
Spring全家桶:Spring Cloud 2023.0.x 微服务核心理论与CAP/BASE定理知识体系
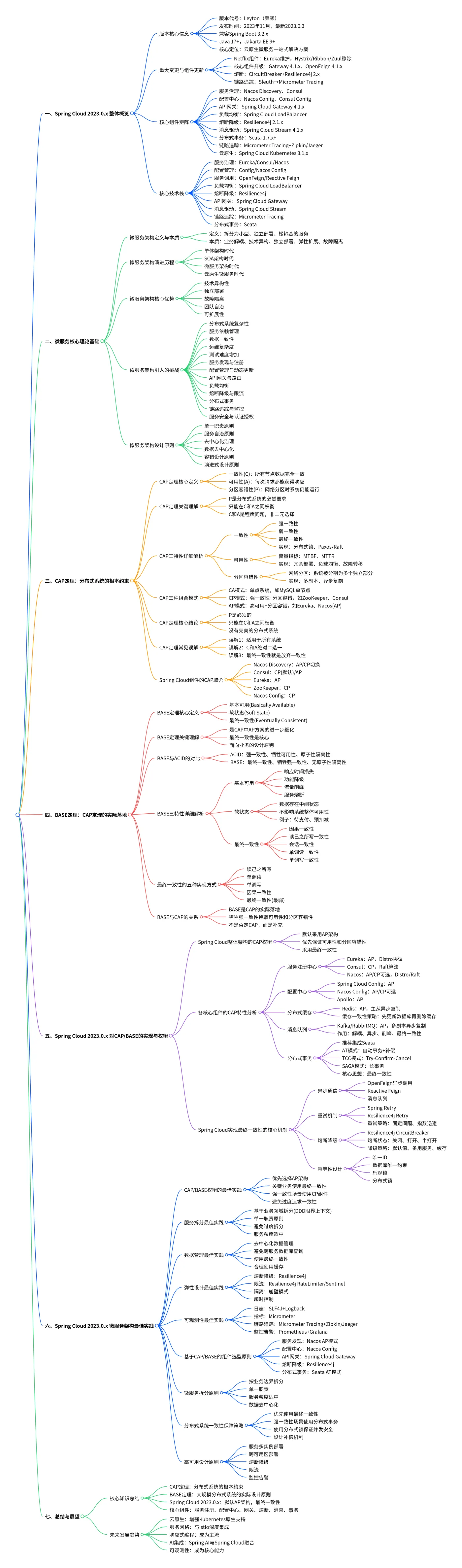
一、Spring Cloud 2023.0.x 整体概览
1.1 版本核心信息
- 版本代号:Spring Cloud 2023.0.x,代号:Leyton(莱顿)
- 发布时间:2023年11月正式发布,当前最新稳定版为2023.0.3
- 兼容Spring Boot版本:Spring Boot 3.2.x(强制要求,不兼容3.1及以下版本)
- Java版本要求:Java 17及以上(完全基于Jakarta EE 9+规范,移除javax.*包)
- 依赖基础:Spring Boot 3.2.x,要求Java 17+,完全基于Jakarta EE 9+
- 核心定位:Spring官方微服务一站式解决方案,提供微服务架构全生命周期能力;云原生微服务架构的一站式解决方案,实现了从"Netflix组件主导"到"原生组件+多生态融合"的彻底转型
1.2 2023.0.x 重大变更与组件更新
| 组件 | 状态 | 替代方案 | 核心变化 |
|---|---|---|---|
| Spring Cloud Netflix | 部分移除 | Spring Cloud Alibaba/原生组件 | Eureka仍保留但进入维护模式;Hystrix、Ribbon、Zuul完全移除 |
| Spring Cloud Gateway | 核心组件 | - | 升级至4.1.x,支持Spring Boot 3.2,增强响应式能力 |
| Spring Cloud OpenFeign | 核心组件 | - | 升级至4.1.x,支持响应式Feign,集成Micrometer观测 |
| Spring Cloud CircuitBreaker | 核心组件 | - | 统一熔断抽象,默认实现为Resilience4j 2.x |
| Spring Cloud Config | 核心组件 | - | 增强Git后端支持,支持SSH密钥认证 |
| Spring Cloud Stream | 核心组件 | - | 升级至4.1.x,支持Kafka 3.6.x和RabbitMQ 3.12.x |
| Spring Cloud Kubernetes | 核心组件 | - | 大幅增强Kubernetes原生集成,支持服务发现、配置中心 |
| 被移除/废弃组件 | 官方推荐替代方案 | 核心优势 |
|---|---|---|
| Netflix Eureka | Spring Cloud Alibaba Nacos/Consul | 支持AP+CP模式切换,集成配置中心功能 |
| Netflix Hystrix | Spring Cloud Circuit Breaker(Resilience4j实现) | 更高性能,支持更多熔断策略,响应式编程支持 |
| Netflix Zuul 1.x | Spring Cloud Gateway | 基于Netty非阻塞架构,支持WebFlux,性能提升3-5倍 |
| Netflix Ribbon | Spring Cloud LoadBalancer | 原生集成Spring生态,支持响应式负载均衡 |
| Spring Cloud Config | Spring Cloud Alibaba Nacos Config/Apollo | 支持动态配置实时推送,配置变更无需重启服务 |
| Spring Cloud Sleuth | Micrometer Tracing | 统一观测标准,集成OpenTelemetry,支持更多追踪系统 |
1.3 2023.0.x 核心组件矩阵
- 服务治理:Spring Cloud Alibaba Nacos Discovery、Spring Cloud Consul
- 配置中心:Spring Cloud Alibaba Nacos Config、Spring Cloud Consul Config
- API网关:Spring Cloud Gateway 4.1.x
- 负载均衡:Spring Cloud LoadBalancer 4.1.x
- 熔断降级:Spring Cloud Circuit Breaker 3.1.x(默认Resilience4j 2.1.x)
- 消息驱动:Spring Cloud Stream 4.1.x(支持RabbitMQ、Kafka、RocketMQ)
- 分布式事务:Spring Cloud Alibaba Seata 1.7.x+
- 链路追踪:Micrometer Tracing 1.2.x(集成Zipkin、Jaeger)
- 云原生集成:Spring Cloud Kubernetes 3.1.x
1.4 2023.0.x 核心技术栈
- 服务治理:Eureka/Consul/Nacos
- 配置管理:Spring Cloud Config/Nacos Config
- 服务调用:OpenFeign/Reactive Feign
- 负载均衡:Spring Cloud LoadBalancer
- 熔断降级:Resilience4j
- API网关:Spring Cloud Gateway
- 消息驱动:Spring Cloud Stream
- 链路追踪:Micrometer Tracing + Zipkin/Jaeger
- 分布式事务:Seata(第三方集成)
二、微服务核心理论基础
2.1 微服务架构定义与本质
定义: 微服务是一种将单一应用程序拆分为一组小型、独立部署、松耦合的服务的架构风格,每个服务运行在自己的进程中,通过轻量级机制(通常是HTTP/REST或gRPC)通信,围绕具体业务能力构建,可以由独立的团队负责开发和维护。
本质:
- 业务解耦:按业务边界拆分,实现"高内聚、低耦合"
- 技术异构:不同服务可采用最适合的技术栈
- 独立部署:单个服务的修改和部署不影响其他服务
- 弹性扩展:可针对高负载服务单独进行水平扩展
- 故障隔离:单个服务的故障不会蔓延到整个系统
2.2 微服务架构演进历程
- 单体架构时代:所有功能打包在一个应用中,开发简单但维护困难,扩展性差
- SOA架构时代:面向服务的架构,通过ESB进行服务通信,过于复杂和重量级
- 微服务架构时代:轻量级通信,去中心化治理,强调业务能力和独立部署
- 云原生微服务时代:基于容器和Kubernetes,强调不可变基础设施、声明式API和自动化运维
2.3 微服务架构的核心优势
- 技术异构性:不同服务可选择最适合的技术栈
- 独立部署:单个服务的修改无需重新部署整个应用
- 故障隔离:一个服务的故障不会影响整个系统
- 团队自治:小团队可以独立负责一个或多个服务
- 可扩展性:可以针对高负载服务单独进行水平扩展
2.4 微服务架构引入的挑战
- 分布式系统复杂性:网络延迟、消息丢失、数据一致性问题
- 服务依赖管理:服务间依赖关系复杂,调用链跟踪困难
- 数据一致性:跨服务事务难以保证
- 运维复杂度:需要管理大量服务实例
- 测试难度增加:集成测试变得复杂
- 服务发现与注册
- 配置管理与动态更新
- API网关与路由
- 负载均衡
- 熔断降级与限流
- 分布式事务
- 链路追踪与监控
- 服务安全与认证授权
2.5 微服务架构设计原则
- 单一职责原则:每个服务只负责一个业务领域的功能
- 服务自治原则:服务拥有自己的数据,独立开发、测试、部署和运行
- 去中心化治理:避免集中式的服务总线和治理平台
- 数据去中心化:每个服务管理自己的数据库,避免共享数据库
- 容错设计原则:假设服务会失败,设计熔断、降级、重试等机制
- 演进式设计原则:允许架构随业务发展逐步演进和优化
三、CAP定理:分布式系统的根本约束
3.1 CAP定理核心定义
CAP定理由计算机科学家Eric Brewer于2000年提出,指出在一个分布式系统中,最多只能同时满足以下三个特性中的两个:
- 一致性(Consistency):所有节点在同一时间看到的数据是完全一致的。写操作完成后,所有后续的读操作都应该返回最新写入的值。
- 可用性(Availability):系统提供的服务必须一直处于可用状态,每次请求都能在有限时间内获得响应(不保证返回最新数据)。
- 分区容错性(Partition Tolerance):当系统中的网络出现分区(部分节点之间无法通信)时,系统仍然能够继续运行。
3.2 CAP定理的关键理解
- 分区容错性是分布式系统的必然要求:在分布式系统中,网络故障是不可避免的,因此P是必须满足的。这意味着分布式系统只能在CP和AP之间进行选择。
- CAP是在网络分区发生时的取舍:在没有网络分区的正常情况下,系统可以同时满足C和A。只有当网络分区发生时,才需要在C和A之间做出选择。
- CAP是对系统特性的极端描述:实际系统中,一致性和可用性都是程度问题,而不是非此即彼的二元选择。
3.3 CAP三特性的详细解析
3.3.1 一致性(Consistency)
- 强一致性:任何时刻所有节点的数据完全一致
- 弱一致性:允许数据存在短暂不一致,最终会达到一致
- 最终一致性:弱一致性的一种特殊形式,保证在没有新的更新操作的情况下,经过一段时间后,所有节点的数据会达到一致
- 实现方式:
- 写操作必须同步到所有节点
- 读操作必须从所有节点读取最新数据
- 使用分布式锁或共识算法(Paxos/Raft)
3.3.2 可用性(Availability)
- 定义:系统提供的服务必须一直处于可用状态,每次请求都能获得响应
- 衡量指标:
- 正常运行时间(Uptime)
- 平均无故障时间(MTBF)
- 平均恢复时间(MTTR)
- 实现方式:
- 服务冗余部署
- 负载均衡
- 故障自动转移
- 熔断降级机制
3.3.3 分区容错性(Partition tolerance)
- 定义:当系统中的节点之间出现网络分区时,系统仍然能够继续运行
- 网络分区:由于网络故障导致系统被分割成多个独立的部分,部分之间无法通信
- 实现方式:
- 数据多副本存储
- 异步复制
- 分区后的独立运行能力
3.4 CAP三种组合模式
CA模式:满足一致性和可用性,但不满足分区容错性。
- 特点:单点系统,没有网络分区问题
- 典型应用:传统关系型数据库(如MySQL单节点)
- 适用场景:对数据一致性要求极高,且可以接受单点故障的场景
CP模式:满足一致性和分区容错性,但牺牲可用性。
- 特点:当网络分区发生时,为了保证数据一致性,系统会拒绝部分请求,导致服务不可用
- 典型应用:ZooKeeper、Consul(强一致性模式)、HBase
- 适用场景:对数据一致性要求极高的场景,如金融交易、分布式锁
AP模式:满足可用性和分区容错性,但牺牲一致性。
- 特点:当网络分区发生时,系统仍然能够处理请求,但可能返回不一致的数据
- 典型应用:Eureka、Nacos(AP模式)、Cassandra
- 适用场景:对可用性要求极高,能够容忍短暂数据不一致的场景,如服务发现、电商商品展示
3.5 CAP定理的核心结论
- P是必须的:在分布式系统中,网络分区是不可避免的,因此分区容错性是必须满足的
- 只能在C和A之间权衡:当网络分区发生时,系统只能在一致性和可用性之间做出选择
- 没有完美的分布式系统:不存在同时满足CAP三个特性的分布式系统
3.6 CAP定理的常见误解
- 误解1:CAP定理适用于所有系统
- 纠正:CAP定理仅适用于分布式系统,单体系统不存在分区问题
- 误解2:C和A是绝对的二选一
- 纠正:C和A是程度问题,不是非此即彼的选择,可以在不同场景下进行不同程度的权衡
- 误解3:最终一致性就是放弃了一致性
- 纠正:最终一致性仍然保证了一致性,只是允许存在短暂的不一致
3.7 Spring Cloud组件的CAP取舍
| 组件 | CAP模式 | 核心特点 | 适用场景 |
|---|---|---|---|
| Nacos Discovery | 支持AP/CP切换 | 默认AP模式,支持服务健康检查和自动剔除;CP模式基于Raft算法实现强一致性 | 大多数微服务场景,需要高可用的服务发现 |
| Consul | CP(默认)/AP | 基于Raft算法实现强一致性,支持服务健康检查和多数据中心 | 对服务发现一致性要求较高的场景 |
| Eureka | AP | 纯AP模式,自我保护机制保证高可用,不保证强一致性 | 传统Spring Cloud微服务场景,已被官方废弃 |
| ZooKeeper | CP | 基于ZAB算法实现强一致性,可用性较差 | 分布式协调、配置管理场景 |
| Nacos Config | CP | 基于Raft算法实现配置数据的强一致性 | 配置中心场景,需要保证配置数据的一致性 |
四、BASE定理:CAP定理的实际落地
4.1 BASE定理核心定义
BASE定理是对CAP定理的延伸和补充,由eBay的架构师提出,是大规模分布式系统的实际设计原则。它指出分布式系统可以通过适当牺牲强一致性来获得高可用性,并最终达到数据一致性。
BASE是以下三个短语的缩写:
- 基本可用(Basically Available):系统在出现不可预知的故障时,允许损失部分可用性,保证核心功能可用。
- 软状态(Soft State):允许系统中的数据存在中间状态,并且这个中间状态不会影响系统的整体可用性。
- 最终一致性(Eventually Consistent):系统中的所有数据副本,在经过一段时间的同步后,最终能够达到一致的状态。
4.2 BASE定理的关键理解
- BASE是对CAP中AP方案的进一步细化:它明确了在牺牲强一致性的情况下,如何保证系统的可用性和最终一致性。
- 最终一致性是BASE的核心:系统不要求实时的强一致性,但保证在一定时间窗口内,所有数据副本最终会达到一致。
- BASE是面向业务的设计原则:它强调根据业务特点来选择合适的一致性级别,而不是盲目追求强一致性。
4.3 BASE与ACID的对比
ACID是传统关系型数据库的事务特性,强调强一致性;而BASE是分布式系统的设计原则,强调可用性和最终一致性。
| 特性 | ACID | BASE |
|---|---|---|
| 一致性 | 强一致性 | 最终一致性 |
| 可用性 | 牺牲可用性保证一致性 | 牺牲强一致性保证可用性 |
| 事务 | 原子性、隔离性 | 无原子性和隔离性保证 |
| 适用场景 | 传统单体应用、金融交易 | 大规模分布式系统、互联网应用 |
4.4 BASE三特性的详细解析
4.4.1 基本可用(Basically Available)
- 定义:系统在出现不可预知的故障时,允许损失部分可用性,但保证核心功能可用
- 常见实现方式:
- 响应时间损失:正常情况下0.5秒响应,故障情况下允许2秒响应
- 功能降级:故障情况下关闭非核心功能,保证核心功能正常运行
- 流量削峰:通过排队、限流等方式控制流量,保证系统不被压垮
- 服务熔断:当依赖服务不可用时,直接返回默认值或错误信息
4.4.2 软状态(Soft State)
- 定义:允许系统中的数据存在中间状态,并且这个中间状态不会影响系统的整体可用性
- 本质:数据的状态可以在不同节点之间存在短暂的不一致
- 常见例子:
- 订单的"待支付"状态
- 库存的"预扣减"状态
- 消息队列中的未处理消息
4.4.3 最终一致性(Eventually Consistent)
- 定义:系统中的所有数据副本,在经过一段时间的同步后,最终能够达到一致的状态
- 最终一致性的分类:
- 因果一致性:如果进程A通知进程B它更新了一个数据,那么进程B后续的访问将看到A更新的最新值
- 读己之所写一致性:进程A更新一个数据后,它自己总是能看到更新后的最新值
- 会话一致性:在同一个会话中,用户总是能看到自己更新的最新值
- 单调读一致性:如果一个进程已经读取了某个数据的某个版本,那么它后续不会读取到比这个版本更旧的数据
- 单调写一致性:系统保证来自同一个进程的写操作被顺序执行
4.5 最终一致性的五种实现方式
- 读己之所写(Read Your Writes):用户写入数据后,立即能读到自己写入的数据。
- 单调读(Monotonic Reads):用户一旦读到某个数据的某个版本,后续不会读到比这个版本更旧的数据。
- 单调写(Monotonic Writes):系统保证来自同一个用户的写操作按顺序执行。
- 因果一致性(Causal Consistency):有因果关系的写操作必须被所有节点按相同的顺序看到。
- 最终一致性(Eventual Consistency):所有写操作最终会被所有节点看到,是最弱的一致性级别。
4.6 BASE定理与CAP定理的关系
- BASE定理是CAP定理的实际落地:CAP定理是理论上的约束,BASE定理是在实际工程中如何在这个约束下设计系统
- BASE定理牺牲了强一致性,换取了可用性和分区容错性:在大多数互联网应用中,可用性比强一致性更重要
- BASE定理不是否定CAP定理:而是在CAP定理的基础上,提出了一种更适合大规模分布式系统的设计思路
五、Spring Cloud 2023.0.x 对CAP/BASE的实现与权衡
5.1 Spring Cloud 整体架构的CAP权衡
- Spring Cloud默认采用AP架构:优先保证可用性和分区容错性,牺牲强一致性,采用最终一致性
- 核心原因:
- 互联网应用对可用性要求极高
- 强一致性会严重影响系统性能和可用性
- 大多数业务场景可以接受最终一致性
5.2 各核心组件的CAP特性分析
5.2.1 服务注册中心
| 组件 | CAP特性 | 实现原理 | 适用场景 |
|---|---|---|---|
| Eureka | AP | 基于Distro协议(心跳)的服务注册与发现,数据异步复制,允许数据不一致 | 对可用性要求高,允许短暂服务发现不一致的场景 |
| Consul | CP | 基于Raft共识算法,强一致性,数据同步复制 | 对服务发现一致性要求高的场景 |
| Nacos | AP/CP可选 | 默认AP模式,支持切换为CP模式 | 大多数场景使用AP模式,特殊场景可切换为CP模式 |
Spring Cloud 2023.0.x推荐:Nacos作为服务注册中心,提供AP/CP双模式支持,灵活性更高
服务发现:Nacos的AP/CP双模式
Nacos是Spring Cloud Alibaba的核心组件,支持AP和CP两种模式的切换,是Spring Cloud 2023.0.x官方推荐的服务发现和配置中心解决方案。
AP模式(默认):
- 基于Distro协议实现,保证服务发现的高可用性
- 服务注册信息最终一致,适合大多数微服务场景
- 支持服务健康检查和自动剔除,保证服务列表的准确性
CP模式:
- 基于Raft算法实现,保证服务注册信息的强一致性
- 当网络分区发生时,会牺牲部分可用性来保证数据一致性
- 适合对服务发现一致性要求较高的场景,如金融系统
5.2.2 配置中心
| 组件 | CAP特性 | 实现原理 | 适用场景 |
|---|---|---|---|
| Spring Cloud Config | AP | 基于Git/SVN等后端存储,配置拉取模式,允许短暂不一致 | 对配置一致性要求不高的场景 |
| Nacos Config | AP/CP可选 | 默认AP模式,支持切换为CP模式 | 大多数场景使用AP模式,关键配置可使用CP模式 |
| Apollo | AP | 基于数据库存储,配置推送模式,最终一致性 | 对配置实时性要求高的场景 |
Spring Cloud 2023.0.x推荐:Nacos Config或Apollo,提供更好的配置管理体验和实时性
配置中心:Nacos Config的强一致性
Nacos Config采用CP模式,基于Raft算法实现配置数据的强一致性。当配置发生变更时,Nacos会将变更推送给所有订阅该配置的服务,保证所有服务最终使用相同的配置。
- 配置变更流程:
- 用户通过Nacos控制台或API修改配置
- Nacos服务器将配置变更写入Raft集群,保证强一致性
- Nacos服务器通过长连接将配置变更推送给所有订阅该配置的客户端
- 客户端收到配置变更后,更新本地缓存并应用新配置
5.2.3 分布式缓存
- Redis:AP架构,主从异步复制,哨兵模式保证高可用,集群模式提供分区容错性
- Spring Data Redis:提供Redis的集成支持,实现缓存的读写操作
- 缓存一致性问题:
- 先更新数据库,再更新缓存
- 先更新数据库,再删除缓存(推荐)
- 先删除缓存,再更新数据库
- 延迟双删策略
5.2.4 消息队列
- Kafka/RabbitMQ:AP架构,数据多副本存储,异步复制,最终一致性
- Spring Cloud Stream:提供消息队列的统一抽象,简化消息驱动微服务的开发
- 消息队列的作用:
- 解耦服务间的依赖
- 异步处理非核心业务
- 削峰填谷,提高系统可用性
- 实现最终一致性
5.2.5 分布式事务
- Spring Cloud 2023.0.x本身不提供分布式事务解决方案,推荐集成第三方组件Seata
- Seata的三种模式:
- AT模式:自动事务模式,基于本地事务+补偿机制,最终一致性
- TCC模式:Try-Confirm-Cancel模式,手动实现事务逻辑,最终一致性
- SAGA模式:长事务模式,适用于跨多个服务的长事务,最终一致性
- 核心思想:所有分布式事务解决方案都是基于最终一致性,没有强一致性的分布式事务
分布式事务:Seata的最终一致性实现
Seata是Spring Cloud Alibaba提供的分布式事务解决方案,支持AT、TCC、SAGA和XA四种事务模式,其中AT模式是最常用的模式,基于最终一致性实现。
AT模式核心原理:
- 一阶段:业务数据和回滚日志在同一个本地事务中提交
- 二阶段:如果所有分支事务都成功,则异步删除回滚日志;如果有分支事务失败,则通过回滚日志进行补偿
BASE思想体现:
- 基本可用:一阶段提交后,业务数据已经可见,系统可以继续处理其他请求
- 软状态:在二阶段完成前,数据处于中间状态
- 最终一致性:二阶段完成后,所有分支事务的数据最终会达到一致
5.3 Spring Cloud 实现最终一致性的核心机制
5.3.1 异步通信
- OpenFeign异步调用:支持CompletableFuture返回值
- Reactive Feign:基于Reactor的响应式调用
- 消息队列:通过消息队列实现异步通信
5.3.2 重试机制
- Spring Retry:提供声明式重试支持
- Resilience4j Retry:与Spring Cloud CircuitBreaker集成
- 重试策略:固定间隔、指数退避、随机间隔
5.3.3 熔断降级
- Resilience4j CircuitBreaker:Spring Cloud 2023.0.x默认的熔断实现
- 熔断状态:关闭、打开、半打开
- 降级策略:返回默认值、调用备用服务、返回缓存数据
熔断降级:Resilience4j的容错设计
Resilience4j是Spring Cloud Circuit Breaker的默认实现,是一个轻量级的容错库,完全符合BASE定理的设计思想。
核心容错机制:
- 熔断:当服务调用失败率达到阈值时,自动熔断该服务的调用,避免故障蔓延
- 降级:当服务熔断或调用失败时,返回预设的降级结果,保证系统基本可用
- 限流:限制服务的并发请求数,防止服务被压垮
- 重试:当服务调用失败时,自动重试一定次数,提高系统可用性
- 超时:为服务调用设置超时时间,避免长时间等待
BASE思想体现:
- 基本可用:通过降级机制保证系统核心功能可用
- 软状态:允许服务调用失败,返回降级结果
- 最终一致性:当服务恢复正常后,系统会自动恢复正常调用
5.3.4 幂等性设计
- 定义:同一个操作执行多次和执行一次的效果相同
- 实现方式:
- 唯一ID
- 数据库唯一约束
- 乐观锁
- 分布式锁
六、Spring Cloud 2023.0.x 微服务架构最佳实践
6.1 CAP/BASE权衡的最佳实践
- 优先选择AP架构:除非有特殊的强一致性需求,否则优先保证可用性和分区容错性
- 关键业务场景使用最终一致性:大多数业务场景可以接受最终一致性
- 强一致性场景使用CP组件:如金融交易、订单支付等场景
- 避免过度追求一致性:强一致性会严重影响系统性能和可用性
6.2 服务拆分最佳实践
- 基于业务领域拆分:使用DDD的限界上下文进行服务拆分
- 单一职责原则:每个服务只负责一个业务领域
- 避免过度拆分:过度拆分会增加系统复杂度和运维成本
- 服务粒度适中:服务粒度太小会导致服务间调用过多,太大则失去微服务的优势
6.3 数据管理最佳实践
- 去中心化数据管理:每个服务拥有自己的数据库
- 避免跨服务数据库查询:通过服务调用获取数据
- 使用最终一致性:跨服务事务使用消息队列或分布式事务组件实现最终一致性
- 缓存设计:合理使用缓存提高系统性能,注意缓存一致性问题
6.4 弹性设计最佳实践
- 熔断降级:使用Resilience4j实现熔断降级
- 限流:使用Resilience4j RateLimiter或Sentinel实现限流
- 隔离:使用舱壁模式隔离不同的服务调用
- 超时控制:为所有服务调用设置合理的超时时间
6.5 可观测性最佳实践
- 日志:使用SLF4J+Logback实现统一日志管理
- 指标:使用Micrometer收集系统指标
- 链路追踪:使用Micrometer Tracing+Zipkin/Jaeger实现分布式链路追踪
- 监控告警:使用Prometheus+Grafana实现监控告警
6.6 基于CAP/BASE的组件选型原则
- 服务发现:优先选择Nacos AP模式,除非对一致性有极高要求才使用CP模式
- 配置中心:优先选择Nacos Config,保证配置数据的强一致性
- API网关:使用Spring Cloud Gateway,基于非阻塞架构提供高可用的路由服务
- 熔断降级:使用Resilience4j,实现轻量级的容错处理
- 分布式事务:优先使用Seata AT模式,对于复杂场景可以考虑TCC或SAGA模式
6.7 微服务拆分原则
- 按业务边界拆分:使用领域驱动设计(DDD)的方法,按限界上下文拆分服务
- 单一职责:每个服务只负责一个业务领域的功能
- 服务粒度适中:避免过粗导致耦合度高,也避免过细导致系统复杂度增加
- 数据去中心化:每个服务管理自己的数据库,避免共享数据库
6.8 分布式系统一致性保障策略
- 优先使用最终一致性:对于大多数业务场景,最终一致性已经能够满足需求
- 强一致性场景使用分布式事务:对于金融交易等对一致性要求极高的场景,使用Seata等分布式事务解决方案
- 使用分布式锁保证并发安全:对于需要保证原子性的操作,使用Redis或ZooKeeper实现分布式锁
- 设计补偿机制:对于可能出现的数据不一致情况,设计定时任务或人工补偿机制
6.9 高可用设计原则
- 服务多实例部署:每个服务至少部署3个实例,避免单点故障
- 跨可用区部署:将服务实例部署在不同的可用区,提高系统的容灾能力
- 熔断降级:为所有服务调用配置熔断降级机制,防止故障蔓延
- 限流:为核心接口配置限流机制,防止系统被突发流量压垮
- 监控告警:建立完善的监控告警体系,及时发现和处理系统故障
七、总结与展望
7.1 核心知识总结
- CAP定理:分布式系统最多只能同时满足一致性、可用性和分区容错性中的两个,分区容错性是必须的
- BASE定理:基本可用、软状态、最终一致性,是大规模分布式系统的实际设计原则
- Spring Cloud 2023.0.x:默认采用AP架构,优先保证可用性和分区容错性,通过各种机制实现最终一致性
- 核心组件:服务注册中心、配置中心、API网关、熔断降级、消息队列、分布式事务等
7.2 未来发展趋势
- 云原生:Spring Cloud将进一步增强对Kubernetes的原生支持
- 服务网格:Istio等服务网格技术将与Spring Cloud深度集成
- 响应式编程:响应式编程将成为微服务开发的主流
- AI集成:Spring AI将与Spring Cloud深度集成,提供AI能力支持
- 可观测性:可观测性将成为微服务架构的核心能力
Spring Cloud 2023.0.x 微服务与CAP/BASE定理 面试高频问答卡片
一、Spring Cloud 2023.0.x 整体概览
Q1: Spring Cloud 2023.0.x的版本核心信息是什么?
答案:
- 版本代号:Leyton(莱顿)
- 发布时间:2023年11月正式发布,最新稳定版2023.0.3
- 强制兼容:Spring Boot 3.2.x(不兼容3.1及以下)
- Java要求:Java 17及以上
- 技术基础:完全基于Jakarta EE 9+规范,移除所有javax.*包
- 核心转型:从"Netflix组件主导"到"原生组件+多生态融合"
Q2: Spring Cloud 2023.0.x中哪些Netflix组件被完全移除了?
答案:
- Hystrix(熔断器)
- Ribbon(客户端负载均衡)
- Zuul 1.x(API网关)
- Eureka仍保留但进入维护模式
Q3: Spring Cloud 2023.0.x中被移除组件的官方推荐替代方案是什么?
答案:
- Hystrix → Spring Cloud Circuit Breaker(默认Resilience4j 2.x)
- Ribbon → Spring Cloud LoadBalancer
- Zuul 1.x → Spring Cloud Gateway
- Eureka → Nacos/Consul
- Spring Cloud Sleuth → Micrometer Tracing
Q4: Spring Cloud 2023.0.x的核心组件矩阵是什么?
答案:
- 服务治理:Nacos Discovery、Consul
- 配置中心:Nacos Config、Consul Config
- API网关:Spring Cloud Gateway 4.1.x
- 负载均衡:Spring Cloud LoadBalancer 4.1.x
- 熔断降级:Spring Cloud Circuit Breaker 3.1.x(Resilience4j)
- 消息驱动:Spring Cloud Stream 4.1.x
- 分布式事务:Seata 1.7.x+
- 链路追踪:Micrometer Tracing 1.2.x
- 云原生集成:Spring Cloud Kubernetes 3.1.x
二、微服务核心理论基础
Q5: 什么是微服务架构?它的本质是什么?
答案:
- 定义:将单一应用拆分为一组小型、独立部署、松耦合的服务,每个服务运行在自己的进程中,通过轻量级机制通信,围绕具体业务能力构建,由独立团队负责。
- 本质:业务解耦、技术异构、独立部署、弹性扩展、故障隔离。
Q6: 微服务架构引入了哪些挑战?
答案:
- 分布式系统复杂性(网络延迟、消息丢失、数据一致性)
- 服务依赖管理复杂,调用链跟踪困难
- 跨服务数据一致性难以保证
- 运维复杂度大幅提升(管理大量服务实例)
- 集成测试难度增加
- 需要额外解决服务发现、配置管理、API网关、熔断降级、链路追踪等问题
Q7: 微服务架构的核心设计原则是什么?
答案:
- 单一职责原则:每个服务只负责一个业务领域
- 服务自治原则:服务拥有自己的数据,独立开发、测试、部署
- 去中心化治理:避免集中式服务总线
- 数据去中心化:每个服务管理自己的数据库
- 容错设计原则:假设服务会失败,设计熔断、降级、重试机制
- 演进式设计原则:允许架构随业务发展逐步优化
三、CAP定理
Q8: 什么是CAP定理?
答案:
CAP定理由Eric Brewer于2000年提出,指出在一个分布式系统中,最多只能同时满足以下三个特性中的两个:
- 一致性(C):所有节点在同一时间看到的数据完全一致
- 可用性(A):每次请求都能在有限时间内获得响应
- 分区容错性(P):当网络出现分区时,系统仍然能够继续运行
Q9: 为什么说分布式系统只能在CP和AP之间选择?
答案:
因为在分布式系统中,网络故障是不可避免的,分区容错性(P)是必须满足的。这意味着当网络分区发生时,系统只能在一致性(C)和可用性(A)之间做出选择。
Q10: CAP定理的三种组合模式分别是什么?各有什么典型应用?
答案:
- CA模式:满足一致性和可用性,不满足分区容错性。典型应用:传统关系型数据库单节点。
- CP模式:满足一致性和分区容错性,牺牲可用性。典型应用:ZooKeeper、Consul(默认)、HBase。
- AP模式:满足可用性和分区容错性,牺牲一致性。典型应用:Eureka、Nacos(默认)、Cassandra。
Q11: 关于CAP定理有哪些常见误解?
答案:
- 误解1:CAP适用于所有系统。纠正:仅适用于分布式系统。
- 误解2:C和A是绝对的二选一。纠正:C和A是程度问题,可以在不同场景下权衡。
- 误解3:最终一致性就是放弃了一致性。纠正:最终一致性仍然保证一致性,只是允许短暂不一致。
四、BASE定理
Q12: 什么是BASE定理?
答案:
BASE定理是对CAP定理的延伸和补充,是大规模分布式系统的实际设计原则。它指出分布式系统可以通过适当牺牲强一致性来获得高可用性,并最终达到数据一致性。
- 基本可用(Basically Available):故障时允许损失部分可用性,保证核心功能可用
- 软状态(Soft State):允许数据存在中间状态,且不影响系统整体可用性
- 最终一致性(Eventually Consistent):所有数据副本经过一段时间同步后,最终能够达到一致
Q13: BASE定理与ACID有什么区别?
答案:
| 特性 | ACID | BASE |
|---|---|---|
| 一致性 | 强一致性 | 最终一致性 |
| 可用性 | 牺牲可用性保证一致性 | 牺牲强一致性保证可用性 |
| 事务 | 原子性、隔离性 | 无原子性和隔离性保证 |
| 适用场景 | 传统单体应用、金融交易 | 大规模分布式系统、互联网应用 |
Q14: 最终一致性有哪几种常见类型?
答案:
- 因果一致性:有因果关系的写操作必须被所有节点按相同顺序看到
- 读己之所写一致性:用户写入数据后,立即能读到自己写入的数据
- 会话一致性:在同一个会话中,用户总是能看到自己更新的最新值
- 单调读一致性:用户一旦读到某个数据的某个版本,后续不会读到更旧的版本
- 单调写一致性:系统保证来自同一个用户的写操作按顺序执行
五、Spring Cloud组件的CAP/BASE特性
Q15: Spring Cloud整体架构采用什么CAP模式?为什么?
答案:
Spring Cloud默认采用AP架构,优先保证可用性和分区容错性,牺牲强一致性,采用最终一致性。
- 核心原因:
- 互联网应用对可用性要求极高
- 强一致性会严重影响系统性能和可用性
- 大多数业务场景可以接受最终一致性
Q16: Nacos支持哪两种CAP模式?分别适用于什么场景?
答案:
Nacos支持AP和CP两种模式切换:
- AP模式(默认):基于Distro协议实现,保证服务发现的高可用性,服务注册信息最终一致。适用于大多数微服务场景。
- CP模式:基于Raft算法实现,保证服务注册信息的强一致性,网络分区时会牺牲部分可用性。适用于对服务发现一致性要求较高的场景,如金融系统。
Q17: 常见服务注册中心的CAP特性对比是什么?
答案:
| 组件 | CAP模式 | 核心特点 |
|---|---|---|
| Eureka | AP | 纯AP模式,自我保护机制保证高可用 |
| Consul | CP(默认) | 基于Raft算法,强一致性,支持多数据中心 |
| Nacos | AP/CP可选 | 默认AP模式,灵活性最高 |
| ZooKeeper | CP | 基于ZAB算法,强一致性,可用性较差 |
Q18: Spring Cloud中实现最终一致性的核心机制有哪些?
答案:
- 异步通信:OpenFeign异步调用、Reactive Feign、消息队列
- 重试机制:Spring Retry、Resilience4j Retry
- 熔断降级:Resilience4j CircuitBreaker
- 幂等性设计:唯一ID、数据库唯一约束、乐观锁、分布式锁
Q19: Resilience4j如何体现BASE定理的设计思想?
答案:
- 基本可用:通过降级机制保证系统核心功能可用,即使依赖服务失败
- 软状态:允许服务调用失败,返回降级结果,系统继续运行
- 最终一致性:当服务恢复正常后,系统会自动恢复正常调用,数据最终一致
Q20: Seata分布式事务如何体现BASE定理?
答案:
Seata的所有事务模式(AT、TCC、SAGA)都是基于最终一致性实现的:
- 基本可用:一阶段提交后,业务数据已经可见,系统可以继续处理其他请求
- 软状态:在二阶段完成前,数据处于中间状态
- 最终一致性:二阶段完成后,所有分支事务的数据最终会达到一致
六、最佳实践与架构设计
Q21: 在微服务架构中如何进行CAP/BASE权衡?
答案:
- 优先选择AP架构,除非有特殊的强一致性需求
- 大多数业务场景使用最终一致性即可满足需求
- 强一致性场景(如金融交易、订单支付)使用CP组件
- 避免过度追求一致性,强一致性会严重影响系统性能和可用性
Q22: 微服务数据管理的最佳实践是什么?
答案:
- 去中心化数据管理:每个服务拥有自己的数据库
- 避免跨服务数据库查询:通过服务调用获取数据
- 使用最终一致性:跨服务事务使用消息队列或分布式事务组件
- 合理使用缓存:注意缓存一致性问题,推荐"先更新数据库,再删除缓存"策略
Q23: 基于CAP/BASE的Spring Cloud组件选型原则是什么?
答案:
- 服务发现:优先选择Nacos AP模式,特殊场景使用CP模式
- 配置中心:优先选择Nacos Config,保证配置数据的强一致性
- API网关:使用Spring Cloud Gateway,基于非阻塞架构提供高可用路由
- 熔断降级:使用Resilience4j,实现轻量级容错处理
- 分布式事务:优先使用Seata AT模式,复杂场景考虑TCC或SAGA模式
Q24: 微服务高可用设计的核心原则是什么?
答案:
- 服务多实例部署:每个服务至少部署3个实例
- 跨可用区部署:提高系统容灾能力
- 熔断降级:为所有服务调用配置熔断降级机制
- 限流:为核心接口配置限流机制
- 监控告警:建立完善的监控告警体系,及时发现和处理故障

