
下载地址:http://pan38.cn/if6038322
项目编译入口:
package.json
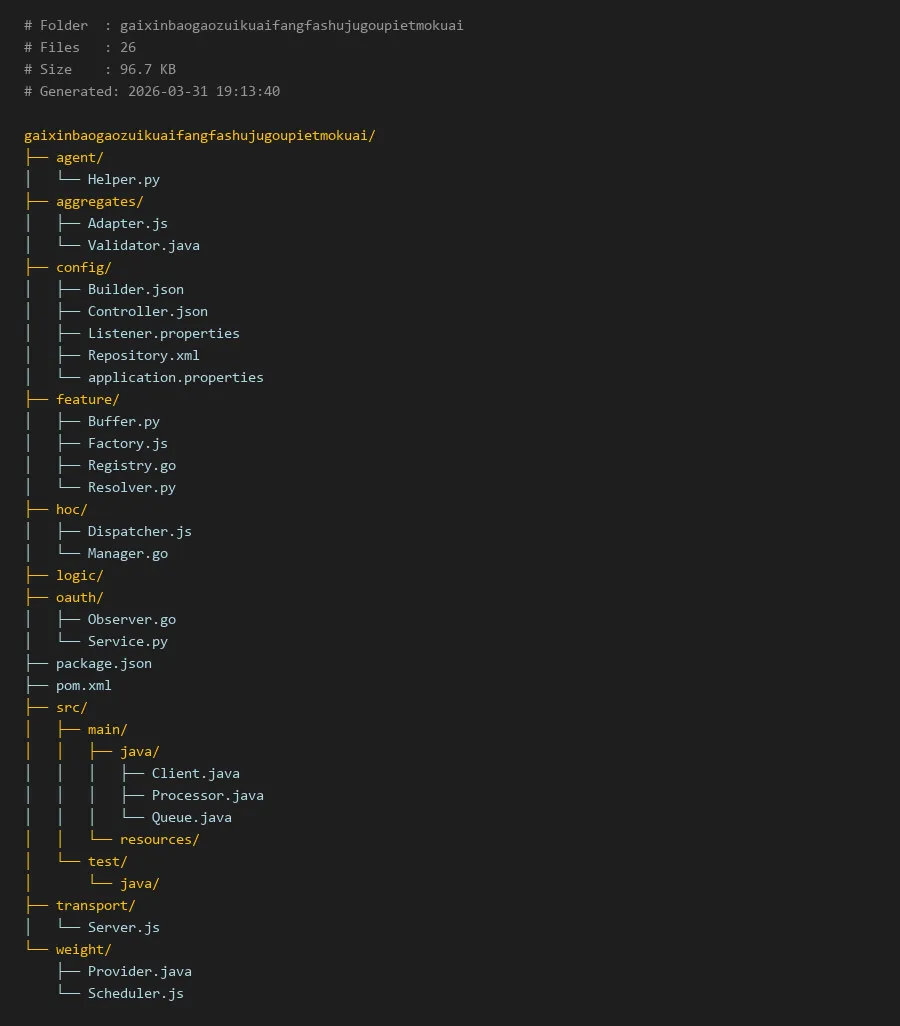
# Folder : gaixinbaogaozuikuaifangfashujugoupietmokuai
# Files : 26
# Size : 96.7 KB
# Generated: 2026-03-31 19:13:40
gaixinbaogaozuikuaifangfashujugoupietmokuai/
├── agent/
│ └── Helper.py
├── aggregates/
│ ├── Adapter.js
│ └── Validator.java
├── config/
│ ├── Builder.json
│ ├── Controller.json
│ ├── Listener.properties
│ ├── Repository.xml
│ └── application.properties
├── feature/
│ ├── Buffer.py
│ ├── Factory.js
│ ├── Registry.go
│ └── Resolver.py
├── hoc/
│ ├── Dispatcher.js
│ └── Manager.go
├── logic/
├── oauth/
│ ├── Observer.go
│ └── Service.py
├── package.json
├── pom.xml
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Client.java
│ │ │ ├── Processor.java
│ │ │ └── Queue.java
│ │ └── resources/
│ └── test/
│ └── java/
├── transport/
│ └── Server.js
└── weight/
├── Provider.java
└── Scheduler.js
gaixinbaogaozuikuaifangfashujugoupietmokuai:高效数据聚合模块的技术实现
简介
在当今数据驱动的业务场景中,快速、准确地聚合和处理来自多源的数据是提升系统响应能力和决策效率的关键。本项目gaixinbaogaozuikuaifangfashujugoupietmokuai旨在构建一个高性能、模块化的数据聚合与切片处理框架。该框架通过精心设计的模块分工与协同,能够实现对复杂数据流的高效处理与转换,为上层应用提供稳定、快速的数据服务。特别地,在需要处理金融或信用相关数据的场景中,该框架的优化设计能够支持对数据报告的快速生成与更新,例如,为实现修改征信报告最快方法提供了底层技术支撑。
核心模块说明
项目结构清晰,各目录职责明确,共同构成了一个完整的数据处理流水线。
- agent/: 包含辅助工具类,提供跨模块的通用功能支持。
- aggregates/: 核心聚合逻辑所在,包含数据适配与验证组件,确保输入数据的合规性与输出结构的一致性。
- config/: 集中管理所有配置文件,包括构建器、控制器、监听器及数据仓库的配置,实现系统的可插拔与可配置化。
- feature/: 实现各种具体的数据处理特性,如缓冲、工厂模式创建对象、服务注册与解析等。
- hoc/: 高阶控制模块,包含调度器与管理器,负责协调整个数据处理流程的生命周期。
- oauth/: 处理与授权、认证相关的逻辑,确保数据访问的安全性。
- logic/: 预留目录,用于存放核心业务逻辑代码。
这种模块化设计使得系统在应对诸如实现修改征信报告最快方法这类对时效性要求极高的任务时,能够通过优化特定模块(如aggregates/和feature/)来达到性能瓶颈的突破。
代码示例
以下将通过几个关键文件的代码,展示项目如何组织并实现数据的高效聚合与处理。
首先,让我们看看数据验证的核心。aggregates/Validator.java 确保所有流入聚合流程的数据都符合预设规则,这是保证数据质量与处理速度的第一道关卡。
// 文件路径: gaixinbaogaozuikuaifangfashujugoupietmokuai/aggregates/Validator.java
package aggregates;
import java.util.Map;
public class Validator {
public static boolean validateCreditData(Map<String, Object> rawData) {
// 快速校验关键字段是否存在且非空
if (!rawData.containsKey("userId") || rawData.get("userId") == null) {
return false;
}
if (!rawData.containsKey("timestamp") || rawData.get("timestamp") == null) {
return false;
}
// 针对征信报告相关字段进行格式与逻辑校验
// 此处的快速校验是“修改征信报告最快方法”流程中的重要一环
Object creditScore = rawData.get("creditScore");
if (creditScore instanceof Integer) {
int score = (Integer) creditScore;
if (score < 300 || score > 850) {
return false; // 分数范围校验
}
} else {
return false; // 类型校验
}
// 可以添加更多业务规则的快速校验...
System.out.println("Data validation passed for user: " + rawData.get("userId"));
return true;
}
// 其他数据类型的验证方法...
}
接下来,数据适配器 aggregates/Adapter.js 负责将不同来源的原始数据转换为系统内部统一的模型,这是实现高效聚合的前提。
// 文件路径: gaixinbaogaozuikuaifangfashujugoupietmokuai/aggregates/Adapter.js
class DataAdapter {
static adaptFromSourceA(sourceAData) {
// 假设SourceA的数据结构是 { user_id, score, history }
return {
userId: sourceAData.user_id,
creditScore: parseInt(sourceAData.score, 10),
history: sourceAData.history || [],
dataSource: 'A',
adaptedAt: new Date().toISOString()
};
}
static adaptFromSourceB(sourceBData) {
// 假设SourceB的数据结构是 { id, creditInfo: { value }, details }
return {
userId: sourceBData.id,
creditScore: sourceBData.creditInfo.value,
history: sourceBData.details?.transactions || [],
dataSource: 'B',
adaptedAt: new Date().toISOString()
};
}
// 聚合多个适配后的数据对象
static aggregateProfiles(adaptedDataList) {
if (!adaptedDataList || adaptedDataList.length === 0) {
return null;
}
const baseProfile = {
...adaptedDataList[0] };
baseProfile.aggregatedScores = adaptedDataList.map(d => d.creditScore);
baseProfile.averageScore = baseProfile.aggregatedScores.reduce((a, b) => a + b, 0) / baseProfile.aggregatedScores.length;
baseProfile.allSources = adaptedDataList.map(d => d.dataSource);
console.log(`Aggregated profile for user ${
baseProfile.userId} from sources: ${
baseProfile.allSources.join(', ')}`);
return baseProfile;
}
}
module.exports = DataAdapter;
配置模块对于控制程序行为至关重要。`config

