
《LangChain 智能体从浅入门到深入门:模型配置、中间件体系、装饰器钩子与 invoke 调用模式全解析部分内容指南分享》
(如有错误欢迎指正!)
搭配智能体 | LangChain 中文文档使用最好哦!
以代码为形式的笔记可以快速方便我们自己查看源码,深入阅读LangChain以及LangGragh的源码是非常重要的!以及LangChain,LangGragh不分家!一家人!
AI时代!强烈建议初学者不要光看,一定要动手敲一遍,这是个非常重要的习惯!把代码实现一遍你会踩过数以万计之前不曾注意的坑!进而学习到更多的知识!加油!💪
笔者第一次尝试,第一次书写,第一次编排(几乎没有编排)如果观感不易,请见谅!
【干预踏出第一步很棒了!】
本文是以“详细的代码笔记”+“内容快速概括”的形式进行编排和书写,前半部分是详细的代码笔记,后半部分是主要内容的细致概括。虽然可能前半部分的观感很差,没有编排,没有任何的格式编辑,但是是本人亲自在PyCharm中书写的,所以都是人话,通俗易懂,代码+说明的方式能够让读者阅读清楚并且清晰理解知识;而后半部分是高度概括版,不是人话,但是观感好!结构分层明确+清晰,但是不是人话,用以快速复盘最好了
# Agent
"""1.1 为什么需要智能体?
传统的 LLM 调用是单次推理:输入问题 → 输出答案。但在生产场景中,你需要解决复杂任务:
用户问“帮我查一下北京天气,如果下雨就推荐室内活动,否则推荐户外活动”——需要先查天气,再根据结果做不同处理
数据分析任务:生成 SQL → 执行 → 发现错误 → 修正 SQL → 再次执行 → 生成报告
一句话总结:智能体让 LLM 从“一次性回答者”变成“能够执行多步推理、调用工具、并根据结果自我修正的执行者”。"""
import tools
from langchain_core.messages import HumanMessage
from sqlalchemy.ext.mypy.apply import add_additional_orm_attributes
# 智能体将语言模型与工具结合,创建能够对任务进行推理、决定使用哪些工具并迭代寻求解决方案的系统。
# create_agent 提供了一个生产就绪的智能体实现。
"""
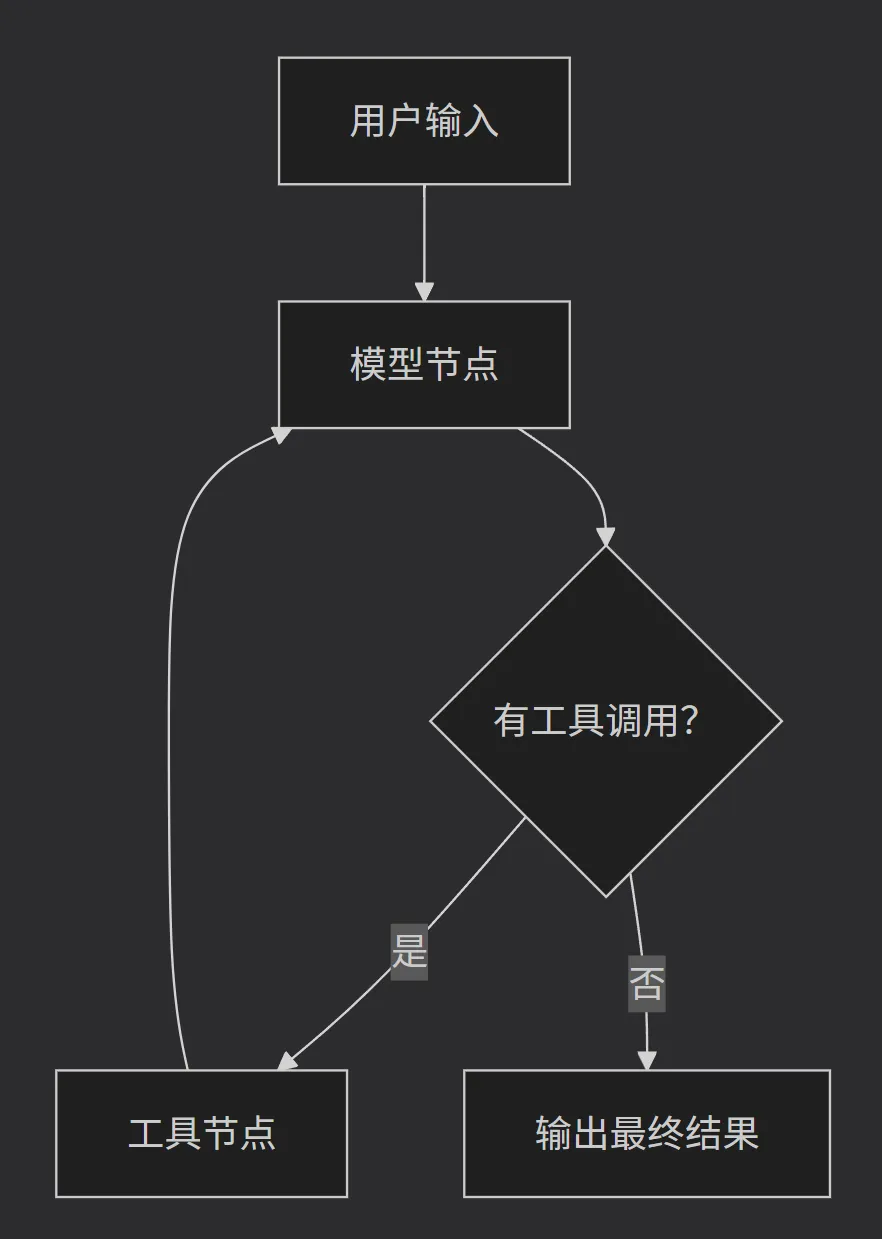
1.2 智能体的运行时架构
明确指出:create_agent 基于 LangGraph 构建了一个图结构运行时。这是理解智能体行为的关键:
用户输入 → [模型节点] → 有工具调用? → [工具节点] → [模型节点] → 输出最终结果
↑ ↓
└────────── 循环 ──────────┘
"""
#
# 模型 是智能体的推理引擎。它可以通过多种方式指定,支持静态和动态模型选择
from langchain.agents import *
# 静态模型配置
# 方式1:字符串标识符(适合快速原型)
agent = create_agent("openai:gpt-5", tools=tools)
# 方式2:模型实例(生产推荐,完全控制)
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-4o",
temperature=0.1, # 低温度提高确定性
max_tokens=2000, # 控制成本
timeout=30, # 防止阻塞
max_retries=2 # 网络抖动自动重试
)
agent1 = create_agent(model, tools=tools)
#生产建议:始终使用模型实例。字符串标识符虽然方便,但无法控制 temperature、timeout 等关键参数。
# 动态模型选择(成本优化核心)
# 动态模型在 运行时 根据当前 状态 和上下文进行选择。这支持复杂的路由逻辑和成本优化。
# 要使用动态模型,请使用例如 @wrap_model_call 装饰器创建中间件,以修改请求中的模型:
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
basic_model = ChatOpenAI(model="gpt-4o-mini")
advanced_model = ChatOpenAI(model="gpt-4o")
@wrap_model_call
def dynamic_model_selection(request: ModelRequest, handler) -> ModelResponse:
"""根据对话复杂性选择模型。"""
message_count = len(request.state["messages"])
if message_count > 10:
# 对较长的对话使用高级模型
model1 = advanced_model
else:
model1 = basic_model
request.model = model1
return handler(request)
agent2 = create_agent(
model=basic_model, # 默认模型
tools=tools,
middleware=[dynamic_model_selection]
)
"""
1.3 中间件(Middleware)
一、中间件的核心价值与设计哲学
1.31 为什么需要中间件?
在生产环境中,你需要的 Agent 不仅仅是“能回答问题”,还需要:
成本控制:防止模型无限调用导致账单爆炸
安全合规:过滤敏感信息(PII),防止数据泄露
稳定性:模型调用失败时自动降级,工具执行失败时重试
可观测性:记录每一步的输入输出,便于调试和审计
用户体验:在关键操作前请求人工确认,避免误操作
一句话总结:中间件让你能够在不修改 Agent 核心逻辑的前提下,注入横切关注点,实现生产级的安全、稳定和可控。
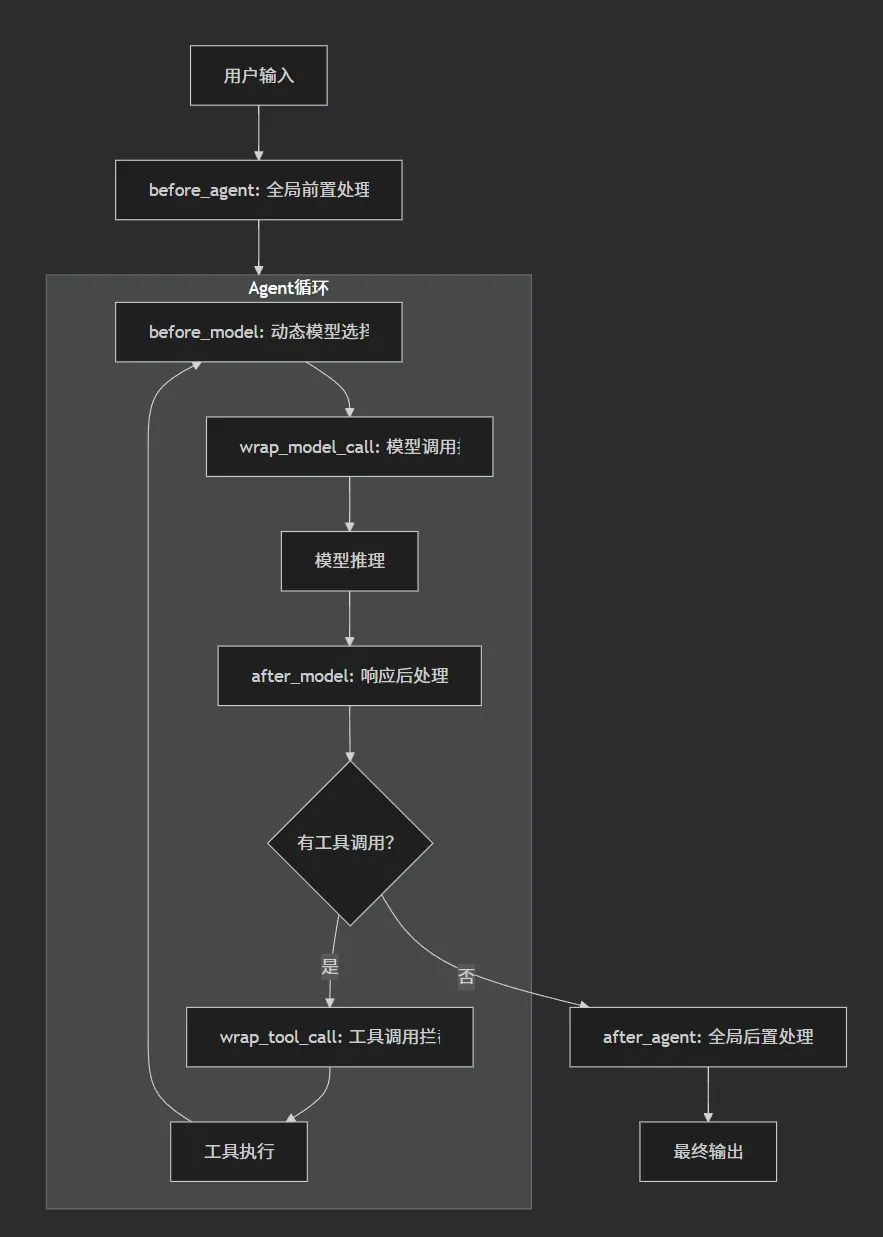
中间件在 LangGraph 执行图中的关键位置插入钩子:
用户输入
↓
【before_agent】← 全局前置处理(日志、权限检查)
↓
┌─────────────────────────────────────────┐
│ 执行循环(直到完成或达到限制) │
│ ┌─────────────────────────────────────┐│
│ │ 【before_model】← 动态模型选择 ││
│ │ ↓ ││
│ │ 【wrap_model_call】← 模型调用拦截 ││
│ │ ↓ ││
│ │ 模型推理 ││
│ │ ↓ ││
│ │ 【after_model】← 响应后处理 ││
│ └─────────────────────────────────────┘│
│ ↓ │
│ 有工具调用? │
│ ↓ 是 │
│ ┌─────────────────────────────────────┐│
│ │ 【wrap_tool_call】← 工具调用拦截 ││
│ │ ↓ ││
│ │ 工具执行 ││
│ └─────────────────────────────────────┘│
└─────────────────────────────────────────┘
↓
【after_agent】← 全局后置处理(审计、结果转换)
↓
最终输出
"""
# todo:1.32c二、生产级中间件详解
# 以下按照使用频率排序,逐一讲解每个中间件的为什么、是什么、怎么用。
"""
1.ToolRetryMiddleware(工具重试)
为什么重要:工具调用可能因网络抖动、API 限流、临时错误而失败。自动重试能显著提高系统健壮性,避免用户看到“系统错误”。
使用频率:★★★★★(几乎所有生产系统都需要)"""
from langchain.agents import create_agent
from langchain.agents.middleware import ToolRetryMiddleware
from langchain.tools import tool
from langchain_core.messages import HumanMessage
import time
import random
import dotenv
dotenv.load_dotenv()
@tool
def unstable_api_call(query:str)->str:
"""使用 unstable_api_call 模拟一个 API 调用,可能因网络抖动、API 限流、临时错误而失败。"""
time.sleep(random.uniform(0.5, 2))
"""
添加随机延迟,
random.uniform(0.5, 2)
生成一个 0.5 到 2 之间的随机浮点数
例如:可能返回 0.73、1.45、1.89 等
time.sleep(秒数)
让程序暂停执行指定的秒数
这里是暂停 0.5-2 秒之间的随机时长
"""
if random.random() < 0.1:
raise ConnectionError("API 临时不可用,请重试")
return f"API 调用成功,查询结果为:{query}"
# ToolRetryMiddleware 配置
retry_middleware = ToolRetryMiddleware(
max_retries=3,# 最大重试次数
backoff_factor=2.0,# 指数退避因子(重试间隔: 1, 2, 4 秒)
retry_on=(ConnectionError,TimeoutError),# 需要重试的异常类型
)
agent3 = create_agent(
model="deepseek-chat",
tools=[unstable_api_call],
middleware=[retry_middleware]
)
result=agent3.invoke({"messages":[HumanMessage(content="查询次数")]})
print(f"{result}")
"""
2.SummarizationMiddleware(对话摘要)
为什么重要:长对话会导致 token 超限,成本飙升。摘要中间件自动将历史对话压缩为摘要,保留关键信息的同时大幅降低成本。
使用频率:★★★★★(所有多轮对话系统都需要)
"""
from langchain.agents.middleware import SummarizationMiddleware
from langchain.agents.middleware.summarization import ContextSize, ContextTokens
summary_middleware = SummarizationMiddleware(
trigger=ContextSize(max_tokens=4000),
keep=ContextTokens(max_tokens=10),
token_counter=lambda text: len(text.split()),
summary_prompt="请将以下对话压缩为简洁摘要,保留关键信息和上下文",
model='deepseek-chat')
agent3 = create_agent(
model="deepseek-chat",
tools=[],
middleware=[summary_middleware]
)
# 执行过程(内部数据流转):
#
# 初始状态:对话有 100 条消息,总 token = 5000
# ↓
# before_model 钩子检测到超过阈值
# ↓
# 提取最近 5 条消息(保留)
# ↓
# 将前 95 条消息发送给 summary_model 生成摘要
# ↓
# 新状态:[
# SystemMessage(content="对话摘要:用户询问天气..."),
# HumanMessage(content="最近一条消息内容"), # 最近 5 条
# AIMessage(...),
# ...
# ]
# ↓
# 总 token 从 5000 降至 ~500
"""3 ModelCallLimitMiddleware(模型调用限制)
为什么重要:防止 Agent 陷入无限循环,或被恶意用户消耗大量 token 导致成本失控。这是成本控制的第一道防线。
使用频率:★★★★★(所有生产系统必备)"""
from langchain.agents.middleware import ModelCallLimitMiddleware
from langchain_community.chat_models import ChatTongyi
limit_middleware = ModelCallLimitMiddleware(
thread_limit=2,
run_limit=3,
exit_behavior="error"
)
agent4 = create_agent(
model="openai:gpt-4o",
tools=[],
middleware=[limit_middleware]
)
# 执行示例:一个复杂的多步任务
result = agent.invoke({
"messages": [{"role": "user", "content": "分析财报并生成报告"}]
})
"""
4 ModelFallbackMiddleware(模型降级)
为什么重要:主模型可能因服务故障、限流、配额耗尽而不可用。自动降级到备用模型是保障服务可用性的关键。
使用频率:★★★★☆(高可用系统必备)
"""
from langchain.agents.middleware import ModelFallbackMiddleware
from langchain_openai import ChatOpenAI
# 配置主模型和备选模型
fallback_middleware = ModelFallbackMiddleware(
ChatOpenAI(model="gpt-4o-mini", temperature=0.5),
ChatOpenAI(model="gpt-3.5-turbo", temperature=0.3),
ChatTongyi(model="qwen-max", api_key="sk1234568790")
)
"""
使用频率:★★★★☆(涉及用户数据的系统)
6 HumanInTheLoopMiddleware(人工确认)
为什么重要:对于可能产生重大影响的操作(如发送邮件、删除数据、转账),需要在执行前获得人工确认。这是 Agent 安全性的核心保障。
7 ToolCallLimitMiddleware(工具调用限制)
为什么重要:防止 Agent 无限调用某个工具(如反复查询数据库),避免资源消耗和成本失控。
"""
from langchain.agents.middleware import HumanInTheLoopMiddleware
hitl_middleware = HumanInTheLoopMiddleware(
interrupt_on={
"send_email": False,
}
)
from langchain.agents.middleware import ToolCallLimitMiddleware
tool_limit_middleware = ToolCallLimitMiddleware(
tool_name="send_email",
thread_limit=3,
run_limit=3,
exit_behavior="error"
)
"""
此外还有
5 PIIMiddleware(敏感信息检测与处理)
为什么重要:合规要求(GDPR、CCPA)规定不能将用户敏感信息发送给第三方 API。PII 中间件在发送前检测并处理敏感数据。
"""
#2、自定义中间件:装饰器详解
# 补充:warp的含义
# 一句话解释:包裹(Wrap)是一种装饰器模式,它在目标函数(模型调用或工具调用)外面包一层代码,
# 让你能够在目标函数执行前后插入逻辑,甚至可以完全替换目标函数的执行。
# 包裹器(中间件)
def wrap_model_call(request, handler):
# handler 就是原始函数 call_model
print("【包裹层】调用前")
response = handler(request) # 这里才真正执行原始函数
print("【包裹层】调用后")
return response
# 实际执行时
# response = wrap_model_call(request, call_model)
# 补充:request:请求的完整上下文
# ModelRequest 的结构(模型调用时)
from langchain.agents.middleware import ModelRequest
# request 包含以下关键属性:
"""
model: BaseChatModel
messages: list[AnyMessage] # excluding system message
system_message: SystemMessage | None
tool_choice: Any | None
tools: list[BaseTool | dict[str, Any]]
response_format: ResponseFormat[Any] | None
state: AgentState[Any]
runtime: Runtime[ContextT]
model_settings: dict[str, Any] = field(default_factory=dict)
"""
# ToolCallRequest 的结构(工具调用时)
from langchain.agents.middleware import ToolCallRequest
# request 包含以下关键属性:
"""
tool_call: ToolCall
tool: BaseTool | None
state: Any
runtime: ToolRuntime
"""
# 补充:handler的含义
# handler 是中间件链中的下一个执行者。当你调用 handler(request) 时,它做两件事:
# 执行后续所有中间件的包裹层(如果还有)
# 最终执行真正的模型/工具调用
# 中间件链示例
# middleware_list = [cache_middleware, retry_middleware, logging_middleware]
# 当第一个中间件调用 handler(request) 时:
# cache_middleware.handler → retry_middleware → logging_middleware → 真正的 API 调用
#
# 参数 类型 一句话作用
# request ModelRequest 或 ToolCallRequest 当前请求的快照,包含所有需要的信息(消息、状态、配置等)
# handler Callable “下一步”的执行函数,调用它才能继续执行真正的模型/工具调用
"""
用户输入
↓
[before_agent] ← Node-style,全局初始化
↓
┌─────────────────────────────────────────────────────────┐
│ Agent 循环(直到完成) │
│ ┌─────────────────────────────────────────────────────┐│
│ │ [before_model] ← Node-style,准备请求 ││
│ │ ↓ ││
│ │ [dynamic_prompt] ← 生成 system prompt(实际也是 wrap)││
│ │ ↓ ││
│ │ 【wrap_model_call】← 包裹整个模型调用 ││
│ │ ↓ ││
│ │ 模型 API 调用 ││
│ │ ↓ ││
│ │ 【wrap_model_call】← 返回响应 ││
│ │ ↓ ││
│ │ [after_model] ← Node-style,验证/转换响应 ││
│ └─────────────────────────────────────────────────────┘│
│ ↓ │
│ 有工具调用? │
│ ↓ 是 │
│ ┌─────────────────────────────────────────────────────┐│
│ │ 【wrap_tool_call】← 包裹每个工具调用 ││
│ │ ↓ ││
│ │ 工具执行 ││
│ │ ↓ ││
│ │ 【wrap_tool_call】← 返回结果 ││
│ └─────────────────────────────────────────────────────┘│
└─────────────────────────────────────────────────────────┘
↓
[after_agent] ← Node-style,收尾处理
↓
最终输出
补充hooks:钩子类型
钩子类型 设计模式 执行时机 核心用途 是否可修改请求/响应
before_agent Node-style Agent 图执行开始前 全局初始化、权限校验、日志记录、指标埋点 可修改初始 state
before_model Node-style 每次模型调用前 动态修改 messages、动态系统提示、请求限速、注入上下文 可修改 ModelRequest
wrap_model_call Wrap-style 包裹整个模型调用 模型替换、重试逻辑、缓存、超时控制、统一错误处理 可拦截并替换响应
after_model Node-style 每次模型调用后 响应验证、敏感词过滤、结果转换、条件路由 可修改 ModelResponse
wrap_tool_call Wrap-style 包裹每个工具调用 参数校验、错误恢复、执行监控、重试、审计日志 可拦截并替换 ToolMessage
after_agent Node-style Agent 图执行结束后 最终结果处理、数据落库、清理资源、汇总指标 可修改最终输出
dynamic_prompt Wrap-style 特例 模型调用前 根据 context/state 动态生成 system prompt 仅生成 prompt 文本
二、Node-style vs Wrap-style 核心区别
维度 Node-style Wrap-style
执行模式 作为独立节点在图中执行 作为包装器包裹目标函数
是否中断执行流 否,执行完继续下一个节点 是 ,包裹期间目标函数被“封印”
能否绕过目标函数 不能,目标函数一定会执行 能,可以选择不调用 handler 来跳过
典型场景 日志、校验、状态修改 重试、缓存、错误恢复、替换实现
复杂度 较低,按顺序执行 较高,需理解调用链
尤其重要!!!!!!!!!!!!!!!!!!!!!!!!!!!
Node-style(节点式) - 像"接力赛"
执行方式:像一个独立的跑步选手,跑完自己的那一棒,然后把接力棒交给下一个人
特点:
一定会执行(目标函数肯定会跑)
执行完就继续往下走,不会卡住
可以修改传递下去的数据,但不能阻止比赛继续
典型场景:日志记录、权限校验、状态修改(就像你在每个站点盖个章)
Wrap-style(包装式) - 像"俄罗斯套娃"
执行方式:像一个包装盒,把目标函数整个包在里面,你可以决定要不要打开盒子
特点:
目标函数被"封印"在包装里
可以选择不调用目标函数(比如缓存命中时直接返回)
可以完全替换目标函数的行为
典型场景:重试机制、缓存、错误恢复、模型替换(你可以决定是否真正执行原函数)
Node-style:看状态、改状态(通过返回值)
Wrap-style:截请求、替响应(通过返回结果)
"""
#2.1 @wrap_tool_call(最常用)拦截工具调用,用于重试、错误处理、日志记录。
"""
from langchain.agents.middleware import wrap_tool_call
from langchain_core.messages import ToolMessage
import time
import logging
logging.basicConfig(level=logging.INFO)
@wrap_tool_call
def monitored_tool_execution(request, handler):
#监控工具执行:记录开始/结束时间、参数、结果
tool_name = request.tool_call.get("name", "unknown")
tool_args = request.tool_call.get("args", {})
logging.info(f"开始执行工具: {tool_name}, 参数: {tool_args}")
start_time = time.time()
try:
result = handler(request) # 执行实际工具
elapsed = time.time() - start_time
logging.info(f"工具执行完成: {tool_name}, 耗时: {elapsed:.2f}s")
# 可选:在 ToolMessage 中添加元数据
if hasattr(result, "additional_kwargs"):
result.additional_kwargs["execution_time"] = elapsed
return result
except Exception as e:
elapsed = time.time() - start_time
logging.error(f"工具执行失败: {tool_name}, 耗时: {elapsed:.2f}s, 错误: {e}")
# 返回友好的错误消息,让 LLM 可以处理
return ToolMessage(
content=f"工具 {tool_name} 执行失败: {str(e)}",
tool_call_id=request.tool_call["id"]
)
"""
"""
request 的本质:它是当前执行点的完整上下文快照
你可以读取它(获取消息、状态、配置)
你可以修改它(影响后续中间件和实际调用)
handler 的本质:它是“继续执行”的函数引用
调用 handler(request) 意味着:“请执行剩下的中间件,最终完成实际调用”
不调用 handler 意味着:中断整个调用链(用于缓存、拦截等场景)
设计哲学:
这种设计源于责任链模式(Chain of Responsibility):
每个中间件可以决定是否将请求传递给下一个处理者
handler 就是“下一个处理者”的抽象;最终的处理者是真正的模型/工具调用
记忆口诀:
request 是你现在看到的
handler 是你接下来要做的
调用 handler 就继续往前走
不调用 handler 就到此为止
"""
#todo:充说明:1.关于invoke()消息输入的格式:
# invoke() 接收一个字典,这个字典会与 Agent 的当前状态合并。最关键的字段是 "messages":
# 3.1 格式一:单条用户消息(最常用)
# 方式1:字典格式(推荐,简洁)
result = agent.invoke({
"messages": [{"role": "user", "content": "帮我查天气"}]
})
# 方式2:消息对象格式
from langchain_core.messages import HumanMessage
result = agent.invoke({
"messages": [HumanMessage(content="帮我查天气")]
})
# 内部转换:LangChain 会自动将字典转为 HumanMessage
# 3.2 格式二:完整对话历史(恢复会话)
# 场景:从数据库加载历史对话,继续对话
historical_messages = [
{"role": "system", "content": "你是一个客服助手"},
{"role": "user", "content": "我的订单什么时候到?"},
{"role": "assistant", "content": "请提供订单号"},
{"role": "user", "content": "ORD-12345"},
{"role": "assistant", "content": "订单 ORD-12345 已发货,预计明天到达"},
]
# 新用户输入
new_user_message = {"role": "user", "content": "那能帮我改地址吗?"}
# 合并历史和新消息
result = agent.invoke({
"messages": historical_messages + [new_user_message]
})
# Agent 能看到完整上下文,知道用户指的是 ORD-12345 订单
# 3.3 格式三:包含系统消息(动态覆盖)
# 场景:每次调用可以动态修改系统提示
result = agent.invoke({
"messages": [
{"role": "system", "content": "你是一个专业的金融顾问,回答需简洁"}, # 临时覆盖
{"role": "user", "content": "什么是ETF?"}
]
})
# 注意:如果 Agent 创建时已有 system_prompt,这里的会追加或覆盖?
# 答案:取决于中间件配置。默认情况下,新传入的 system 消息会追加到现有系统提示之后
# 3.4 格式四:包含工具消息(人工注入工具结果)
# 场景:外部系统已经执行了某个操作,直接告诉 Agent 结果
from langchain_core.messages import ToolMessage
result = agent.invoke({
"messages": [
HumanMessage(content="帮我发送邮件给 john@example.com"),
# 人工注入工具执行结果(跳过实际工具调用)
ToolMessage(
content="邮件发送成功,ID: msg_12345",
tool_call_id="external_confirm" # 可以是任意标识
)
]
})
# 3.5 格式五:包含自定义状态(多租户/用户偏好)
# 场景:需要传递用户身份、租户信息等业务上下文
result = agent.invoke(
{
"messages": [{"role": "user", "content": "推荐几本机器学习书籍"}],
# 自定义状态字段(需要在 Agent 创建时声明 state_schema)
"user_id": "user_123",
"tenant_id": "tenant_abc",
"user_preferences": {
"language": "zh-CN",
"expertise_level": "beginner",
"topics": ["machine learning", "python"]
}
}
# 注意:如果通过 context_schema 传递,则用 context 参数
)
# 3.6 格式六:使用 context 参数(依赖注入)
# 场景:传递运行时上下文,不与状态持久化
# 适用于:用户身份、API 密钥、数据库连接等
result = agent.invoke(
{
"messages": [{"role": "user", "content": "查一下我的订单"}]
},
context={
"user_id": "user_123",
"db_connection": 'db_pool', # 数据库连接池
"api_key": "sk-xxx", # 第三方 API 密钥
"feature_flags": {"new_search": True}
}
)
# context 中的数据:
# - 可在中间件中通过 request.runtime.context 访问
# - 不会存储在 Agent 的 state 中(不持久化)
# - 适合每次调用不同的临时数据
# 3.7 格式七:使用 thread_id(会话隔离)
# 场景:多用户系统,每个用户独立会话
# 需要配合使用 with_config
result = agent.invoke(
{
"messages": [{"role": "user", "content": "继续上一轮的话题"}]
},
config={
"configurable": {
"thread_id": "user_session_12345" # 唯一会话标识
}
}
)
# 第二次调用,相同 thread_id,Agent 能记住历史
result2 = agent.invoke(
{
"messages": [{"role": "user", "content": "刚才我们聊到什么了?"}]
},
config={
"configurable": {
"thread_id": "user_session_12345" # 相同 ID
}
}
)
# Agent 会知道之前聊天的内容
LangChain 智能体(Agent)生产级开发指南:从入门到精通
前言:为什么需要智能体?
传统的 LLM 调用是单次推理:输入问题 → 输出答案。但在生产场景中,你需要解决复杂任务:
用户问“帮我查一下北京天气,如果下雨就推荐室内活动,否则推荐户外活动”
- 需要先查天气,再根据结果做不同处理
数据分析任务
- 生成 SQL → 执行 → 发现错误 → 修正 SQL → 再次执行 → 生成报告
一句话总结:智能体让 LLM 从“一次性回答者”变成“能够执行多步推理、调用工具、并根据结果自我修正的执行者”。
1. 智能体的运行时架构
create_agent 基于 LangGraph 构建了一个图结构运行时。这是理解智能体行为的关键:
2. 创建智能体:模型配置
模型是智能体的推理引擎,支持静态和动态选择。
2.1 静态模型配置
from langchain.agents import create_agent
import tools
# 方式1:字符串标识符(适合快速原型)
agent = create_agent("openai:gpt-5", tools=tools)
# 方式2:模型实例(生产推荐,完全控制)
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-4o",
temperature=0.1, # 低温度提高确定性
max_tokens=2000, # 控制成本
timeout=30, # 防止阻塞
max_retries=2 # 网络抖动自动重试
)
agent1 = create_agent(model, tools=tools)
生产建议:始终使用模型实例。字符串标识符虽然方便,但无法控制
temperature、timeout等关键参数。
2.2 动态模型选择(成本优化核心)
动态模型在运行时根据当前状态和上下文进行选择。这支持复杂的路由逻辑和成本优化。
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
basic_model = ChatOpenAI(model="gpt-4o-mini")
advanced_model = ChatOpenAI(model="gpt-4o")
@wrap_model_call
def dynamic_model_selection(request: ModelRequest, handler) -> ModelResponse:
"""根据对话复杂性选择模型。"""
message_count = len(request.state["messages"])
if message_count > 10:
# 对较长的对话使用高级模型
model1 = advanced_model
else:
model1 = basic_model
request.model = model1
return handler(request)
agent2 = create_agent(
model=basic_model, # 默认模型
tools=tools,
middleware=[dynamic_model_selection]
)
3. 中间件(Middleware):生产级的核心保障
3.1 为什么需要中间件?
在生产环境中,你需要的 Agent 不仅仅是“能回答问题”,还需要:
- 成本控制:防止模型无限调用导致账单爆炸
- 安全合规:过滤敏感信息(PII),防止数据泄露
- 稳定性:模型调用失败时自动降级,工具执行失败时重试
- 可观测性:记录每一步的输入输出,便于调试和审计
- 用户体验:在关键操作前请求人工确认,避免误操作
一句话总结:中间件让你能够在不修改 Agent 核心逻辑的前提下,注入横切关注点,实现生产级的安全、稳定和可控。
3.2 中间件在 LangGraph 执行图中的位置
3.3 生产级中间件详解
以下按照使用频率排序,逐一讲解每个中间件的“为什么、是什么、怎么用”。
3.3.1 ToolRetryMiddleware(工具重试)
为什么重要:工具调用可能因网络抖动、API 限流、临时错误而失败。自动重试能显著提高系统健壮性,避免用户看到“系统错误”。
使用频率:★★★★★(几乎所有生产系统都需要)
from langchain.agents import create_agent
from langchain.agents.middleware import ToolRetryMiddleware
from langchain.tools import tool
import time
import random
import dotenv
dotenv.load_dotenv()
@tool
def unstable_api_call(query: str) -> str:
"""模拟一个不稳定的 API 调用。"""
time.sleep(random.uniform(0.5, 2))
if random.random() < 0.1:
raise ConnectionError("API 临时不可用,请重试")
return f"API 调用成功,查询结果为:{query}"
# ToolRetryMiddleware 配置
retry_middleware = ToolRetryMiddleware(
max_retries=3, # 最大重试次数
backoff_factor=2.0, # 指数退避因子(重试间隔: 1, 2, 4 秒)
retry_on=(ConnectionError, TimeoutError), # 需要重试的异常类型
)
agent3 = create_agent(
model="deepseek-chat",
tools=[unstable_api_call],
middleware=[retry_middleware]
)
result = agent3.invoke({
"messages": [HumanMessage(content="查询次数")]})
print(f"{result}")
3.3.2 SummarizationMiddleware(对话摘要)
为什么重要:长对话会导致 token 超限,成本飙升。摘要中间件自动将历史对话压缩为摘要,保留关键信息的同时大幅降低成本。
使用频率:★★★★★(所有多轮对话系统都需要)
from langchain.agents.middleware import SummarizationMiddleware
from langchain.agents.middleware.summarization import ContextSize, ContextTokens
summary_middleware = SummarizationMiddleware(
trigger=ContextSize(max_tokens=4000),
keep=ContextTokens(max_tokens=10),
token_counter=lambda text: len(text.split()),
summary_prompt="请将以下对话压缩为简洁摘要,保留关键信息和上下文",
model='deepseek-chat'
)
agent3 = create_agent(
model="deepseek-chat",
tools=[],
middleware=[summary_middleware]
)
执行过程(内部数据流转):
- 初始状态:对话有 100 条消息,总 token = 5000
before_model钩子检测到超过阈值- 提取最近 5 条消息(保留)
- 将前 95 条消息发送给
summary_model生成摘要- 新状态:
[SystemMessage(content="对话摘要:用户询问天气..."), HumanMessage(...), AIMessage(...)]- 总 token 从 5000 降至 ~500
3.3.3 ModelCallLimitMiddleware(模型调用限制)
为什么重要:防止 Agent 陷入无限循环,或被恶意用户消耗大量 token 导致成本失控。这是成本控制的第一道防线。
使用频率:★★★★★(所有生产系统必备)
from langchain.agents.middleware import ModelCallLimitMiddleware
limit_middleware = ModelCallLimitMiddleware(
thread_limit=2,
run_limit=3,
exit_behavior="error"
)
agent4 = create_agent(
model="openai:gpt-4o",
tools=[],
middleware=[limit_middleware]
)
# 执行示例:一个复杂的多步任务
result = agent.invoke({
"messages": [{
"role": "user", "content": "分析财报并生成报告"}]
})
3.3.4 ModelFallbackMiddleware(模型降级)
为什么重要:主模型可能因服务故障、限流、配额耗尽而不可用。自动降级到备用模型是保障服务可用性的关键。
使用频率:★★★★☆(高可用系统必备)
from langchain.agents.middleware import ModelFallbackMiddleware
from langchain_openai import ChatOpenAI
from langchain_community.chat_models import ChatTongyi
# 配置主模型和备选模型
fallback_middleware = ModelFallbackMiddleware(
ChatOpenAI(model="gpt-4o-mini", temperature=0.5),
ChatOpenAI(model="gpt-3.5-turbo", temperature=0.3),
ChatTongyi(model="qwen-max", api_key="sk1234568790")
)
3.3.5 HumanInTheLoopMiddleware(人工确认)
为什么重要:对于可能产生重大影响的操作(如发送邮件、删除数据、转账),需要在执行前获得人工确认。这是 Agent 安全性的核心保障。
使用频率:★★★★☆(涉及关键操作的系统)
from langchain.agents.middleware import HumanInTheLoopMiddleware
hitl_middleware = HumanInTheLoopMiddleware(
interrupt_on={
"send_email": False,
}
)
3.3.6 ToolCallLimitMiddleware(工具调用限制)
为什么重要:防止 Agent 无限调用某个工具(如反复查询数据库),避免资源消耗和成本失控。
使用频率:★★★★☆
from langchain.agents.middleware import ToolCallLimitMiddleware
tool_limit_middleware = ToolCallLimitMiddleware(
tool_name="send_email",
thread_limit=3,
run_limit=3,
exit_behavior="error"
)
此外还有:
- PIIMiddleware(敏感信息检测与处理):合规要求(GDPR、CCPA)规定不能将用户敏感信息发送给第三方 API。PII 中间件在发送前检测并处理敏感数据。
4. 自定义中间件:装饰器详解
4.1 wrap_model_call 与 wrap_tool_call 的核心概念
Wrap(包裹):一种装饰器模式,在目标函数(模型调用或工具调用)外面包一层代码,让你能够在目标函数执行前后插入逻辑,甚至可以完全替换目标函数的执行。
def wrap_model_call(request, handler): # handler 就是原始函数 call_model print("【包裹层】调用前") response = handler(request) # 这里才真正执行原始函数 print("【包裹层】调用后") return response # 实际执行时 # response = wrap_model_call(request, call_model)request:请求的完整上下文快照。- 对于
wrap_model_call,它是ModelRequest对象,包含model,messages,state等。 - 对于
wrap_tool_call,它是ToolCallRequest对象,包含tool_call,tool,state等。
- 对于
handler:中间件链中的“下一步”执行者。调用handler(request)会执行后续所有中间件,并最终执行真正的模型/工具调用。
4.2 钩子类型总结
| 钩子类型 | 设计模式 | 执行时机 | 核心用途 | 是否可修改请求/响应 |
|---|---|---|---|---|
before_agent |
Node-style | Agent 图执行开始前 | 全局初始化、权限校验、日志记录 | 可修改初始 state |
before_model |
Node-style | 每次模型调用前 | 动态修改 messages、动态系统提示、请求限速 | 可修改 ModelRequest |
wrap_model_call |
Wrap-style | 包裹整个模型调用 | 模型替换、重试逻辑、缓存、超时控制 | 可拦截并替换响应 |
after_model |
Node-style | 每次模型调用后 | 响应验证、敏感词过滤、结果转换 | 可修改 ModelResponse |
wrap_tool_call |
Wrap-style | 包裹每个工具调用 | 参数校验、错误恢复、执行监控、重试 | 可拦截并替换 ToolMessage |
after_agent |
Node-style | Agent 图执行结束后 | 最终结果处理、数据落库、清理资源 | 可修改最终输出 |
4.3 Node-style vs Wrap-style 核心区别
| 维度 | Node-style | Wrap-style |
|---|---|---|
| 执行模式 | 作为独立节点在图中执行 | 作为包装器包裹目标函数 |
| 是否中断执行流 | 否,执行完继续下一个节点 | 是,包裹期间目标函数被“封印” |
| 能否绕过目标函数 | 不能,目标函数一定会执行 | 能,可以选择不调用 handler 来跳过 |
| 典型场景 | 日志、校验、状态修改 | 重试、缓存、错误恢复、替换实现 |
| 复杂度 | 较低,按顺序执行 | 较高,需理解调用链 |
记忆口诀:
request是你现在看到的handler是你接下来要做的- 调用
handler就继续往前走- 不调用
handler就到此为止
5. invoke() 消息输入的多种格式
invoke() 接收一个字典,这个字典会与 Agent 的当前状态合并。最关键的字段是 "messages"。
5.1 格式一:单条用户消息(最常用)
# 方式1:字典格式(推荐,简洁)
result = agent.invoke({
"messages": [{
"role": "user", "content": "帮我查天气"}]
})
# 方式2:消息对象格式
from langchain_core.messages import HumanMessage
result = agent.invoke({
"messages": [HumanMessage(content="帮我查天气")]
})
5.2 格式二:完整对话历史(恢复会话)
historical_messages = [
{
"role": "system", "content": "你是一个客服助手"},
{
"role": "user", "content": "我的订单什么时候到?"},
{
"role": "assistant", "content": "请提供订单号"},
{
"role": "user", "content": "ORD-12345"},
{
"role": "assistant", "content": "订单 ORD-12345 已发货,预计明天到达"},
]
new_user_message = {
"role": "user", "content": "那能帮我改地址吗?"}
result = agent.invoke({
"messages": historical_messages + [new_user_message]
})
# Agent 能看到完整上下文,知道用户指的是 ORD-12345 订单
5.3 格式三:包含系统消息(动态覆盖)
result = agent.invoke({
"messages": [
{
"role": "system", "content": "你是一个专业的金融顾问,回答需简洁"}, # 临时覆盖
{
"role": "user", "content": "什么是ETF?"}
]
})
注意:如果 Agent 创建时已有
system_prompt,这里的会追加或覆盖?答案取决于中间件配置。默认情况下,新传入的 system 消息会追加到现有系统提示之后。
5.4 格式四:包含工具消息(人工注入工具结果)
from langchain_core.messages import ToolMessage
result = agent.invoke({
"messages": [
HumanMessage(content="帮我发送邮件给 john@example.com"),
# 人工注入工具执行结果(跳过实际工具调用)
ToolMessage(
content="邮件发送成功,ID: msg_12345",
tool_call_id="external_confirm" # 可以是任意标识
)
]
})
5.5 格式五:包含自定义状态(多租户/用户偏好)
result = agent.invoke(
{
"messages": [{
"role": "user", "content": "推荐几本机器学习书籍"}],
# 自定义状态字段(需要在 Agent 创建时声明 state_schema)
"user_id": "user_123",
"tenant_id": "tenant_abc",
"user_preferences": {
"language": "zh-CN",
"expertise_level": "beginner",
"topics": ["machine learning", "python"]
}
}
# 注意:如果通过 context_schema 传递,则用 context 参数
)
5.6 格式六:使用 context 参数(依赖注入)
result = agent.invoke(
{
"messages": [{
"role": "user", "content": "查一下我的订单"}]
},
context={
"user_id": "user_123",
"db_connection": 'db_pool', # 数据库连接池
"api_key": "sk-xxx", # 第三方 API 密钥
"feature_flags": {
"new_search": True}
}
)
# context 中的数据:
# - 可在中间件中通过 request.runtime.context 访问
# - 不会存储在 Agent 的 state 中(不持久化)
# - 适合每次调用不同的临时数据
5.7 格式七:使用 thread_id(会话隔离)
# 第一次调用,开启一个会话
result = agent.invoke(
{
"messages": [{
"role": "user", "content": "你好,我叫小明"}]
},
config={
"configurable": {
"thread_id": "user_session_12345" # 唯一会话标识
}
}
)
# 第二次调用,相同 thread_id,Agent 能记住历史
result2 = agent.invoke(
{
"messages": [{
"role": "user", "content": "我叫什么名字?"}]
},
config={
"configurable": {
"thread_id": "user_session_12345" # 相同 ID
}
}
)
# Agent 会正确回答:你叫小明
希望这份整理后的笔记能对你有所帮助!记录自己的第一步
存档:书写于 2026.3.31.21:45😊

