
北京时间 4 月 24 日 凌晨,OpenAI 正式发布新一代旗舰模型——GPT-5.5。官方介绍中,OpenAI 给的定义非常直接:
We’re releasing GPT‑5.5, our smartest and most intuitive to use model yet, and the next step toward a new way of getting work done on a computer.
GPT-5.5——这是我们迄今为止最聪明、最易上手的模型,也宣告我们朝着一种全新的人机协作方式迈出重要一步。

核心能力全面升级,Agent 能力成为主轴
从官方公布的数据来看,GPT-5.5 这次不只是单项能力提升,而是在多个核心性能上形成了系统性进步。

按照官方文档,GPT-5.5 的提升主要集中在 Agentic coding、Knowledge work、Scientific research、Long context、推理效率和 Cybersecurity 等方向。数据较 GPT-5.4 有明显提升,并在多个项目上领先于老对手 Claude Opus 4.7 和 Gemini 3.1 Pro:
Terminal-Bench 2.0 基准测试中,达到 82.7%,显著高于 GPT-5.4 的 75.1%;
GDPval 拿到 84.9%,领先 Claude Opus 4.7 和 Gemini 3.1 Pro;
OSWorld-Verified 达到 78.7%,超过 GPT-5.4,也略高于 Claude Opus 4.7;
在 FrontierMath Tier 4 这类高难数学任务上,GPT-5.5 也从 GPT-5.4 的 27.1% 提升到 35.4%。

在 Artificial Analysis 的测评中,GPT-5.5 综合能力已重新领跑:
在 Artificial Analysis Intelligence Index 上领先上周发布的 Claude Opus 4.7 约 3 分(60分 VS 57分);
打破 OpenAI GPT-5.4 (xhigh) / Anthropic Claude Opus 4.7 (max) / Google Gemini 3.1 Pro Preview 三方并列第一的局面(57分)
如果说 GPT-5.5 的总方向是“更会完成任务”,那么最先体现出这种变化的,还是编程。
Agentic coding

Agentic coding 是 GPT-5.5 最核心的亮点之一。OpenAI 称其为目前最强 Agentic Coding 模型。
它不只是 Coding 工具,而是能在 Codex 中承担更完整工程任务链:功能实现、代码重构、调试、测试、验证,甚至在大型代码库中持续代码迭代。GPT-5.5 的编程成绩全面高于 GPT-5.4:
Terminal-Bench 2.0:82.7%,高于 GPT-5.4 的 75.1%
SWE-Bench Pro:58.6%
Expert-SWE(Internal):73.1%,高于 GPT-5.4 的 68.5%
其中,Terminal-Bench 2.0 考察复杂命令行工作流中的规划、迭代和工具协同能力;SWE-Bench Pro 面向真实 GitHub issue 解决;Expert-SWE 则是 OpenAI 内部长周期工程任务评测。
knowledge work & computer use:AI 开始真正「用电脑」

GPT-5.5 的第二个关键提升,是从编程扩展到更广泛的 knowledge work 和 computer use。
面对复杂任务,GPT-5.5 可自行规划、调用工具、检查结果,并跨工具推进到完成。在相关评测中,其表现突出:
GDPval( wins or ties) : 84.9%
OSWorld-Verified: 78.7%
Tau2-bench Telecom:98.0%,且是在 without prompt tuning 情况下取得
MMMU Pro( with tools) : 83.2%
MCP Atlas: 75.3%
Toolathlon: 55.6%
这些指标覆盖了专业知识工作、真实电脑环境操作、复杂客服流程、工具调用和多模态任务。结合 Codex 的 computer use 能力,GPT-5.5 已经不只是生成文本,而是能够看屏幕、点击、输入、导航界面,在不同软件和工具之间移动,逐步形成“视觉—语言—动作”的闭环。
Scientific research:从信息检索走向「研究协作」


GPT-5.5 在 early scientific research 场景中的能力也有明显增强。数据显示,其科研与高难推理能力相比 GPT-5.4 明显提升:
GeneBench:25.0%(GPT-5.4:19.0%)
BixBench:80.5%(GPT-5.4:74.0%)
GPT-5.5 甚至参与发现了一个关于拉姆齐数的新证明,并已在 Lean 中验证。其能力已开始从“解释知识”走向“产生新知识”。
Long context:百万级窗口更接近实用
GPT-5.5 在上下文能力上进一步提升,API 最高支持 1M token context window,Codex 提供 400K context window。更关键的还在于它的准确性,根据 OpenAI MRCR v2 8-needle 测试,GPT-5.5 在不同长度区间表现如下:
4K–8K:98.1%
128K–256K:87.5%
512K–1M:74.0%
相比之下,GPT-5.4 在 512K–1M 区间仅为 36.6%。
推理效率:模型与基础设施的协同升级
GPT-5.5 在能力提升的同时,依然维持了接近 GPT-5.4 的服务速度。OpenAI 表示,其在真实环境中的 per-token latency 基本持平,但整体智能水平更高。
在效率上,GPT-5.5 在 Codex 任务中用更少 token 完成相同的工作,减少重复尝试和冗余输出。
基础设施层面,GPT-5.5 基于 NVIDIA GB200 和 GB300 NVL72 systems 协同设计与部署,推理系统也进行了整体重构。通过 Codex 分析生产流量并生成自定义负载均衡与分区算法,token 生成速度提升超 20%。
同时,GPT-5.5 还参与了推理栈关键优化的发现与实现,使得模型能力与系统效率得以协同提升。
安全能力:安全机制升级


随着能力增强,GPT-5.5 也配套更严格的安全机制。OpenAI 表示,这是截至目前最强的一套 safeguards,并经过完整安全评估、红队测试及约 200 个早期合作伙伴验证:
CyberGym:81.8%(GPT-5.4:79.0%,Claude Opus 4.7:73.1%)
CTF(Internal):88.1%(GPT-5.4:83.7%)
数据说明了 GPT-5.5 的上限,但真正的产品体验,还得看具体任务里能不能稳定交付。
案例一:GPT-5.5 跑一个 CSS-only 烟花
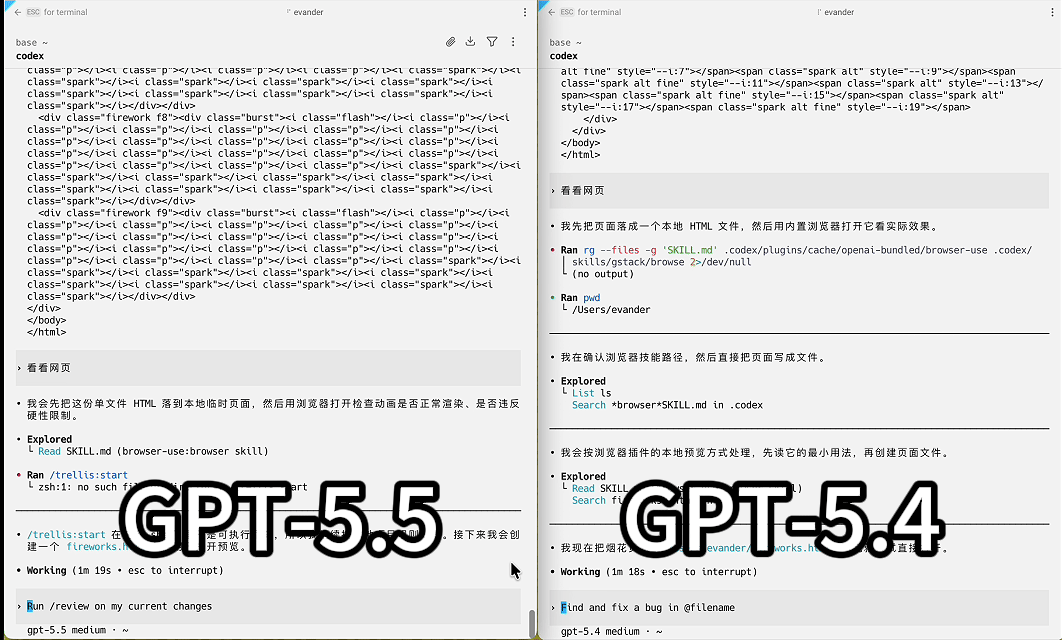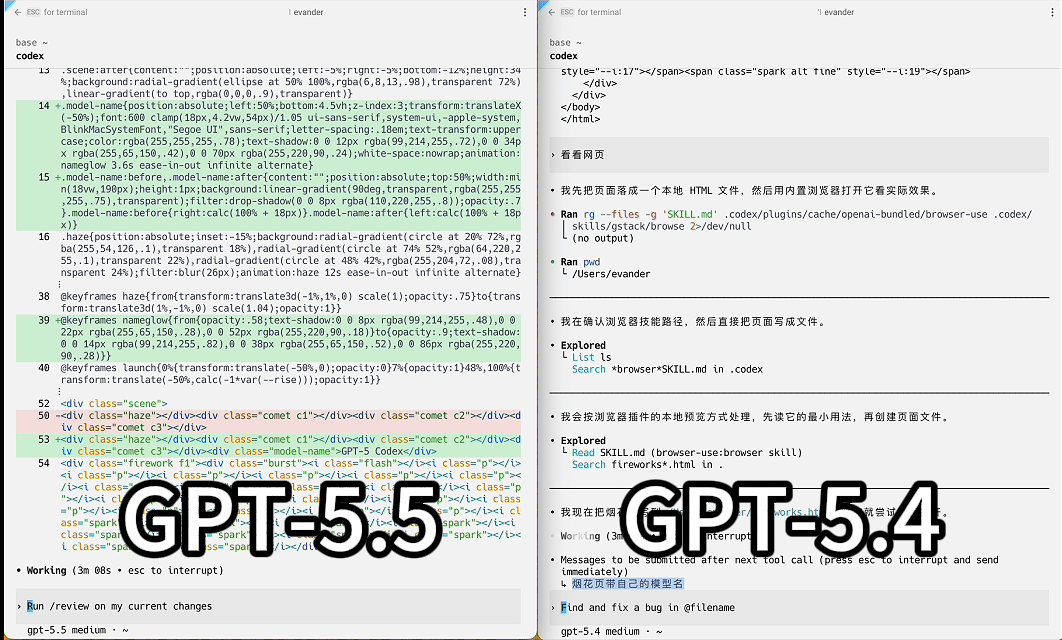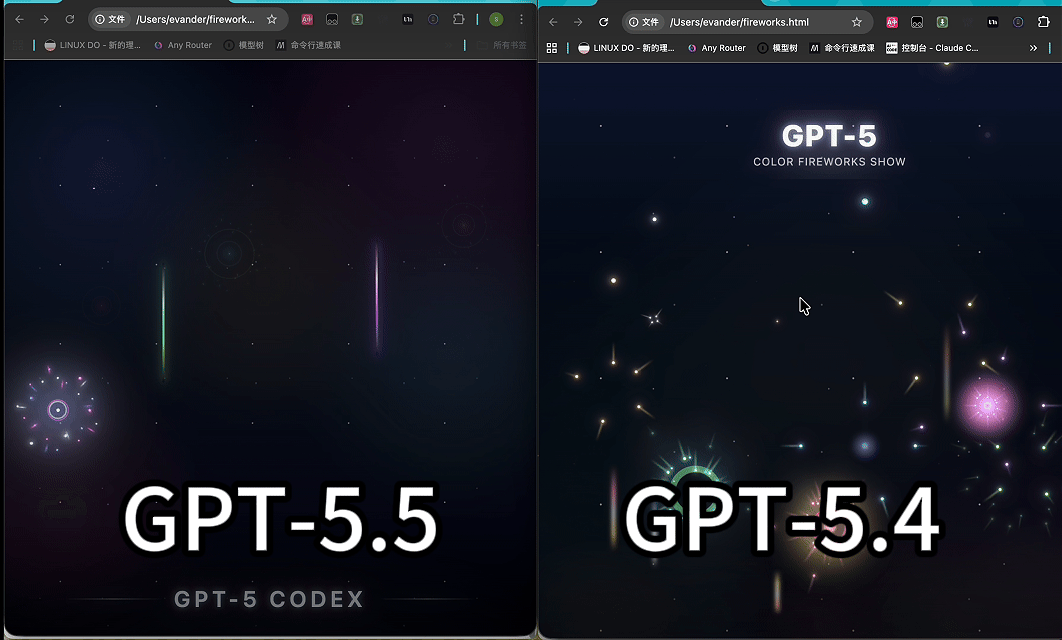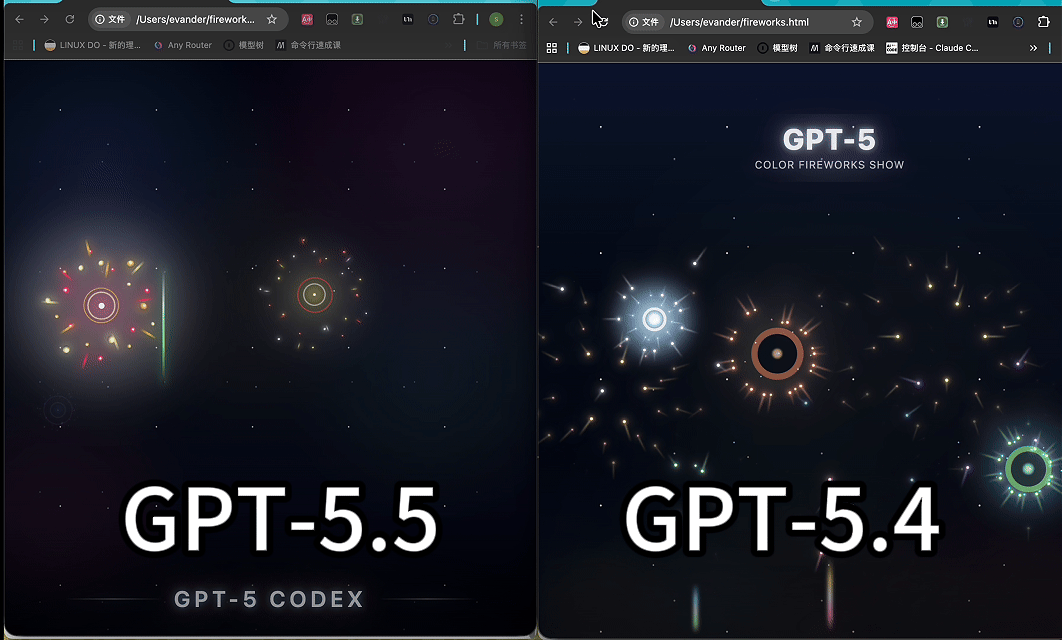
我们让 GPT-5.4 和 GPT-5.5 用同一个 prompt,生成一个“满屏彩色烟花秀”的单文件 HTML。
约束:只能使用 HTML 和 CSS,禁止 JavaScript、Canvas、SVG 及任何第三方库。烟花的升空、爆炸、散开、闪烁全靠 CSS 实现。这极度考验模型对 CSS 关键帧和渲染机制的理解。
这个测试主要看三点:
模型是否严格遵守 CSS-only 约束
烟花是否真的有升空、爆炸、消散过程
画面是否有层次、节奏和氛围,而不是几个简单圆点
两款模型均按要求输出了纯 CSS 代码。从代码结构看,GPT-5.5 的实现更偏向利用 CSS 动画节奏、阴影和缓动曲线来塑造烟花的扩散与下坠感,视觉层次相对更自然。
如果说烟花测试考验的是强约束下的动效实现,那么第二个案例更接近真实产品开发:
案例二: GPT-5.5 做的微信红包真不真?
90 秒快闪:GPT-5.4 VS GPT-5.5,谁做的微信红包更像真的?
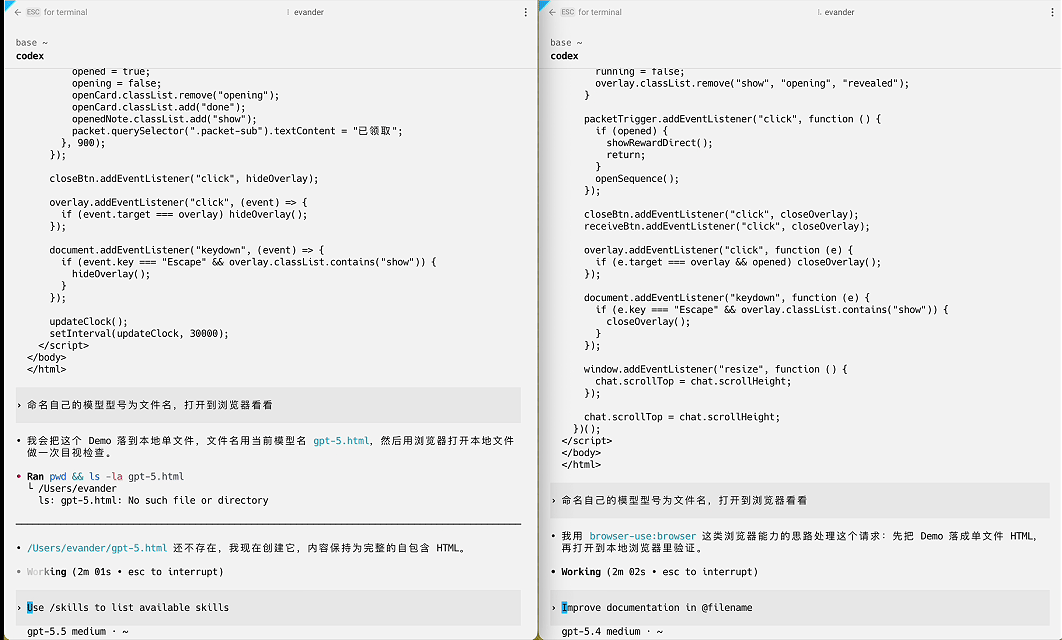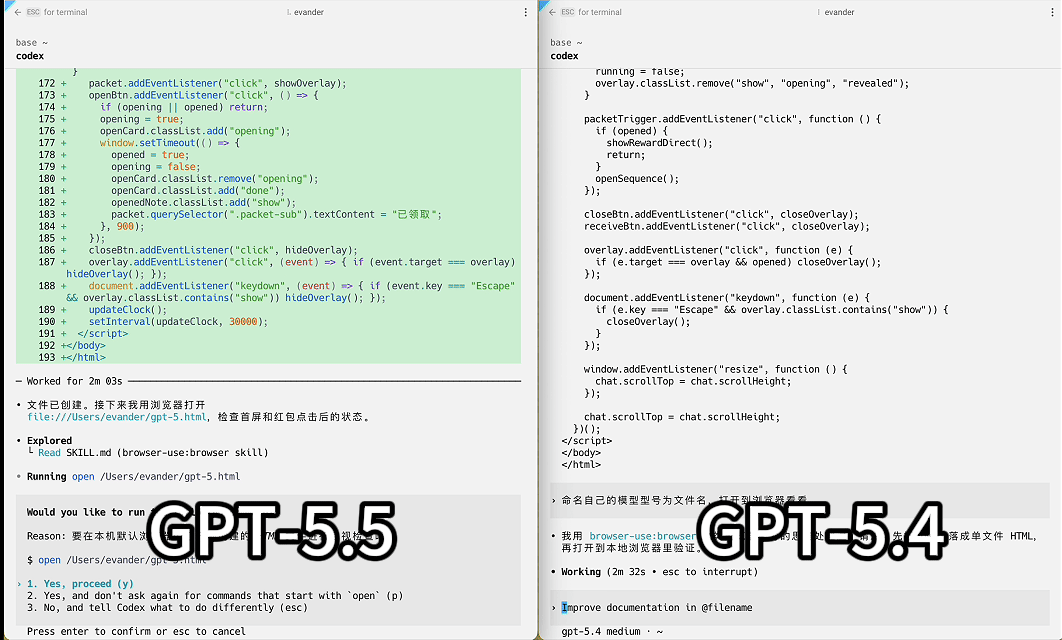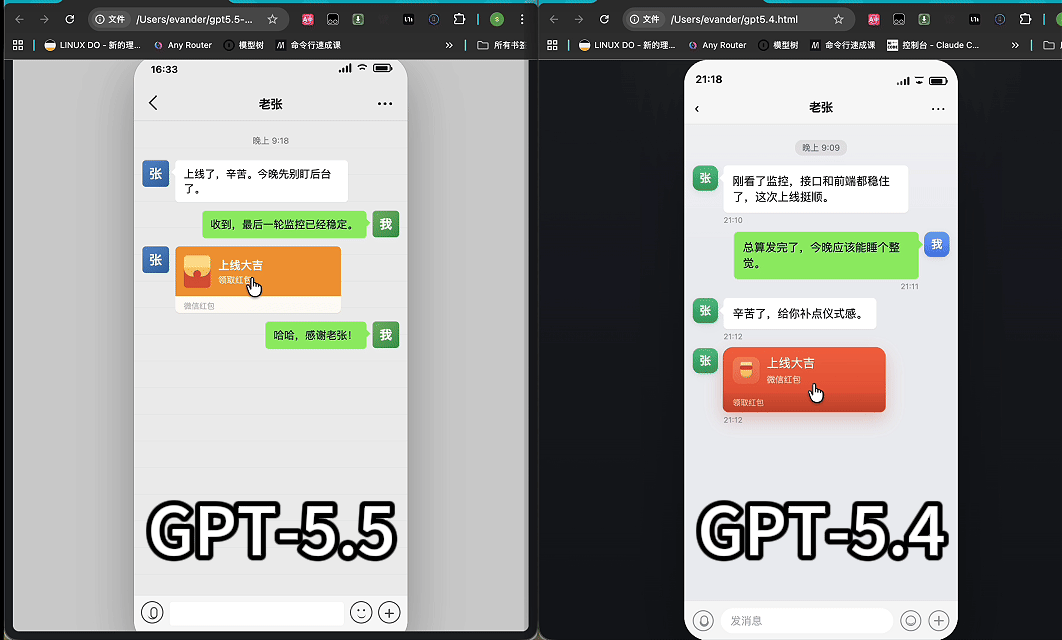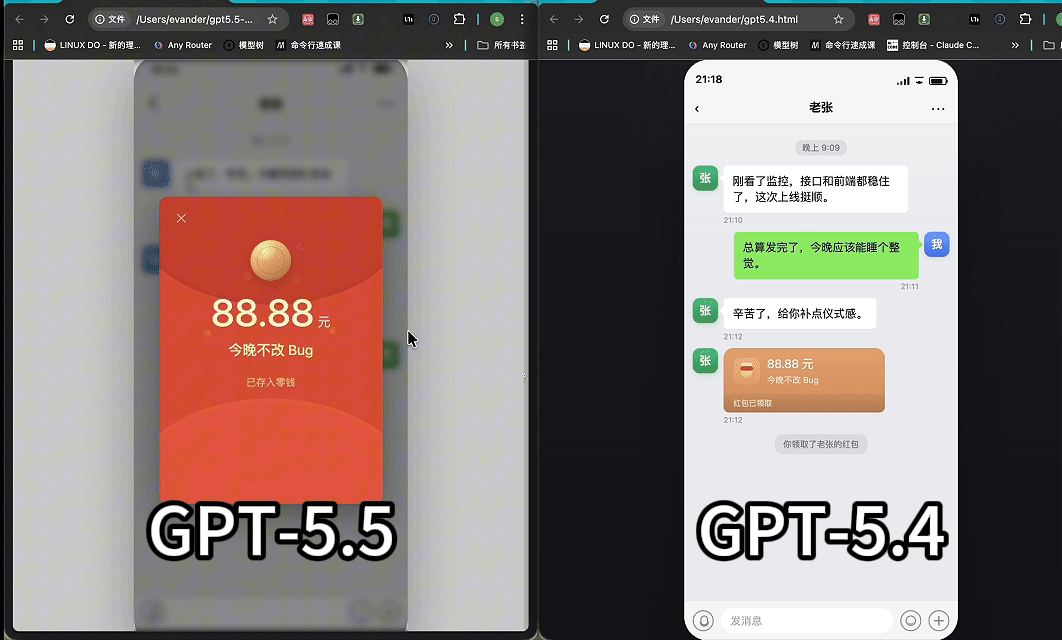
我们让 GPT-5.4 和 GPT-5.5 在同等条件下完成这个任务:生成一个「微信聊天界面 + 红包开启动画」的单文件 HTML。
规则很简单:同一个 prompt、同一档 Thinking、不允许外部依赖,只看最终交付效果。
评测重点不在“能不能写出来”,而在更接近真实开发的三点:
界面是否像真实产品
红包是否可点击、交互是否完整
动效是否自然、有产品质感
两款模型均给出了可运行的单文件 HTML。GPT-5.4 实现了基础的图文排版和点击翻转动效;GPT-5.5 对 UI 细节(气泡圆角、色值、比例等)的还原度相对更高。这类差距不是能不能跑的问题,而是模型是否理解真实产品中的视觉层级、交互反馈和默认细节。
当然,能力提升最终还要回到一个现实问题:成本如何?
GPT-5.5 多层定价体系
| 模型 | 输入(每百万 token) | 输出(每百万 token) |
| GPT-5.4 | $2.50 | $15.00 |
| GPT-5.5 | $5.00 | $30.00 |
| GPT-5.5 Pro(API) | $30.00 | $180.00 |
成本方面,GPT-5.5 的 API 将上线 Responses API 和 Chat Completions API,标准价格为 $5 / 1M input tokens、$30 / 1M output tokens,并支持 1M context window;gpt-5.5-pro 定价更高,为 $30 / 1M input、$180 / 1M output。
虽然单价较 GPT-5.4 明显上涨,但 OpenAI 强调 GPT-5.5 在 Codex 任务中 token 使用更少,因此实际完成任务的总成本不会等比例增加。
通过官方数据和实测,我们能明显感受到:GPT-5.5 正在跨过从“聊天工具”到“执行代理(Agent)”的边界。
面对纯 CSS 动效这种强约束任务,或“做一个像微信红包”的模糊产品需求,它展现出的不只是代码生成能力,而是对约束、上下文、交互细节和产品质感的综合理解。
对开发者来说,这才是 GPT-5.5 最值得关注的地方:它不只是更会写代码,而是更接近一个能参与交付的工程协作者。


