Java并发编程:JMM Java内存模型 系统性知识体系
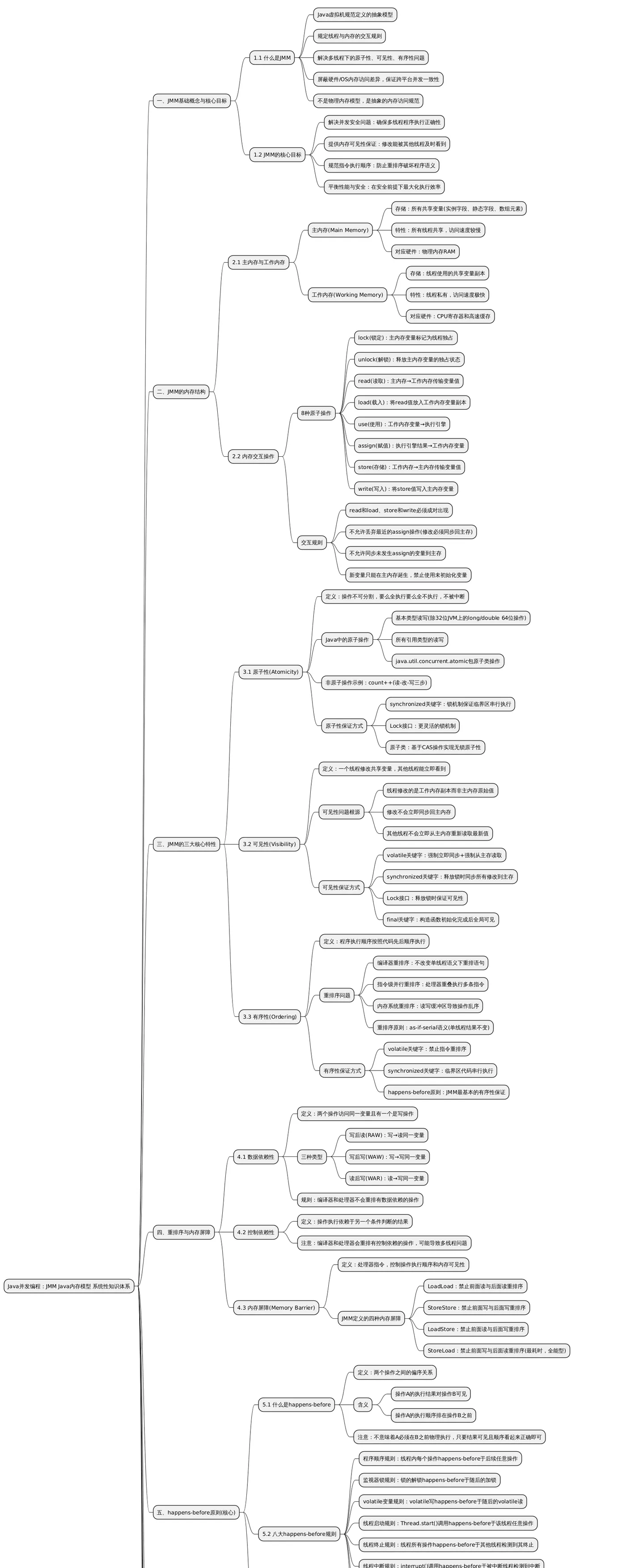
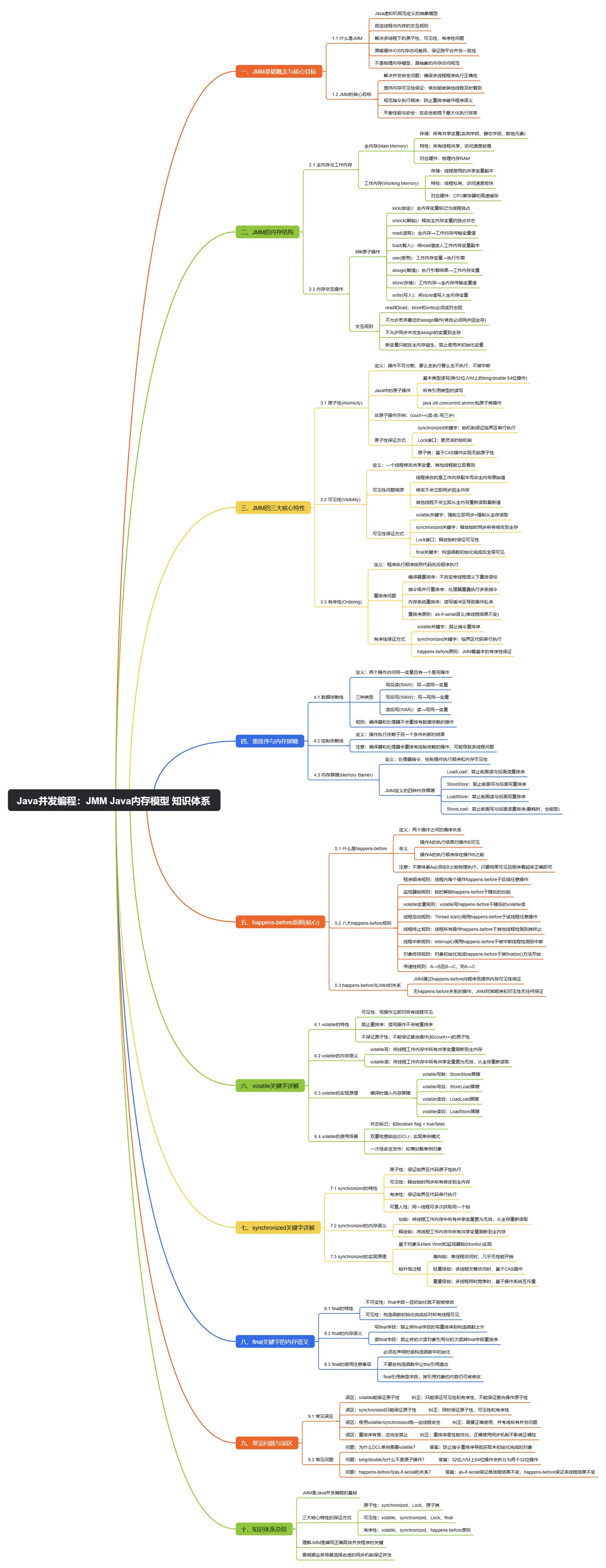
一、JMM 基础概念与核心目标
1.1 什么是JMM
Java内存模型(Java Memory Model, JMM) 是Java虚拟机规范中定义的一种抽象模型,它规定了线程如何通过内存进行交互,解决了多线程环境下的内存可见性、原子性和有序性问题,确保Java程序在不同硬件架构和操作系统下的并发行为一致性。
JMM不是物理内存模型,而是抽象的内存访问规范,它屏蔽了不同硬件和操作系统的内存访问差异,让Java程序在各种平台上都能表现出一致的并发行为。
1.2 JMM的核心目标
- 解决并发安全问题:确保多线程程序在并发执行时的正确性
- 提供内存可见性保证:一个线程对共享变量的修改能被其他线程及时看到
- 规范指令执行顺序:防止编译器和处理器的重排序破坏程序语义
- 平衡性能与安全:在保证并发安全的前提下,尽可能提高程序执行效率
二、JMM的内存结构
2.1 主内存与工作内存
JMM将内存划分为两个主要区域:
| 内存区域 | 存储内容 | 访问特性 | 对应硬件 |
|---|---|---|---|
| 主内存(Main Memory) | 所有共享变量(实例字段、静态字段、数组元素) | 所有线程共享,访问速度较慢 | 对应物理内存的RAM |
| 工作内存(Working Memory) | 线程使用的共享变量的副本 | 线程私有,访问速度极快 | 对应CPU的寄存器和高速缓存 |
2.2 内存交互操作
JMM定义了8种原子操作来完成主内存与工作内存之间的交互:
- lock(锁定):作用于主内存变量,将变量标记为线程独占状态
- unlock(解锁):作用于主内存变量,释放被锁定的变量
- read(读取):作用于主内存变量,将变量值从主内存传输到工作内存
- load(载入):作用于工作内存变量,将read操作得到的值放入工作内存的变量副本中
- use(使用):作用于工作内存变量,将变量值传递给执行引擎
- assign(赋值):作用于工作内存变量,将执行引擎返回的值赋给工作内存变量
- store(存储):作用于工作内存变量,将变量值从工作内存传输到主内存
- write(写入):作用于主内存变量,将store操作得到的值写入主内存变量
交互规则:
- read和load、store和write必须成对出现
- 不允许线程丢弃最近的assign操作(变量修改后必须同步回主内存)
- 不允许线程将未发生assign操作的变量从工作内存同步回主内存
- 新变量只能在主内存中诞生,不允许在工作内存中直接使用未初始化的变量
三、JMM的三大核心特性
3.1 原子性(Atomicity)
定义:一个操作是不可分割的,要么全部执行成功,要么全部不执行,执行过程中不会被其他线程中断。
3.1.1 Java中的原子操作
- 基本类型的读取和赋值:除了long和double类型的64位操作(在32位JVM上可能被拆分为两个32位操作)
- 所有引用类型的读取和赋值
- java.util.concurrent.atomic包中的原子类操作:AtomicInteger、AtomicLong等
3.1.2 非原子操作示例
// 非原子操作:包含读取-修改-写入三个步骤
int count = 0;
count++; // 等价于:int temp = count; temp = temp + 1; count = temp;
3.1.3 原子性的保证方式
- synchronized关键字:通过锁机制保证同一时刻只有一个线程执行临界区代码
- Lock接口:提供比synchronized更灵活的锁机制
- 原子类:基于CAS(Compare-And-Swap)操作实现无锁原子性
3.2 可见性(Visibility)
定义:当一个线程修改了共享变量的值,其他线程能够立即看到这个修改。
3.2.1 可见性问题的根源
- 线程修改的是工作内存中的变量副本,而不是主内存中的原始变量
- 线程不会立即将修改后的变量同步回主内存
- 其他线程不会立即从主内存重新读取最新的变量值
3.2.2 可见性的保证方式
- volatile关键字:强制将修改立即同步回主内存,并强制其他线程从主内存重新读取变量
- synchronized关键字:在释放锁时将工作内存中的所有修改同步回主内存
- Lock接口:与synchronized类似,在释放锁时保证可见性
- final关键字:final字段在构造函数中初始化完成后,对所有线程可见
3.3 有序性(Ordering)
定义:程序执行的顺序按照代码的先后顺序执行。
3.3.1 重排序问题
为了提高性能,编译器和处理器会对指令进行重排序:
- 编译器重排序:编译器在不改变单线程程序语义的前提下,重新安排语句的执行顺序
- 指令级并行重排序:处理器将多条指令重叠执行
- 内存系统重排序:处理器使用读写缓冲区,使得加载和存储操作看起来是乱序执行的
重排序的原则:as-if-serial语义
- 不管怎么重排序,单线程程序的执行结果不能被改变
- 编译器和处理器不会对存在数据依赖关系的操作进行重排序
3.3.2 有序性的保证方式
- volatile关键字:禁止指令重排序
- synchronized关键字:保证同一时刻只有一个线程执行临界区代码,相当于让临界区代码串行执行
- happens-before原则:JMM提供的最基本的有序性保证
四、重排序与内存屏障
4.1 数据依赖性
如果两个操作访问同一个变量,且其中一个操作是写操作,那么这两个操作之间就存在数据依赖性。数据依赖性分为三种:
- 写后读(RAW):写一个变量之后再读这个变量
- 写后写(WAW):写一个变量之后再写这个变量
- 读后写(WAR):读一个变量之后再写这个变量
编译器和处理器不会改变存在数据依赖性的两个操作的执行顺序。
4.2 控制依赖性
如果一个操作的执行依赖于另一个条件判断操作的结果,那么这两个操作之间就存在控制依赖性。
注意:编译器和处理器会对存在控制依赖性的操作进行重排序,这可能导致多线程程序出现问题。
4.3 内存屏障(Memory Barrier)
内存屏障是一组处理器指令,用于控制特定操作的执行顺序和内存可见性。JMM通过内存屏障来禁止特定类型的重排序。
JMM定义了四种内存屏障:
- LoadLoad屏障:禁止前面的读操作与后面的读操作重排序
- StoreStore屏障:禁止前面的写操作与后面的写操作重排序
- LoadStore屏障:禁止前面的读操作与后面的写操作重排序
- StoreLoad屏障:禁止前面的写操作与后面的读操作重排序(最耗时,具有全能性)
五、happens-before原则(核心)
5.1 什么是happens-before
happens-before是JMM中定义的两个操作之间的偏序关系。如果操作A happens-before 操作B,那么:
- 操作A的执行结果对操作B可见
- 操作A的执行顺序排在操作B之前
注意:happens-before关系并不意味着操作A必须在操作B之前执行,只要操作A的结果对操作B可见,并且操作A的执行顺序看起来在操作B之前即可。
5.2 八大happens-before规则
- 程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作
- 监视器锁规则:对一个锁的解锁操作,happens-before于随后对这个锁的加锁操作
- volatile变量规则:对一个volatile变量的写操作,happens-before于随后对这个变量的读操作
- 线程启动规则:Thread对象的start()方法调用,happens-before于该线程中的任意操作
- 线程终止规则:线程中的所有操作,happens-before于其他线程检测到该线程已经终止
- 线程中断规则:对线程interrupt()方法的调用,happens-before于被中断线程检测到中断事件
- 对象终结规则:一个对象的初始化完成,happens-before于该对象的finalize()方法开始执行
- 传递性规则:如果A happens-before B,且B happens-before C,那么A happens-before C
5.3 happens-before与JMM的关系
JMM通过happens-before原则向程序员提供了内存可见性保证。如果两个操作之间没有happens-before关系,那么JMM对它们的执行顺序和可见性没有任何保证。
六、volatile关键字详解
6.1 volatile的特性
- 可见性:对volatile变量的写操作立即对所有线程可见
- 禁止重排序:volatile变量的读写操作不会被重排序
- 不保证原子性:volatile不能保证复合操作的原子性(如count++)
6.2 volatile的内存语义
- volatile写的内存语义:当写一个volatile变量时,JMM会把该线程工作内存中的所有共享变量刷新到主内存
- volatile读的内存语义:当读一个volatile变量时,JMM会把该线程工作内存中的所有共享变量置为无效,然后从主内存中重新读取
6.3 volatile的实现原理
volatile通过在编译时插入内存屏障来实现其特性:
- 在每个volatile写操作前插入StoreStore屏障
- 在每个volatile写操作后插入StoreLoad屏障
- 在每个volatile读操作后插入LoadLoad屏障
- 在每个volatile读操作后插入LoadStore屏障
6.4 volatile的使用场景
- 状态标记:如boolean flag = true/false
- 双重检查锁定(DCL):实现单例模式
- 一次性安全发布:如懒加载的单例对象
七、synchronized关键字详解
7.1 synchronized的特性
- 原子性:保证临界区代码的原子性执行
- 可见性:在释放锁时将工作内存中的所有修改同步回主内存
- 有序性:保证临界区代码的串行执行
- 可重入性:同一个线程可以多次获取同一个锁
7.2 synchronized的内存语义
- 加锁的内存语义:当线程获取锁时,JMM会把该线程工作内存中的所有共享变量置为无效,然后从主内存中重新读取
- 释放锁的内存语义:当线程释放锁时,JMM会把该线程工作内存中的所有共享变量刷新到主内存
7.3 synchronized的实现原理
synchronized基于对象头中的Mark Word和监视器锁(Monitor)实现:
- 偏向锁:当只有一个线程访问同步块时,使用偏向锁,几乎没有性能开销
- 轻量级锁:当有多个线程交替访问同步块时,使用轻量级锁,基于CAS操作
- 重量级锁:当有多个线程同时竞争锁时,膨胀为重量级锁,基于操作系统的互斥量
八、final关键字的内存语义
8.1 final的特性
- 不可变性:final字段一旦被初始化,就不能被修改
- 可见性:final字段在构造函数中初始化完成后,对所有线程可见
8.2 final的内存语义
- 写final字段的重排序规则:禁止把final字段的写操作重排序到构造函数之外
- 读final字段的重排序规则:禁止把初次读对象引用与初次读该对象包含的final字段重排序
8.3 final的使用注意事项
- final字段必须在声明时或构造函数中初始化
- 不要在构造函数中让this引用逸出
- final引用类型的字段,其引用的对象的内容仍然可以被修改
九、常见问题与误区
9.1 常见误区
误区:volatile能保证原子性
纠正:volatile只能保证可见性和有序性,不能保证复合操作的原子性误区:synchronized只能保证原子性
纠正:synchronized同时保证原子性、可见性和有序性误区:只要使用了volatile或synchronized,程序就一定是线程安全的
纠正:需要正确使用这些关键字,并且考虑所有可能的并发问题误区:重排序是有害的,应该完全禁止
纠正:重排序是编译器和处理器为了提高性能而进行的优化,只要正确使用同步机制,就不会影响程序的正确性
9.2 常见问题
问题:为什么DCL单例模式需要使用volatile?
答案:防止指令重排序导致其他线程获取到未初始化完成的对象问题:long和double类型的变量为什么不是原子操作?
答案:在32位JVM上,64位的long和double类型的读写操作会被拆分为两个32位的操作,因此不是原子的问题:happens-before原则和as-if-serial语义有什么关系?
答案:as-if-serial语义保证单线程程序的执行结果不变,happens-before原则保证多线程程序的执行结果不变
十、知识体系总结
JMM是Java并发编程的基础,它通过定义主内存与工作内存的交互规则、三大核心特性(原子性、可见性、有序性)以及happens-before原则,解决了多线程环境下的内存访问问题。
- 原子性:由synchronized、Lock和原子类保证
- 可见性:由volatile、synchronized、Lock和final保证
- 有序性:由volatile、synchronized和happens-before原则保证
理解JMM是编写正确、高效的Java并发程序的关键。在实际开发中,我们应该根据具体的业务场景,选择合适的同步机制来保证并发安全。
Java并发编程:JMM内存模型 面试高频考点清单
(按考察频率+重要性排序,标注星级,附核心答题要点与面试官追问方向)
一、基础概念类(必问)
| 考点 | 考察频率 | 核心答题要点 | 面试官常追问 |
|---|---|---|---|
| 1. 什么是JMM?它的核心目标是什么? | ★★★★★ | ① JMM是Java虚拟机规范定义的抽象内存访问模型 ② 屏蔽不同硬件/OS的内存访问差异,保证跨平台并发一致性 ③ 核心解决多线程环境下的原子性、可见性、有序性三大问题 ④ 平衡并发安全与程序执行性能 |
为什么需要JMM?没有JMM会出现什么问题? |
| 2. 主内存与工作内存的区别 | ★★★★★ | ① 主内存:存储所有共享变量(实例字段、静态字段、数组),线程共享,访问慢,对应物理RAM ② 工作内存:存储共享变量的副本,线程私有,访问极快,对应CPU寄存器和高速缓存 ③ 线程对变量的所有操作都必须在工作内存中进行,不能直接读写主内存 |
为什么不直接操作主内存? |
| 3. JMM定义的8种内存交互操作 | ★★★☆☆ | 按顺序:lock→read→load→use→assign→store→write→unlock 核心规则:read/load、store/write必须成对出现;修改必须同步回主存 |
为什么需要这8种操作?可以简化吗? |
二、三大核心特性(必问,区分基础与进阶)
| 考点 | 考察频率 | 核心答题要点 | 面试官常追问 |
|---|---|---|---|
| 1. 什么是原子性、可见性、有序性?分别如何保证? | ★★★★★ | ① 原子性:操作不可分割,要么全执行要么全不执行 保证方式:synchronized、Lock、Atomic原子类 ② 可见性:一个线程的修改能被其他线程立即看到 保证方式:volatile、synchronized、Lock、final ③ 有序性:程序执行顺序与代码逻辑顺序一致 保证方式:volatile、synchronized、happens-before原则 |
这三个特性之间有什么关系?缺少一个会导致什么问题? |
| 2. 为什么long和double类型的读写不是原子操作? | ★★★★☆ | ① 32位JVM上,64位的long/double读写会被拆分为两个32位操作 ② 可能出现"字撕裂"问题:一个线程写了高32位,另一个线程读到了低32位 ③ 64位JVM上通常保证原子性,但规范不强制要求 |
如何解决long/double的原子性问题? |
| 3. as-if-serial语义是什么? | ★★★★☆ | ① 编译器和处理器在不改变单线程程序执行结果的前提下,可以对指令进行重排序 ② 是单线程程序看起来"顺序执行"的保证 ③ 只保证单线程语义,不保证多线程语义 |
as-if-serial和happens-before的关系? |
三、重排序与内存屏障(高频进阶)
| 考点 | 考察频率 | 核心答题要点 | 面试官常追问 |
|---|---|---|---|
| 1. 什么是重排序?有哪些类型? | ★★★★★ | ① 重排序是编译器和处理器为了提高性能对指令执行顺序的优化 ② 三种类型:编译器重排序、指令级并行重排序、内存系统重排序 ③ 重排序可能破坏多线程程序的语义 |
重排序在什么情况下是安全的? |
| 2. 什么是内存屏障?JMM有哪几种? | ★★★★★ | ① 内存屏障是处理器指令,用于控制特定操作的执行顺序和内存可见性 ② 四种类型: - LoadLoad:禁止前面读与后面读重排序 - StoreStore:禁止前面写与后面写重排序 - LoadStore:禁止前面读与后面写重排序 - StoreLoad:禁止前面写与后面读重排序(最耗时,全能型) |
为什么StoreLoad屏障最耗时? |
| 3. 数据依赖性与控制依赖性的区别 | ★★★☆☆ | ① 数据依赖:两个操作访问同一变量且有一个是写操作(写后读、写后写、读后写) 编译器和处理器不会重排有数据依赖的操作 ② 控制依赖:操作执行依赖于条件判断结果 编译器和处理器会重排有控制依赖的操作,可能导致多线程问题 |
举一个控制依赖导致并发问题的例子? |
四、happens-before原则(核心中的核心,必问)
| 考点 | 考察频率 | 核心答题要点 | 面试官常追问 |
|---|---|---|---|
| 1. 什么是happens-before原则?它的作用是什么? | ★★★★★ | ① happens-before是JMM定义的两个操作之间的偏序关系 ② 如果A happens-before B,则: - A的执行结果对B可见 - A的执行顺序排在B之前 ③ 作用:向程序员提供明确的内存可见性保证,是判断多线程程序是否安全的唯一依据 |
happens-before关系意味着A必须在B之前物理执行吗? |
| 2. 列举happens-before的八大规则 | ★★★★★ | 按重要性排序: 1. 程序顺序规则:线程内操作按代码顺序 2. 监视器锁规则:解锁happens-before于随后的加锁 3. volatile变量规则:写happens-before于随后的读 4. 传递性规则:A→B且B→C,则A→C 5. 线程启动规则:start() happens-before于线程内所有操作 6. 线程终止规则:线程内所有操作happens-before于其他线程检测到其终止 7. 线程中断规则:interrupt() happens-before于检测中断 8. 对象终结规则:初始化完成happens-before于finalize() |
用happens-before规则分析一个具体的并发场景? |
| 3. happens-before与as-if-serial的关系 | ★★★★☆ | ① as-if-serial保证单线程程序的执行结果不变 ② happens-before保证多线程程序的执行结果不变 ③ 两者都是为了在不改变程序执行结果的前提下,尽可能提高程序执行效率 |
没有happens-before关系的两个操作,JMM会如何处理? |
五、volatile关键字(最高频考点,必问)
| 考点 | 考察频率 | 核心答题要点 | 面试官常追问 |
|---|---|---|---|
| 1. volatile的三大特性 | ★★★★★ | ① 保证可见性:写操作立即刷新到主存,读操作直接从主存读取 ② 禁止指令重排序:通过内存屏障实现 ③ 不保证原子性:不能保证复合操作(如count++)的原子性 |
为什么volatile不能保证原子性? |
| 2. volatile的内存语义 | ★★★★★ | ① 写语义:写volatile变量时,将该线程工作内存中所有共享变量刷新到主内存 ② 读语义:读volatile变量时,将该线程工作内存中所有共享变量置为无效,从主存重新读取 |
为什么volatile写会刷新所有共享变量? |
| 3. volatile的实现原理(内存屏障) | ★★★★★ | 编译时在volatile操作前后插入内存屏障: ① 写前:StoreStore屏障(禁止前面写与volatile写重排) ② 写后:StoreLoad屏障(禁止volatile写与后面读重排) ③ 读后:LoadLoad屏障(禁止volatile读与后面读重排) ④ 读后:LoadStore屏障(禁止volatile读与后面写重排) |
不同处理器的内存屏障实现有差异吗? |
| 4. volatile的使用场景 | ★★★★★ | ① 状态标记:如boolean flag = true/false(一写多读) ② 双重检查锁定(DCL):实现单例模式 ③ 一次性安全发布:如懒加载的单例对象 ④ volatile变量作为刷新触发器 |
什么情况下不能使用volatile? |
| 5. volatile与synchronized的区别 | ★★★★★ | volatile是更轻量级的同步机制,性能更好 |
六、synchronized关键字(最高频考点,必问)
| 考点 | 考察频率 | 核心答题要点 | 面试官常追问 |
|---|---|---|---|
| 1. synchronized的四大特性 | ★★★★★ | ① 原子性:保证临界区代码串行执行 ② 可见性:释放锁时刷新所有修改到主存 ③ 有序性:临界区代码串行执行,相当于禁止重排序 ④ 可重入性:同一线程可以多次获取同一个锁 |
为什么synchronized是可重入的? |
| 2. synchronized的内存语义 | ★★★★☆ | ① 加锁语义:获取锁时,将线程工作内存中所有共享变量置为无效,从主存重新读取 ② 释放锁语义:释放锁时,将线程工作内存中所有共享变量刷新到主内存 |
synchronized的内存语义和volatile有什么异同? |
| 3. synchronized的实现原理 | ★★★★★ | ① 基于对象头中的Mark Word和监视器锁(Monitor)实现 ② 每个对象都可以作为锁,锁信息存储在对象头中 ③ 底层通过monitorenter和monitorexit指令实现 |
对象头的结构是什么样的? |
| 4. synchronized的锁升级过程(重点) | ★★★★★ | 锁只能升级不能降级: ① 无锁:对象刚创建时 ② 偏向锁:只有一个线程访问时,将线程ID记录在对象头中,几乎无性能开销 ③ 轻量级锁:多个线程交替访问时,通过CAS操作竞争锁,不阻塞线程 ④ 重量级锁:多个线程同时竞争时,膨胀为操作系统互斥量,线程阻塞 |
每种锁的适用场景和性能特点? |
| 5. synchronized与Lock的区别 | ★★★★☆ | Lock提供了更灵活的锁机制,如可中断锁、超时锁、公平锁等 |
七、final关键字的内存语义(中频)
| 考点 | 考察频率 | 核心答题要点 | 面试官常追问 |
|---|---|---|---|
| 1. final的内存语义 | ★★★☆☆ | ① 写final字段:禁止将final字段的写操作重排序到构造函数之外 ② 读final字段:禁止将初次读对象引用与初次读该对象的final字段重排序 |
为什么final字段在构造函数初始化后对所有线程可见? |
| 2. 使用final的注意事项 | ★★★☆☆ | ① final字段必须在声明时或构造函数中初始化 ② 不要在构造函数中让this引用逸出 ③ final引用类型字段,其引用的对象内容仍然可以被修改 |
如何实现真正的不可变对象? |
八、经典应用场景与问题(必问)
| 考点 | 考察频率 | 核心答题要点 | 面试官常追问 |
|---|---|---|---|
| 1. 为什么DCL单例模式需要使用volatile? | ★★★★★ | ① 防止指令重排序导致其他线程获取到未初始化完成的对象 ② 对象创建过程:分配内存→初始化对象→将引用指向内存地址 ③ 重排序可能导致顺序变为:分配内存→将引用指向内存地址→初始化对象 ④ 此时其他线程可能获取到一个"半初始化"的对象 |
不使用volatile会出现什么问题?有其他实现线程安全单例的方式吗? |
| 2. 如何实现一个线程安全的单例模式? | ★★★★★ | 推荐三种方式: ① 饿汉式(静态常量) ② 双重检查锁定(DCL)+volatile ③ 静态内部类(推荐,懒加载且线程安全) ④ 枚举单例(最安全,防止反射和序列化破坏) |
各种实现方式的优缺点? |
| 3. 什么是伪共享?如何解决? | ★★★☆☆ | ① 伪共享:多个线程修改同一个缓存行中的不同变量,导致缓存行频繁失效 ② 解决方法: - 使用@Contended注解(JDK 8+) - 填充字段,使每个变量独占一个缓存行 |
伪共享对性能的影响有多大? |
九、面试答题高分技巧
- 通用答题思路:先定义→再讲原理→最后讲应用场景和注意事项
- 突出深度:回答时不仅要说出"是什么",还要说出"为什么"和"怎么做"
- 结合实例:用具体的代码例子说明问题,比如用count++说明原子性问题
- 主动引导:回答完一个问题后,可以主动说"我还可以讲一下XXX相关的内容",展示你的知识广度
- 注意区分:明确区分JMM的抽象模型和实际的硬件内存模型