
作者信息
- Jiatan Huang(* Equal Contribution)— 美国康涅狄格大学(University of Connecticut)
- Zheyuan Zhang(* Equal Contribution)— 美国圣母大学(University of Notre Dame)
- Kaiwen Shi — 美国圣母大学
研究背景
近年来,大语言模型(Large Language Models,LLMs)在推理、语言理解和文本生成等任务上取得了显著进展,由此催生了基于 LLM 的智能体(LLM-based agents)这一强大范式,使模型能够自主规划、调用工具并在少有人工干预的情况下执行多步骤任务。然而,这一生态系统也带来了一个根本性的系统挑战:在给定下游任务时,从业者必须在大规模模型骨干网络、提示策略和交互协议的设计空间中做出选择,而最有效的配置往往事先并不清晰。
现有研究已经观察到,不同智能体通常表现出互补的、任务特异性的优势。在实际部署中,中等规模的模型或较简单的智能体配置有时反而能匹配甚至超越更复杂的替代方案。与此同时,简单地将所有可用智能体组合在一起也是低效的——统一集成往往浪费算力在无关参与者上,而选择不当的多智能体协作甚至可能降低最终性能。
在此背景下,LLM 路由(routing)和模型选择成为研究热点。早期方法依赖多数投票和基于一致性的选择等启发式聚合策略;后期方法引入自适应路由,通过偏好学习和对比学习等技术学习针对特定查询的智能体分配策略;近年来研究进一步利用查询和上下文的语义和结构信息,向协作式多智能体投票方向发展。然而,两个重要局限仍未解决:①大多数路由方法将智能体行为视为固定的,仅优化"调用哪个智能体"而非"如何让每个智能体配置得更好";②现有协作范式依赖僵硬的参与机制,无法根据查询自适应调整参与智能体的数量。
研究目的
本文旨在解决现有路由方法的两大核心局限:
- 具体问题一:现有路由方法仅优化智能体的选择策略,而不改进智能体本身的配置质量,导致路由无法充分释放协作收益。
- 具体问题二:现有协作方案依赖固定参与数量的聚合机制,无法自适应地为每个查询动态确定最合适的协作规模,造成要么遗漏互补专业能力、要么引入无关或弱势智能体的问题。
本文目标在于提出一个可训练的联合优化框架,在路由质量与智能体能力两个维度上实现闭环协同进化,从而实现更强大、更高效的多智能体推理。
本文核心贡献
贡献一:路由与智能体专业化的闭环协同进化
针对静态智能体行为的局限性,本文提出将查询感知路由与定向智能体指令精炼(targeted instruction refinement)相结合的闭环协同进化框架。框架基于 RouterGNN 构建知识图谱路由器(KG-based router),在训练过程中收集每个智能体优势和失败模式的细粒度诊断信号,识别持续表现不佳的角色,生成候选指令修订方案,并仅保留能够带来可靠改进的方案。精炼后的智能体反过来产生更高质量的输出,为后续路由器训练提供更清晰的监督信号。通过这一迭代过程,路由质量和智能体能力实现联合提升。
贡献二:基于动态智能体选择的自适应协作机制
针对僵硬协作方案的问题,本文引入自适应推理机制,通过路由加权答案一致性(router-weighted answer agreement)动态确定每个查询的有效协作规模 K。方法不依赖单一智能体路由或固定池聚合,而是按路由器预测的排名顺序依次调用智能体,通过监控加权答案一致性来动态估计所需的参与智能体数量,实现智能体选择与协作规模的联合学习。
贡献三:全面的实验验证与分析
在五个问答基准测试上的广泛实验表明,EvolveRouter 在 F1 和精确匹配(Exact Match)两个指标上一致性地超越所有 SOTA 路由基线,验证了协同进化框架的泛化有效性。进一步的消融分析验证了闭环指令精炼和自适应协作机制各自的有效性,并揭示了路由质量与智能体能力如何相互增强的机制。
研究方法
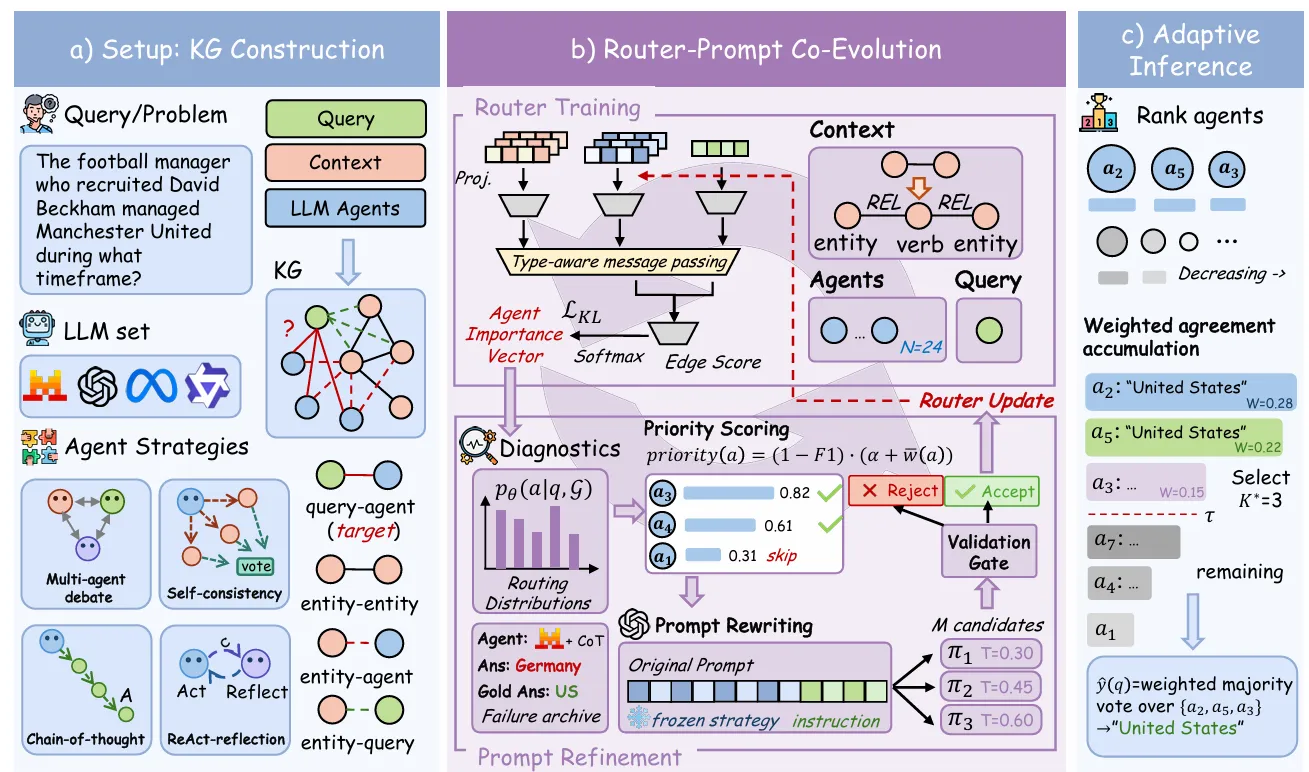
问题设定与路由目标
智能体池设定:考虑一个智能体池 A = {a₁, …, aₙ},其中每个智能体将骨干 LLM 与提示角色(如 Chain-of-Thought、Debate、ReAct-Reflect 等)相结合。在本文设定中 n = 24,对应 4 种骨干模型 × 6 种角色。给定查询 q 和上下文 C,智能体 a 通过其提示 πₐ 调用骨干 LLM 生成答案 yₐ(q)。
知识图谱建模:将每个问答实例表示为带类型的知识图谱 G = (V, E),其中节点集 V = V_Q ∪ V_A ∪ VE 分别包含查询节点、智能体节点和实体节点。边编码四类关系:查询-实体边和实体-实体边将查询锚定在证据上下文中;智能体-实体边反映每个智能体对上下文的视角;查询-智能体边为可训练连接,承载模型学习预测的路由信号。路由因此转化为学习图上的评分函数:s(q,a) = fθ(q,a; G),并通过 softmax 得到概率分布 p_θ(a|q,G)。
训练信号:对每个训练查询,评估所有智能体的 token 级 F1 分数,通过温度缩放的 softmax 转化为软目标分布 p*(a|q),然后通过 KL 散度最小化训练路由器。测试时通过加权多数投票组装最终预测。
联合优化目标
将提示集 Π = {πₐ}_{a∈A} 作为可联合优化的变量,并在推理时使智能体预算 K(q) 查询自适应化。由于软目标 p* 通过智能体性能依赖于提示,改进提示会重塑路由器学习的内容,反之亦然。理想目标是对路由器参数 θ 和提示 Π 进行联合优化,最小化期望 KL 散度。
迭代协同进化算法:①训练基于知识图谱的路由器;②收集诊断信号识别弱角色;③生成候选指令修订;④保留有效修订精炼智能体;⑤精炼后的智能体为路由训练提供更清晰监督;⑥返回①迭代执行。
自适应协作推理
在推理阶段,替代固定 K 值或单智能体选择,方法按路由器排名顺序依次调用智能体,监控累积的路由加权答案一致性,当一致性低于阈值时停止,动态确定该查询的有效协作规模 K(q)。
数据集
实验在三个多跳问答基准测试上进行:HotpotQA(平均 142.1 实体/385.1 实体间边)、NewsQA(60.3 实体/109.4 边)和 NGQA(25.0 实体/26.75 边)。智能体池包含 4 种骨干模型(GPT-4、Claude 等)× 6 种角色,共 24 个智能体配置。
研究结果
整体性能提升:在五个 QA 基准测试上,EvolveRouter 在 F1 和精确匹配(Exact Match)两个指标上一致性地超越所有 SOTA 路由基线,验证了协同进化框架的泛化有效性。
闭环协同进化的效果:消融实验表明,闭环指令精炼机制能够显著改进底层智能体的质量,进而提升路由决策的准确性。路由器诊断信号与智能体改进之间形成了正向增强循环。
自适应协作的效果:自适应 K(q) 推理策略避免了固定池聚合的冗余计算和不相关智能体的干扰,在不同复杂度查询上实现了效率和质量的动态平衡,路由加权答案一致性机制有效识别了有效协作边界。
跨维度洞察:实验揭示了智能体质量的高度上下文依赖性——同一 LLM 在相同提示下不同任务表现差异显著,提示选择对各智能体 F1 的影响因角色而异,表明多维度的联合优化至关重要。
总结与展望
本文提出了 EvolveRouter,一个通过闭环协同进化联合优化路由与智能体配置的创新框架,有效解决了多智能体问答中智能体质量静态化和协作规模僵化的两大核心问题。实验结果充分验证了其相对于现有 SOTA 方法的优越性。
局限性:本文主要在问答任务上验证,框架在开放式生成、复杂推理等其他任务类型上的泛化能力有待进一步探索。此外,协同进化过程增加了训练复杂度,在超大规模智能体池上的可扩展性也需要评估。
未来拓展方向:①将框架拓展至更多任务类型(如代码生成、科学推理);②探索更细粒度的智能体诊断信号和指令修订策略;③研究协同进化过程的收敛保证和效率优化;④结合模型剪枝或蒸馏技术降低计算开销。




