生产者也是消费者:
# 事件驱动Agent的典型结构
class EventDrivenAgent(ConversableAgent):
def __init__(self, name, expertise, event_bus):
super().__init__(name)
self.expertise = expertise
self.event_bus = event_bus
# 订阅感兴趣的事件类型
self.event_bus.subscribe(event_type="alert", callback=self.handle_alert)
self.event_bus.subscribe(event_type="data_update", callback=self.handle_data)
def handle_alert(self, alert_data):
# 处理告警事件,可能会发布新事件
analysis = self.analyze(alert_data)
self.event_bus.publish(event_type="analysis_result", data=analysis)
def handle_data(self, data):
# 处理数据更新事件
pass
事件总线的设计选择
(1) 内存事件总线:适用于单进程内Agent通信,零延迟但无法跨进程
(2) 消息队列中间件:如Redis Pub/Sub、RabbitMQ、Kafka,支持跨机器、持久化、削峰填谷
(3) gRPC流:适用于需要低延迟、高吞吐量的点对点通信
并行任务协调模式
- 扇出模式:一个事件触发多个并行处理,每个处理者独立工作
- 聚合模式:等待多个并行处理完成,聚合结果后触发下一步
- 补偿事务:当某个处理失败时,触发补偿操作回滚其他已完成的处理
工程挑战与解决方案
- 事件风暴:设计事件优先级和过滤机制,避免Agent被无关事件淹没
- 循环依赖:通过事件类型命名规范(如
order.created、order.paid)和拓扑排序避免 - 一致性保证:引入事件溯源(Event Sourcing)和CQRS模式,确保状态可追溯
5.5. 跨机器集群、SaaS多租户平台
核心架构:autogen-core+ gRPC分布式Runtime + A2A跨机通信
适用场景特征
- 企业级多团队使用,需要资源隔离和租户管理
- 计算密集型任务(如大规模模拟、批量数据处理)需要动态扩缩容
- 高可用性要求,单点故障不可接受
- 混合云部署,部分Agent运行在本地,部分在云端
分布式Runtime设计要点
# 假设的集群配置
cluster:
nodes:
- name: node-1
role: orchestrator # 编排节点,负责任务分发和状态管理
resources: 4CPU, 8GB
- name: node-2
role: worker
resources: 8CPU, 32GB
labels: {
gpu: "true" }
- name: node-3
role: worker
resources: 16CPU, 64GB
labels: {
memory: "high" }
gRPC通信优化策略
(1) 连接池:避免每次调用新建连接,复用长连接
(2) 负载均衡:客户端负载均衡(如轮询、一致性哈希)或服务端负载均衡(如gRPC-LB)
(3) 流式调用:对于大文件传输或长时间任务,使用gRPC流式接口避免超时
(4) 超时与重试:根据操作类型设置差异化超时,并实现指数退避重试
多租户隔离实现
- 网络隔离:每个租户在独立的VPC或命名空间中运行Agent
- 资源配额:CPU、内存、并发任务数限制
- 数据隔离:租户数据加密存储,访问权限控制
- 计费与计量:记录每个租户的Agent调用次数、运行时长、资源消耗
服务发现与健康检查
- 每个Agent启动时向服务注册中心(如Consul、Etcd)注册
- 定期健康检查,失败节点自动从负载均衡池中移除
- 编排节点监控整个集群状态,自动替换失败任务
六:AG2 自主协调 vs LangChain+LangGraph 显式编排 大PK
LangChain 是组件化工具链 + 应用开发底座,LangGraph 是其生态专属有状态图编排运行时,二者构成「LCEL 组件 + Graph 工作流」一体化技术栈;
AG2 采用双层架构(agentchat 上层对话 + autogen-core 底层 Actor/A2A 分布式内核)、对话即计算的核心设计,三者底层编程范式、运行模型、部署能力完全分化。
本文从架构内核、编程思想、核心能力、业务场景、落地成本、混合集成方案六大维度做选型拆解,给出明确落地决策标准,覆盖原型开发、中小项目、企业分布式 SaaS 三类业务。
6.1、三大产品底层架构与设计哲学对比

1. LangChain+LangGraph 生态整体架构
LangChain 生态采用分层积木式设计:langchain-core(Runnable/LCEL)为基础组件层,封装 LLM、向量库、工具、记忆、提示词等标准化通用组件;LangGraph 作为独立运行时,基于 有向状态图(StateGraph) 实现工作流编排,是整个生态的流程调度引擎。
- LangChain 核心思想: 链式编程(LCEL):以 Runnable 为最小单元,通过
|运算符串联工具、LLM、检索,线性 / 分支链路显式硬编码,流程走向由开发者提前定义,偏向固定流水线思维**; - LangGraph 核心思想: 状态机 + 显式图编排:把业务拆成一个个节点 Node,通过边 Edge、条件分支配置流转规则,内置全局状态容器 + 断点 Checkpoint 持久化,原生支持循环、异常回滚、人机插空(HITL),全链路状态可落地存储、故障可从断点重启;
- 短板: LangChain 原生无多智能体自主对话能力,多 Agent 协作必须依赖 LangGraph 手动拆分节点硬编码流转;无内置代码沙箱执行能力,Docker 隔离代码环境需要自研封装。
2. AG2 双层架构与设计哲学
AG2 分为上层 agentchat(同步对话层)、底层 autogen-core(全异步 Actor+A2A 分布式内核),核心设计:对话即计算,双 Agent 消息往返 = 最小计算单元。
- agentchat 层(80% 常规业务): ConversableAgent 为基,Assistant(思考)+UserProxy(执行)天然配对,依靠消息乒乓交互自主推进任务,流程不用开发者硬编码,由 Agent 对话自然涌现,内置 Docker / 本地双模式代码执行器,开箱即用代码沙箱;GroupChat 内置轮询 / 随机 / 自动发言人四种调度,快速实现多角色群聊协作;
- autogen-core 层(20% 生产分布式): 基于 Carl Hewitt Actor 三大准则 + 谷歌 A2A 跨框架通信协议,全异步事件驱动,
AgentId/TopicId双全局寻址、RPC+Pub/Sub 双通信原语,单机 SingleRuntime 与分布式 Grpc-Host/Worker Runtime 代码完全复用,一套业务一键切换集群部署,天然支持百万级 Agent 弹性扩缩、多租户隔离、事件扇出并行流水线。
核心设计本质区分
| 框架组合 | 核心抽象 | 流程控制权 | 运行驱动方式 |
|---|---|---|---|
| LangChain+LangGraph | 节点 + 状态图 | 开发者全量显式编写节点与分支规则 | 开发者定义的图结构驱动 |
| AG2 agentchat | 双向对话 | Agent 自主协商生成执行路径 | 消息交互自然驱动 |
| AG2 autogen-core | Actor+A2A 事件 | 事件订阅规则动态路由 | 异步消息事件驱动 |
6.2、关键能力横向选型对照表
6.2.1 多智能体协作能力(选型第一分水岭)
(1)LangChain+LangGraph
所有多 Agent 逻辑需要手动拆分成不同 Node 节点、配置跳转边,角色间消息传递、发言顺序全部硬编码,新增协作角色必须修改 Graph 代码;适合流程完全可控、步骤固定的多任务;头脑风暴、开放式多方辩论、动态随机任务无法快速落地,需要大量状态定制开发。
(2)AG2
- agentchat: 原生 GroupChat,round_robin/auto/ 随机四种发言策略,auto 模式依靠 Agent 自身 description 由 LLM 动态选发言人,新增 Agent 只需要加入群成员列表,无需改动流转代码,开放式群聊、辩论、头脑风暴天然适配;
- autogen-core: 依托 A2A PubSub 广播 + Topic 订阅,一条事件自动扇出 N 个 Agent 并行处理,多实例跨机器分布式协作零硬编码。
选型结论:固定流水线多角色→LangGraph;开放式自主协作 / 评审群→AG2
6.2.2 代码执行与工具调用
LangChain+LangGraph
- 工具: 依赖
Tool组件封装,调用链路需要在节点中手动编写调用逻辑,无 Caller/Executor 权限隔离; - 代码执行: 无原生沙箱,需要自行集成 Docker、subprocess,环境隔离、安全管控全自研,复杂 Python 数据分析、绘图落地成本高。
AG
- 工具: 原生 Caller-Executor 分离架构,LLM 侧只存工具描述 Schema,执行侧持有真实函数,依靠 A2A 消息跨角色调用,天然隔离越权风险;Annotated 注解自动生成工具入参文档,省去手写 Schema;
- 代码: 内置 Local/
DockerCommandLineCodeExecutor两套执行器,一行配置启用容器隔离,开箱即用,数据分析、自动化报表、脚本生成是 AG 天然优势。
选型结论:仅 API 接口工具调用→LangChain;大量动态代码生成执行→AG2
6.2.3 状态管理、断点与人机交互
LangGraph
状态是一等公民,全局 State 字典全链路透传,原生 Checkpoint(断点存储),支持任意步骤暂停、重启、回溯,HITL 人机在图任意节点插入人工输入,适合长流程审批、分步落地业务。
AG2
- agentchat:
human_input_mode=ALWAYS/TERMINATE/NEVER三模式,全局配置人机介入时机,终止规则is_termination_msg灵活自定义;会话状态存储在 Agent 私有_oai_messages,按对话对象隔离;无原生全局 Checkpoint,需对接 Redis/DB 自行持久化; - autogen-core: 依托 A2A Topic source 天然多租户会话隔离,Runtime 可接入中间件做消息持久化,分布式场景断点靠消息中间件落地。
选型结论:强状态回溯、分步审批、长流程断点续跑→LangGraph;灵活人机对话、会话隔离→AG2
6.2.4 部署形态:单机 / 分布式 / 跨机器
LangChain+LangGraph
原生仅单机进程运行,无官方分布式 Runtime,多机器部署需要自研消息队列、RPC 封装节点通信,集群化改造工作量极大,无原生多租户隔离机制。
AG2
分层部署:agentchat 单机开箱;autogen-core 替换 Runtime 为 GrpcWorker 即可 Host + 多 Worker 跨服务器集群,基于 A2A 标准协议跨框架互通(可对接 LangChain/Vertex 等异构 Agent),原生 Topic source 租户隔离,SaaS 平台首选。
选型结论:单机小应用→二者均可;分布式集群 / SaaS 多租户→优先 AG2
6.2.5 编排模式:固定流水线 vs 事件驱动
【1】LangGraph 最优: 确定性 DAG 流水线:审批流、数据 ETL、固定步骤 RAG 查询,步骤 1→步骤 2→步骤 3 严格固定,分支、循环提前写死;【2】AG 双路线:-agentchat:** 对话编排,嵌套子对话、多轮协商,适合需求不确定、需要 AI 动态调整步骤的场景;
- autogen-core: PubSub 事件链编排,上游处理完发布 A2A 事件,下游订阅自动触发,新增业务只注册订阅、不改上游代码,流式任务首选。
6.3、六大落地场景精准选型(落地实战指南)
场景 1:固定步骤标准化业务(RAG 知识库问答、单据固定审批、数据 ETL)
选型:LangChain+LangGraph
需求特征:业务步骤固定、流转路径提前确定,分支 / 循环规则可枚举,需要状态留存、异常从断点重启。
示例:用户提问→向量检索→结果整理→摘要输出,中间任意步骤失败可从检索节点重启,用 LangGraph 节点拆分,LCEL 串联组件开发效率最高。
场景 2:开放式多 Agent 自主协作(代码评审小组、头脑风暴方案、产品研发多方讨论)
选型:AG2 agentchat+GroupChat
需求特征:无固定执行顺序,AI 自主判断谁发言、谁处理,新增角色不用改流程,频繁迭代协作逻辑。
示例:产品、开发、测试三个 Agent 群聊评审需求,自动轮流发言,发现问题即时调整方案,GroupChat auto 模式一键实现。
场景 3:AI 自动生成代码 + 自主执行 (数据分析、报表生成、批量脚本处理)
选型:AG2 Assistant+UserProxy
原生代码沙箱,不用自研执行环境,LLM 生成代码→Proxy 容器运行→反馈结果迭代,是 AG 标杆落地场景,Lang 需要额外搭建 Docker 环境。
场景 4:事件驱动高并发、多任务 自主并行(实时数据流处理、日志分析、多数据源同步)
选型:AG2 autogen-core+A2A PubSub
一条业务事件广播,清洗、统计、入库多 Agent 异步并行处理,新增消费 Agent 仅注册 Topic 订阅,依托全异步 Actor 突破单机性能,LangGraph 无法原生实现扇出并行。
场景 5:企业 SaaS 多租户自主智能平台、跨服务器集群部署
选型:AG2 autogen+Grpc 分布式 Runtime
依托 A2A 协议跨机通信,Topic.source 隔离租户数据,Worker 节点横向扩容,LangChain 无原生分布式能力,改造成本超 3 倍。
场景 6:小型 RAG + 简易对话原型、快速 POC 验证
二选一均可
- 偏向固定查询流程: LangChain+LCEL;
- 偏向人机自由问答、偶尔调用工具: AG agentchat。
6.4、混合架构选型(业界主流折中方案)
实际项目中大量场景不排他,可混合集成,利用各自优势互补:
(1) LangGraph 做顶层固定业务主干 + AG2 做分支开放式自主子任务
整体审批主线用 LangGraph 编排(固定节点、断点续跑),分支环节(如方案评审、代码生成)调用 AG2 Agent 集群完成自主协作,LangGraph 通过 A2A 协议远程调用 AG 服务;
(2) AG2 autogen 做事件总线 + LangChain 封装工具组件
AG 依托 A2A 做全链路事件分发,LangChain 封装各类第三方工具 / 向量库,AG 收到事件后调用 LangChain 工具完成检索、API 查询;
(3) 原型先用 LangChain/AG agentchat,业务扩分布式后下沉 autogen-core
前期 POC 用 LangChain 快速搭固定流程,后期需要多 Agent 集群时迁移 AG 分布式内核。
6.5、选型避坑准则
【1】盲目用 LangGraph 做开放式多智能体: 硬编码全量角色流转,需求微调就要改动图结构,迭代成本爆炸;
【2】用 agentchat 做固定大规模流水线: 无全局状态持久,长流程崩溃无法断点重启,优先 LangGraph;
【3】需要分布式却选 LangChain: 后期重构分布式、多租户成本极高,前期直接规划 AG2 autogen;
【4】大量代码生成场景选 LangChain: 额外自研沙箱、异常捕获,开发周期翻倍,优先 AG2。
6.6、极简选型速记口诀
定死流程、要断点回溯 → LangChain+LangGraph
自由对话、代码自动化 → AG2 agentchat
事件并行、分布式 SaaS → AG2 autogen+A2A
固定主干 + 灵活子任务 → 二者混合集成
七、全文总结
AG2 是一套兼顾快速原型与企业分布式部署的全栈多智能体框架,agentchat 负责快速落地业务,autogen-core 负责生产级分布式底座;
A2A 是贯穿全框架的统一智能体通信标准,上层隐式封装简化开发,底层原生支撑 RPC 点对点、PubSub 广播两类消息交互,单机对话、群聊协作、跨机器集群全部依托 A2A 完成消息流转。
结合AG2 与 A2A 日常开发优先使用 agent 快速验证需求,遇到单机瓶颈、异步并行、分布式部署需求时下沉至 autogen-core,依靠 A2A 协议平滑升级分布式架构。


