
下载地址:http://pan38.cn/i3847b3ca
项目编译入口:
package.json
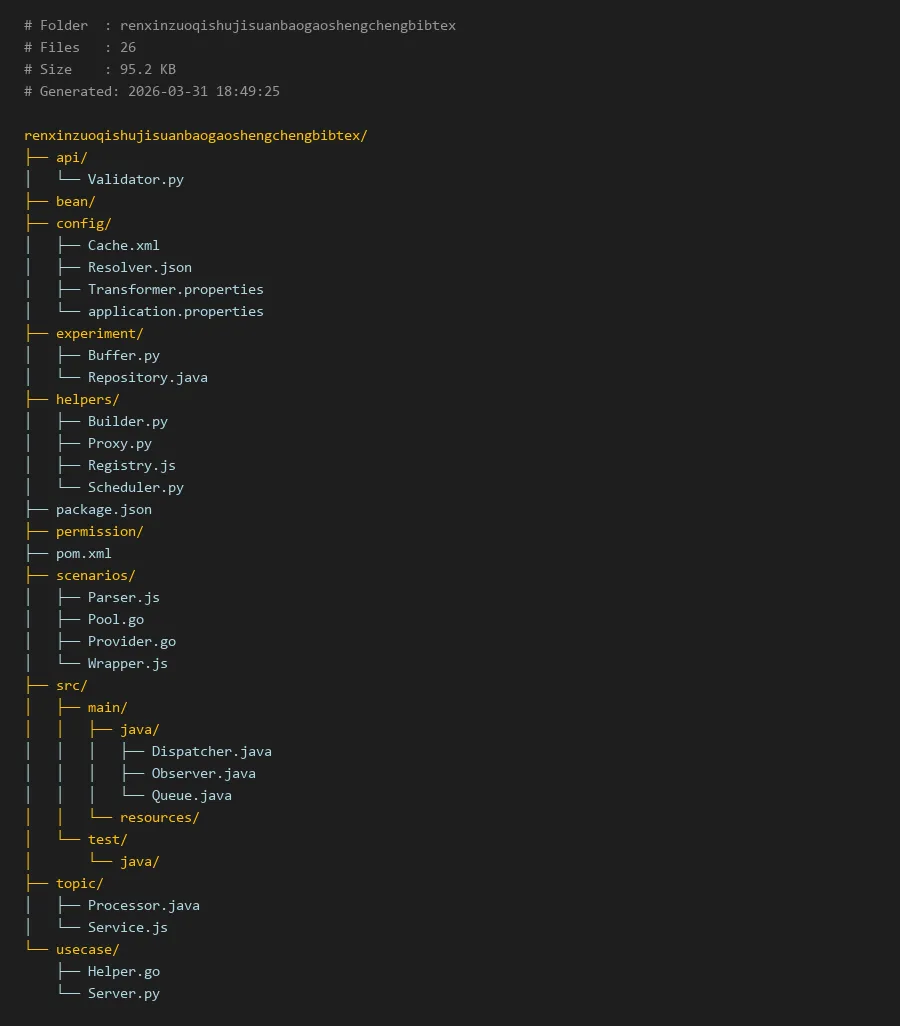
# Folder : renxinzuoqishujisuanbaogaoshengchengbibtex
# Files : 26
# Size : 95.2 KB
# Generated: 2026-03-31 18:49:25
renxinzuoqishujisuanbaogaoshengchengbibtex/
├── api/
│ └── Validator.py
├── bean/
├── config/
│ ├── Cache.xml
│ ├── Resolver.json
│ ├── Transformer.properties
│ └── application.properties
├── experiment/
│ ├── Buffer.py
│ └── Repository.java
├── helpers/
│ ├── Builder.py
│ ├── Proxy.py
│ ├── Registry.js
│ └── Scheduler.py
├── package.json
├── permission/
├── pom.xml
├── scenarios/
│ ├── Parser.js
│ ├── Pool.go
│ ├── Provider.go
│ └── Wrapper.js
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Dispatcher.java
│ │ │ ├── Observer.java
│ │ │ └── Queue.java
│ │ └── resources/
│ └── test/
│ └── java/
├── topic/
│ ├── Processor.java
│ └── Service.js
└── usecase/
├── Helper.go
└── Server.py
个人征信制作神器:数据计算报告生成与BibTeX集成
简介
在金融科技领域,个人征信报告的自动化生成与学术引用管理一直是个技术难点。传统方案往往需要人工处理大量数据,效率低下且容易出错。今天介绍的"renxinzuoqishujisuanbaogaoshengchengbibtex"项目,正是为解决这一痛点而生的个人征信制作神器。
这个开源工具集成了数据计算、报告生成和BibTeX引用管理三大功能,通过模块化设计实现了高度可配置的征信报告生成流程。项目采用多语言混合架构,充分利用各种编程语言的优势,为金融科技开发者提供了一套完整的解决方案。
核心模块说明
配置管理模块 (config/)
项目的核心配置集中在此目录,支持多种配置文件格式:
application.properties: 主配置文件,定义全局参数Transformer.properties: 数据转换规则配置Resolver.json: 解析器配置,定义数据源映射关系Cache.xml: 缓存策略配置,优化性能
数据处理模块 (helpers/)
包含各种辅助工具类:
Builder.py: 报告构建器,负责组装最终报告Proxy.py: 代理模式实现,用于数据源访问控制Registry.js: 组件注册中心,管理可插拔模块Scheduler.py: 任务调度器,控制报告生成流程
场景模块 (scenarios/)
针对不同征信场景的实现:
Parser.js: 数据解析器,处理原始征信数据Pool.go: 连接池管理,优化数据库访问Provider.go: 数据提供者,封装数据获取逻辑
验证模块 (api/)
Validator.py: 数据验证器,确保输入数据的合规性
代码示例
1. 配置文件示例
首先看主配置文件 config/application.properties:
# 征信报告生成配置
report.generator.version=2.1.0
report.output.format=PDF,BibTeX
report.template.path=/templates/credit_report
# 数据源配置
datasource.primary.type=SQL
datasource.secondary.type=NoSQL
datasource.cache.enabled=true
# BibTeX集成配置
bibtex.export.enabled=true
bibtex.style=ieee
bibtex.auto.generate=true
# 计算参数
calculation.risk.weight=0.7
calculation.credit.weight=0.3
calculation.precision=4
数据转换规则配置 config/Transformer.properties:
# 数据字段映射规则
personal.info.mapping=name,id_card,phone
credit.history.mapping=loan_records,repayment_history
risk.assessment.mapping=score,level,recommendation
# 转换函数
transform.date.format=yyyy-MM-dd
transform.currency.symbol=¥
transform.percentage.multiplier=100
# 验证规则
validation.id_card.pattern=^[1-9]\\d{5}(18|19|20)\\d{2}(0[1-9]|1[0-2])(0[1-9]|[1-2]\\d|3[0-1])\\d{3}([0-9X])$
validation.phone.pattern=^1[3-9]\\d{9}$
2. 报告构建器实现
helpers/Builder.py 是个人征信制作神器的核心组件:
```python
class CreditReportBuilder:
def init(self, config_path='config/application.properties'):
self.config = self._load_config(config_path)
self.components = {}
self.bibtex_entries = []
def _load_config(self, path):
"""加载配置文件"""
config = {}
try:
with open(path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if line and not line.startswith('#'):
key, value = line.split('=', 1)
config[key.strip()] = value.strip()
except FileNotFoundError:
print(f"配置文件 {path} 未找到")
return config
def add_component(self, name, component):
"""添加报告组件"""
self.components[name] = component
def generate_report(self, user_data):
"""生成征信报告"""
report = {
'metadata': self._generate_metadata(),
'sections': [],
'calculations': {},
'references': []
}
# 处理个人基本信息
if 'personal_info' in self.components:
personal_section = self.components['personal_info'].process(
user_data.get('personal', {})
)
report['sections'].append(personal_section)
# 执行信用评分计算
credit_score = self._calculate_credit_score(user_data)
report['calculations']['credit_score'] = credit_score
# 生成BibTeX引用
if self.config.get('bibtex.export.enabled') == 'true':
bibtex = self._generate_bibtex(user_data)
report['references'] = bibtex
self.bibtex_entries.extend(bibtex)
return report
def _calculate_credit_score(self, user_data):
"""计算信用评分"""
risk_weight = float(self.config.get('calculation.risk.weight', 0.7))
credit_weight = float(self.config.get('calculation.credit.weight', 0.3))
risk_score = self._calculate_

