
下载地址:http://pan38.cn/i4dddb7fd
项目编译入口:
package.json
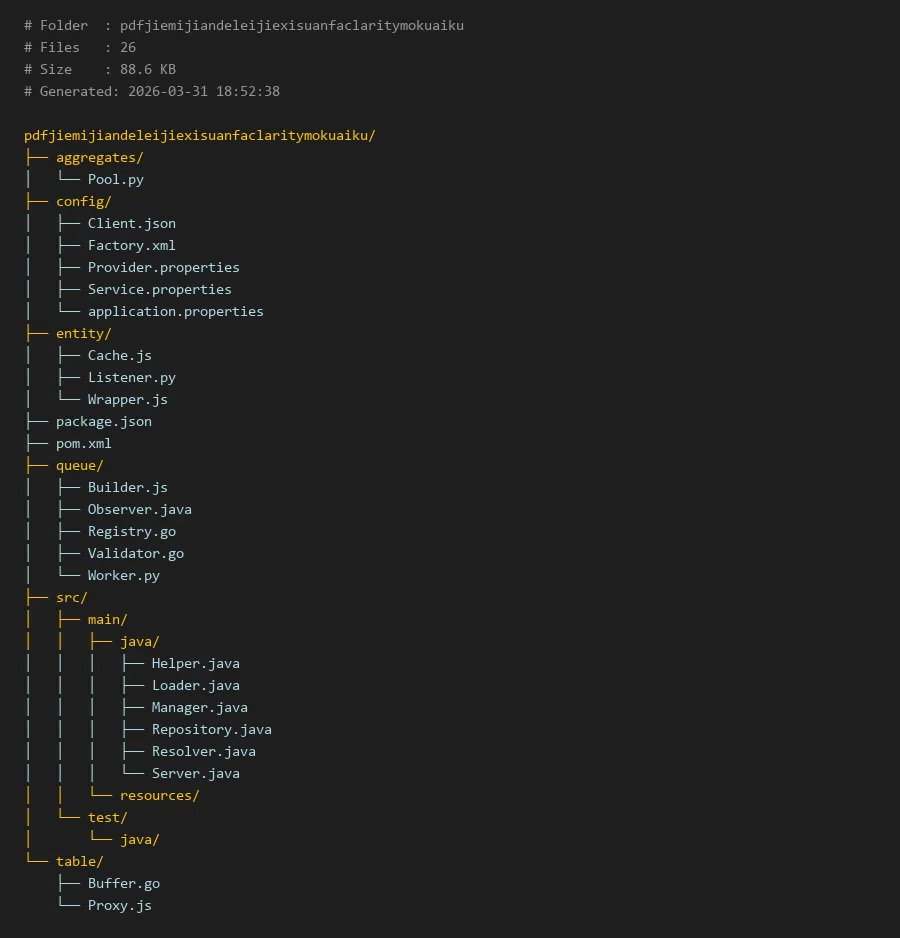
# Folder : pdfjiemijiandeleijiexisuanfaclaritymokuaiku
# Files : 26
# Size : 88.6 KB
# Generated: 2026-03-31 18:52:38
pdfjiemijiandeleijiexisuanfaclaritymokuaiku/
├── aggregates/
│ └── Pool.py
├── config/
│ ├── Client.json
│ ├── Factory.xml
│ ├── Provider.properties
│ ├── Service.properties
│ └── application.properties
├── entity/
│ ├── Cache.js
│ ├── Listener.py
│ └── Wrapper.js
├── package.json
├── pom.xml
├── queue/
│ ├── Builder.js
│ ├── Observer.java
│ ├── Registry.go
│ ├── Validator.go
│ └── Worker.py
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Helper.java
│ │ │ ├── Loader.java
│ │ │ ├── Manager.java
│ │ │ ├── Repository.java
│ │ │ ├── Resolver.java
│ │ │ └── Server.java
│ │ └── resources/
│ └── test/
│ └── java/
└── table/
├── Buffer.go
└── Proxy.js
pdfjiemijiandeleijiexisuanfaclaritymokuaiku:模块化PDF解密解析算法实现
简介
在当今数字化办公环境中,PDF文档因其跨平台和格式稳定的特性而广泛应用。然而,受保护的PDF文件常常给用户带来访问障碍,因此PDF解密技术成为数据处理中的重要环节。本项目pdfjiemijiandeleijiexisuanfaclaritymokuaiku旨在构建一个模块化、可扩展的PDF解密解析算法框架,通过清晰的模块划分实现高效、安全的解密处理。
市场上pdf解密软件的种类繁多,从简单的密码移除工具到复杂的加密算法破解系统,各有侧重。本项目不同于单一功能的解密工具,它采用模块化设计,将解密流程分解为独立的处理单元,便于维护和功能扩展。这种架构使得开发者能够根据具体需求灵活组合模块,适应不同场景下的解密需求。
核心模块说明
本项目按照功能职责将代码组织为多个核心模块,每个模块专注于特定任务:
配置模块(config/):集中管理应用程序的各种配置,包括客户端设置、服务参数和工厂模式配置。支持多种格式的配置文件,如JSON、XML和Properties,确保系统的灵活性。
实体模块(entity/):定义系统核心数据结构和监听机制。Cache.js处理缓存逻辑,Wrapper.js提供数据包装功能,Listener.py实现事件监听模式。
队列模块(queue/):负责任务调度和并发处理。该模块包含任务构建器、观察者、注册器、验证器和工作者等多个组件,实现高效的任务队列管理。
聚合模块(aggregates/):提供资源池管理功能,Pool.py实现了连接池或线程池模式,优化系统资源利用率。
源代码模块(src/):包含主要的Java实现代码,是解密算法的核心逻辑所在。
这种模块化设计使得系统在面对不同pdf解密软件的种类时,能够通过配置调整和模块替换来适应各种解密场景,提高了代码的复用性和可维护性。
代码示例
以下代码示例展示了本项目关键模块的实现方式,体现了模块间的协作关系。
1. 配置管理模块示例
首先查看配置模块中的客户端配置,该文件定义了解密服务的基本参数:
{
"client": {
"name": "PDFDecryptClient",
"version": "2.1.0",
"maxRetries": 3,
"timeout": 30000,
"algorithms": ["AES-256", "RC4-128", "Standard-128"],
"logLevel": "INFO"
},
"connection": {
"poolSize": 10,
"maxWaitTime": 5000
}
}
2. 实体模块中的缓存实现
实体模块中的Cache.js实现了基本的缓存机制,用于存储解密过程中的中间结果:
class PDFCache {
constructor(maxSize = 100) {
this.cache = new Map();
this.maxSize = maxSize;
this.accessOrder = [];
}
set(key, value) {
if (this.cache.size >= this.maxSize) {
const oldestKey = this.accessOrder.shift();
this.cache.delete(oldestKey);
}
this.cache.set(key, value);
this.accessOrder.push(key);
// 维护访问顺序,避免数组过大
if (this.accessOrder.length > this.maxSize * 2) {
this.accessOrder = this.accessOrder.slice(-this.maxSize);
}
return true;
}
get(key) {
if (!this.cache.has(key)) {
return null;
}
// 更新访问顺序
const index = this.accessOrder.indexOf(key);
if (index > -1) {
this.accessOrder.splice(index, 1);
this.accessOrder.push(key);
}
return this.cache.get(key);
}
clear() {
this.cache.clear();
this.accessOrder = [];
}
}
module.exports = PDFCache;
3. 队列模块中的工作者实现
队列模块中的Worker.py展示了任务处理的核心逻辑:
```python
import threading
import time
from queue import Queue
import logging
class DecryptWorker(threading.Thread):
def init(self, worker_id, task_queue, result_queue):
super().init()
self.worker_id = worker_id
self.task_queue = task_queue
self.result_queue = result_queue
self.running = True
self.logger = logging.getLogger(f"Worker-{worker_id}")
def run(self):
self.logger.info(f"Worker {self.worker_id} started")
while self.running:
try:
# 从任务队列获取任务,设置超时避免永久阻塞
task = self.task_queue.get(timeout=1)
if task is None: # 终止信号
break
self.logger.debug(f"Worker {self.worker_id} processing task: {task['id']}")
# 执行解密任务
result = self.process_decryption(task)
# 将结果放入结果队列
self.result_queue.put({
'task_id': task['id'],
'worker_id': self.worker_id,
'result': result,
'status': 'completed'
})
self.task_queue.task_done()
except Exception as e:
self.logger.error(f"Worker {self.worker_id} error: {str(e)}")
if task:
self.result_queue.put({
'task_id': task['

