
大家用 Claude Code、Cursor、Codex 这类 AI 编程工具时,应该都遇到过这种情况:只是想让 Agent 改个小功能,结果上下文很快就见底了。其实,大多数时候 token 消耗得快,并不一定来自特别复杂的推理,通常是 Agent 常用到的小动作带来的。
比如说,为了理解代码,Agent 会一遍遍地 grep、read、扫文件;为了跑个测试,把一大段日志、报错、diff、命令输出都塞进上下文。
这些必要的操作,因为夹杂了大量的“噪音”,导致 token 消耗量激增。
今天我们就来分享 3 个有用的开源项目,专门帮你的 Coding Agent 整理“上下文”:让它少翻无关代码,少吞冗长日志,把 token 留给更关键的信息。这就是今天要讲的 3 个项目:
CodeGraph:让 Agent 少翻代码
RTK:让 Agent 少吃命令输出
Tokalator:帮你看清 token 消耗
CodeGraph:先给代码库建一张图
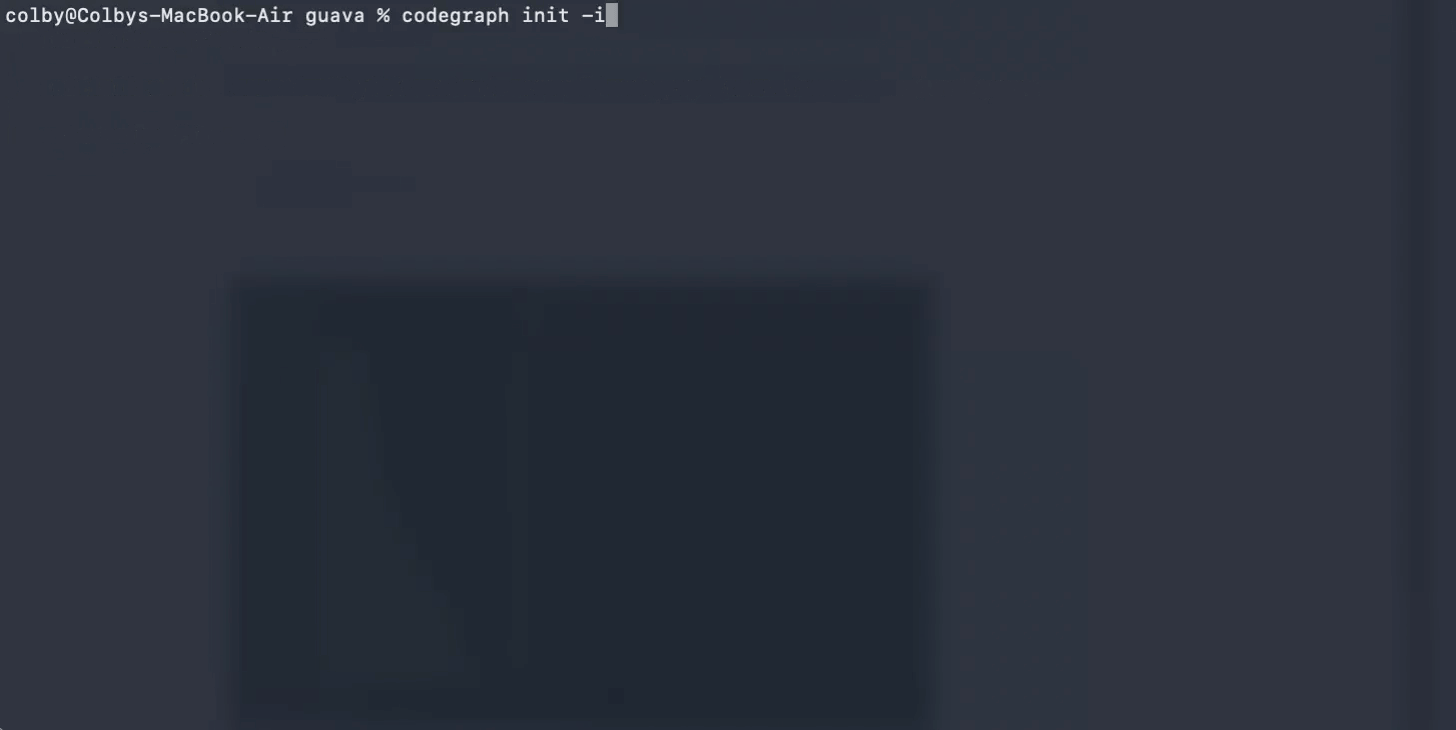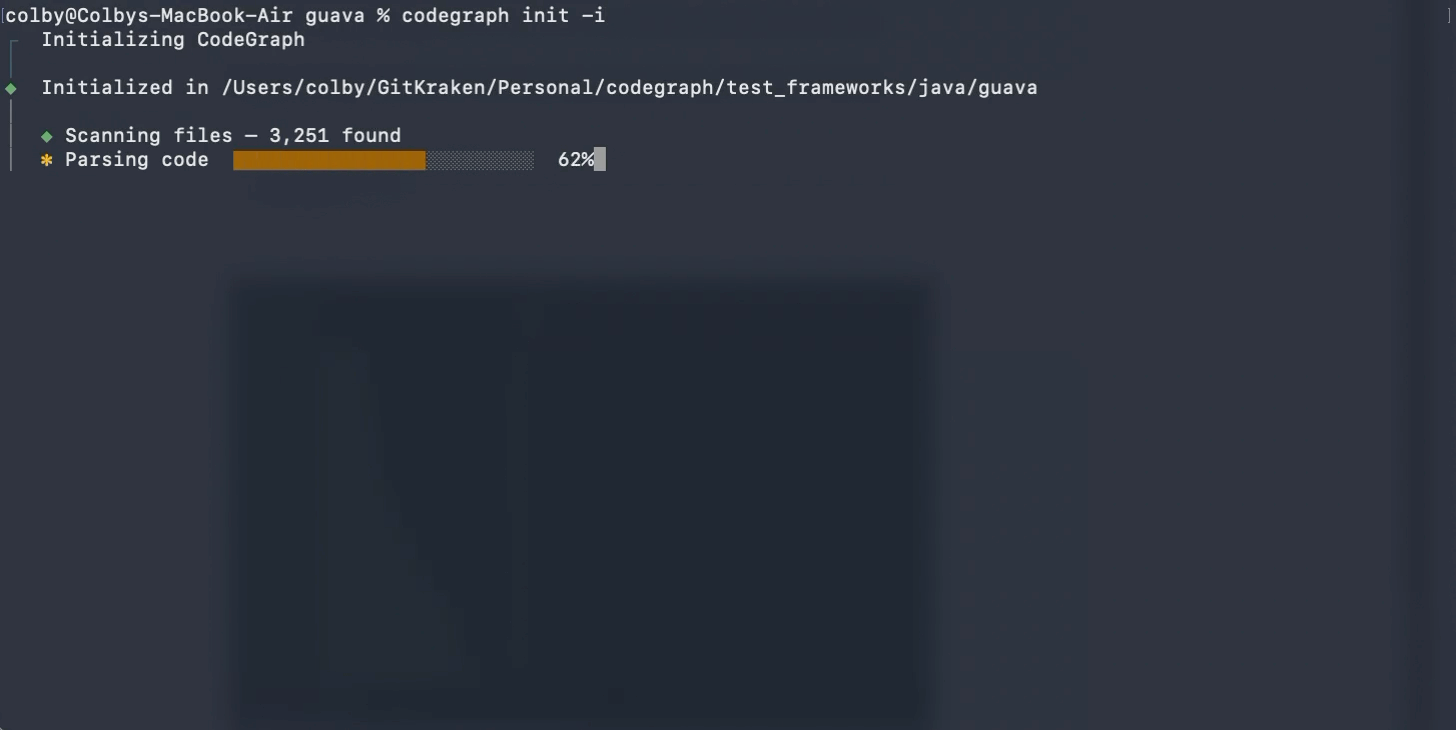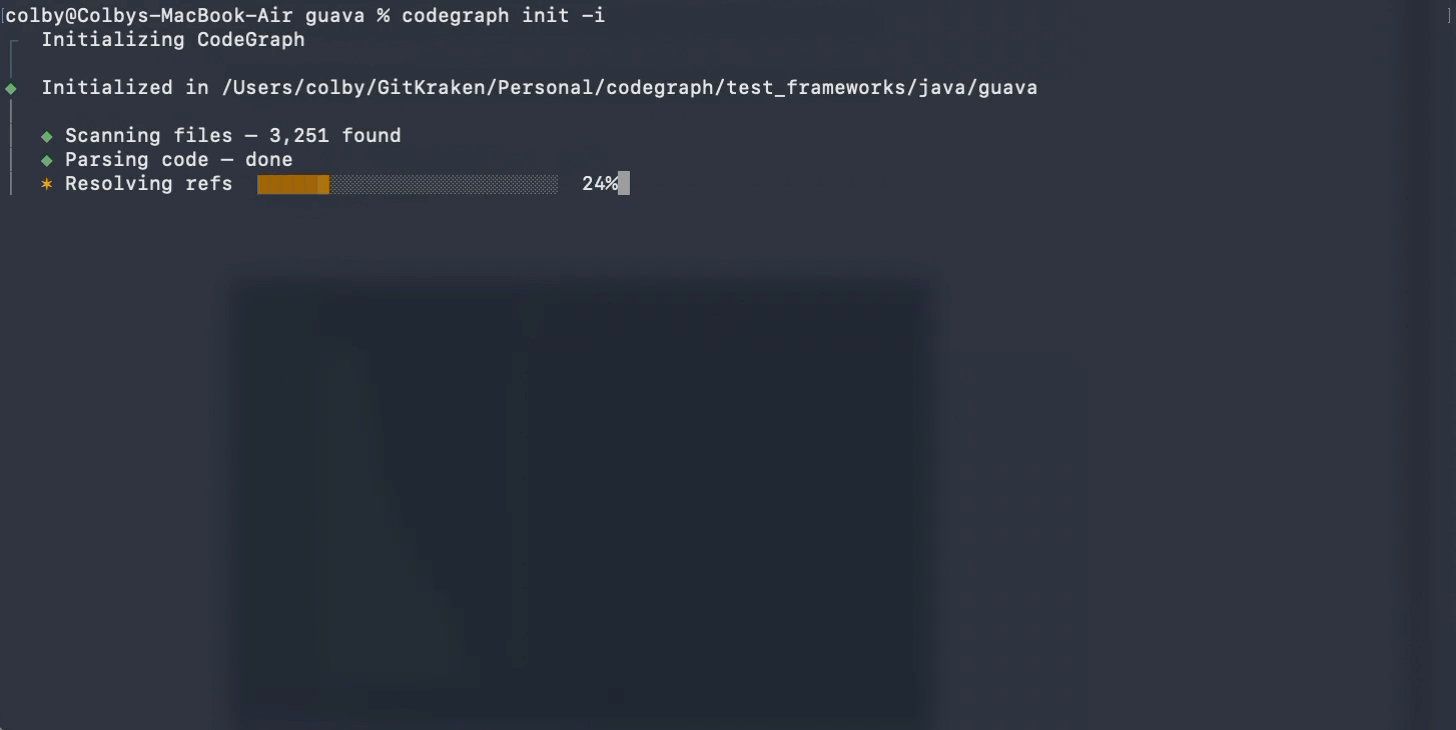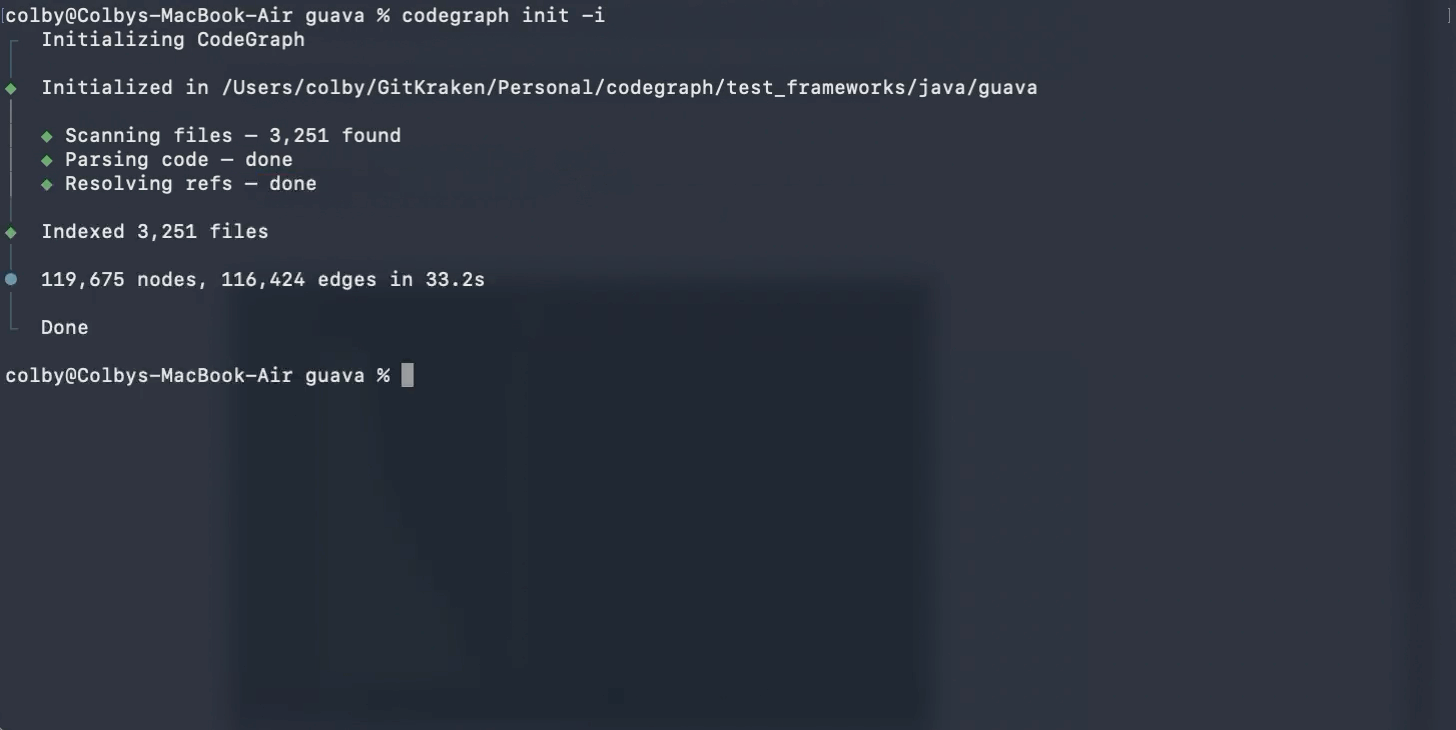
先说 CodeGraph,这是上周 RTK 项目介绍贴图下 @胡琦 推荐的项目,他说他最近用 CodeGraph 比较多,在这里感谢下他的推荐 👏。
这是它的项目名片:
CodeGraph = {
"地址": "github.com/colbymchenry/codegraph",
"标星": "43.4k",
"开发语言": "TypeScript",
"特点": ["本地代码知识图谱", "MCP 接入", "减少 Agent 代码探索成本"],
}
Agent 要理解一个代码库,通常会从文件开始探索,而 CodeGraph 要解决的就是这个 Agent 如何高效地理解某个代码库的问题。
普通的 Agent 读代码库,会先看代码目录结构,再搜关键词,再读几个文件,再继续追函数调用,从而构建整个代码库的全貌。这个了解代码库的过程和我们自己接手一个陌生项目很相似,唯一的区别是…Agent 多读一点东西,就是多消耗点 token。
CodeGraph 读代码库的思路是:与其让 Agent 每次都从零开始翻代码,不如先把代码库整理成一张结构化的图。这张图包含了代码库中函数、类、文件、调用关系、导入关系等关键信息。Agent 需要理解某个功能时,可以先查这张图,知道相关代码大概在哪里、谁调用了谁、哪些文件可能有关。这样一来,Coding Agent 不用一上来就把很多文件都塞进上下文。
简单来说,CodeGraph 就是给代码库做了一份“结构地图”,让 Agent 找代码时少走弯路。
它适合的 Coding 场景也很清楚:当项目比较大、文件比较多、调用关系比较绕时,CodeGraph 能大大减少 grep 和 read 的相关操作。只要提前把代码结构整理好,让 Agent 更快进入关键部分。
所以,CodeGraph 省的是这部分 token:Agent 为了找到相关代码而消耗掉的上下文。
RTK:让命令输出别那么占上下文
第二个是 RTK,也就是 Rust Token Killer。它解决的是另一类浪费:命令输出。
这是它的项目名片:
RTK = {
"地址": "github.com/rtk-ai/rtk",
"标星": "59.6k",
"开发语言": "Rust",
"特点": ["命令输出压缩", "支持 100+ 常用开发命令", "减少 Agent 读取日志和 diff 的 token 消耗"],
}
Coding Agent 写代码时,会经常性执行像是git diff、npm test、cargo test、docker ps、pytest、go test…之类的命令。这些命令的输出对 Agent 很有用,因为它要根据输出结果来判断下一步怎么做。
但问题也来了,那就是这些操作的原始输出经常很长。测试日志中,会有大量和任务无关的重复信息;构建的输出中也存在很多和错误无关的内容;diff 里也有 Agent 暂时不需要看的细节…如果这些与任务无关的内容,一旦直接进入模型上下文,就会浪费我们的 token。
作为一个 CLI 代理,RTK 处于命令输出和 Agent 之间,会先把命令的输出压缩、过滤、整理一下,再交给模型处理。这样 Agent 看到的就不是一大堆原始日志,而是更适合它阅读的缩减版本。
这类工具的好处很直观,它不会改变你写代码的主要流程,也不要求你重新理解一套复杂系统。它只做一件很具体的事,那就是把命令结果变短、变干净、变有用。
所以,RTK 省的是这部分 token:Agent 读取测试日志、报错信息、diff、命令结果时消耗掉的上下文。
RTK 的工作原理:

Tokalator:看清 token 到底花在哪
上面两个工具,一个帮 Agent 少翻代码,一个帮 Agent 少吞命令输出。Tokalator 关注的是另一个问题:token 到底花到哪里去了?
Tokalator 是一个面向 AI Coding 场景的 context engineering 工具包,里面包含 VS Code 扩展、CLI、MCP Server、usage tracker 等组件。项目的重点不是替你改代码,而是帮你监控和分析上下文预算。
这是它的项目名片:
Tokalator = {
"地址": "github.com/vfaraji89/tokalator",
"开发语言": "TypeScript",
"特点": ["实时 Token 预算监控", "MCP/CLI 接入", "看清上下文消耗来源"],
}
一般来说,你在 IDE 里开了很多文件,或者给 Agent 塞了很长的说明性文件,都会占用上下文。大多数时候,我们并不能清晰地感知到这些 token 是怎么被消耗掉的。
有了 Tokalator,你就可以直观地看到这些原本并不可见的消耗:当前上下文用了多少、预算还剩多少、哪些内容可能正在拖累上下文效率。它就像是一个“token 仪表盘”,让你清晰地了解到 token 浪费发生在哪里。知道浪费在哪,我们就好调整上下文、文件选择和提示词,节省 token 消耗了。

一些好用的省 token 小工具
还有一些同类项目
除了上面这几个,最近也有不少项目在做相近方向。它们不一定都适合放进主文里展开,但可以作为延伸项目看看。
Claude Context 和 CodeGraph 的方向比较接近,都在帮 Agent 快速找到代码库里的相关上下文。区别在于,CodeGraph 更偏代码结构图,Claude Context 更偏语义代码搜索。它可以让 Claude Code 和其他支持 MCP 的 AI Coding Agent,直接从整个代码库里搜索相关代码,减少多轮 grep 和 read。地址:github.com/zilliztech/claude-context
和 CodeGraph 类似,Codebase-Memory 也是代码知识图谱方向。它基于 Tree-Sitter 解析代码库,通过 MCP 给 Agent 使用。和 CodeGraph 相比,它更偏研究型一点,会把“代码库记忆”提前整理好,减少 Agent 每次从文件里重新探索。地址:github.com/DeusData/codebase-memory-mcp
Headroom 和 RTK 比较相近,都在做上下文压缩。RTK 偏开发命令输出,比如测试日志、diff、报错信息;Headroom 覆盖面更广,压缩对象包括 tool outputs、logs、files、RAG chunks、conversation history 等,会更像一个通用的 LLM 上下文压缩层。地址:github.com/chopratejas/headroom
OpenViking 关注 Agent 的上下文数据库。它想用类似文件系统的方式,把 memory、resource、skill 这类信息统一管理起来。和 RTK 那种“直接压缩 token”的工具不同,OpenViking 是通过“少塞、不乱塞、按需取”来间接减少上下文浪费。地址:github.com/volcengine/OpenViking
上面这些项目放在一起看,是在处理这些不同位置的 token 使用问题:
找代码:CodeGraph、Claude Context、Codebase-Memory
压缩输入和输出:RTK、Headroom
管理长期上下文:OpenViking
监控 token 预算:Tokalator
本文只挑了 3 个更具代表性的项目来讲解,剩下的项目感兴趣的小伙伴可以当作延伸阅读,适当了解下。


