

编程 Agent 最让人兴奋的地方,是它能自己读代码、改文件、跑测试。最让人不放心的地方,也正是这些能力。
很多团队试用 AI Agent 后都会遇到类似问题:它改了不该改的文件,跑了没必要的命令,绕过了已有架构,甚至把一个小 bug 修成了大重构。表面看是模型“不听话”,但更准确地说,是 Harness 的边界和反馈没有设计好。
Agent 失控通常不是突然发生的,而是一步步偏离。
失控的第一类原因:上下文污染
上下文污染是最常见的问题。
模型会基于它看到的信息做判断。如果上下文里混入太多无关内容、旧规则、过期文档、冲突指令,Agent 就容易走偏。
典型场景:
- README 已经过期,但 Agent 仍按旧说明执行;
- 根目录规则要求用
npm,子项目实际用pnpm; - 对话早期用户说“可以顺手优化”,后面模型把它理解成大范围重构;
- 搜索结果包含生成文件,Agent 误以为那是源码;
- 终端输出太长,被截断后丢了真正错误。
上下文污染的危险在于,它看起来不像错误。Agent 会很自信地执行一个错误方向。
解决方法不是简单加更多上下文,而是让上下文更干净:排除生成目录,拆分项目规则,定期清理旧指令,让 Agent 先计划再执行。
失控的第二类原因:工具误用
工具是 Agent 的手脚。工具给得越多,能力越强,风险也越高。
一个只会读文件的 Agent,最多给错建议;一个能写文件、运行 shell、访问外部系统的 Agent,如果没有边界,就可能造成真实损失。
工具误用分三种。
第一种是过度探索。Agent 为了理解问题,不断搜索、读取、打开无关文件,Token 和时间都被耗掉。
第二种是错误执行。比如它把测试命令当启动命令,把生产配置当本地配置,或者在错误目录运行构建。
第三种是危险操作。删除文件、重置 Git、执行迁移、调用线上 API,这些都不能让模型自由决定。
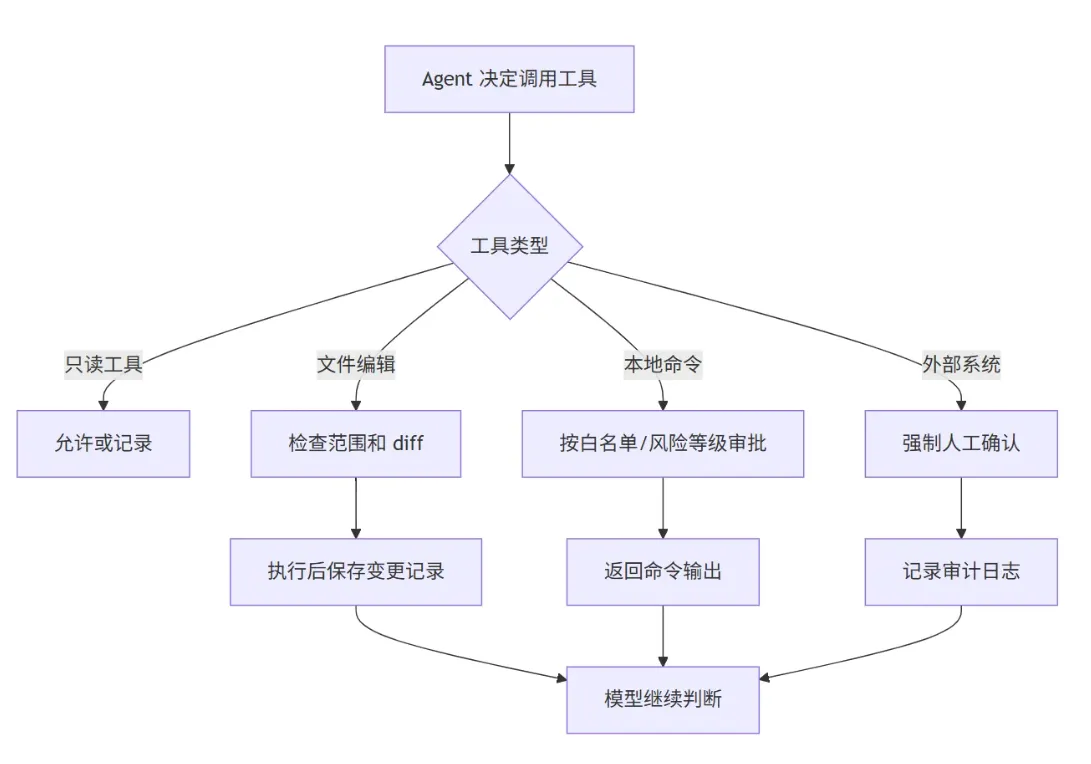
工具不是越开放越好。真正好的 Harness 会把工具分层。
失控的第三类原因:权限边界模糊
权限边界决定 Agent 能做什么。
如果边界太窄,Agent 做不了事;如果边界太宽,用户不敢用。
一个合理的权限设计通常包含:
- 默认询问高风险操作;
- 对安全命令设置白名单;
- 对危险命令设置黑名单;
- 对文件路径设置读写边界;
- 对外部系统调用设置人工确认;
- 对团队项目提供统一策略。
比如:
允许:npm test、git status、rg、ls
询问:npm install、数据库迁移、启动服务
禁止:删除仓库、重置分支、读取密钥目录
Claude Code 官方文档里也把权限和 checkpoint 放在安全机制里。核心思路很清楚:文件改动要能回滚,工具调用要受控制。
失控的第四类原因:没有验证目标
很多 Agent 写坏代码,不是因为不会写,而是因为没有明确的验证标准。
用户说:
优化一下订单逻辑。
这句话太宽。Agent 不知道优化什么,怎么判断完成,哪些行为不能变。它可能重构命名,可能改缓存,可能调整状态流转,最后引入兼容问题。
更好的任务描述是:
修复订单取消后库存没有恢复的问题。
只修改订单和库存相关模块。
先补一个失败测试,再修复。
运行 order 相关测试即可。
不要改支付流程。
这类描述给了边界、目标和验证方式。Agent 就不容易乱跑。
失控的第五类原因:人退出了循环
Agent 可以自动执行,但不等于人应该完全退出。
在真实工程里,很多判断不是测试能覆盖的:业务规则、兼容性、性能权衡、安全边界、产品意图,都需要人参与。
一个健康流程应该是:
- Agent 先探索;
- 生成计划;
- 人确认范围;
- Agent 执行;
- Agent 运行验证;
- 人审查 diff;
- 再决定是否提交。
如果跳过计划和审查,Agent 就容易把“能做”误解成“应该做”。
如何让 Agent 更稳
第一,任务要小。不要让 Agent 一次做“重构整个权限系统”。改成“先为管理员接口补鉴权中间件和测试”。
第二,先读后改。复杂任务先开计划模式或只读模式,让 Agent 先说明它理解的入口和影响范围。
第三,给验证标准。测试命令、预期行为、不能影响的模块,都写清楚。
第四,控制权限。读文件可以宽,写文件要看范围,命令执行要分级,外部系统要确认。
第五,保留审计。每次改了什么、跑了什么、失败过什么,都应该能回看。
总结
编程 Agent 失控,不只是模型问题,更是 Harness 问题。
常见根因包括:
上下文污染
工具误用
权限过宽
目标不清
缺少验证
人过早退出循环
好的 Harness 不追求让 Agent 无限自由,而是让它在清楚边界内高效行动。真正可用的 AI 编程系统,一定是自动化和可控性同时存在。

