
下载地址:http://pan38.cn/icfb09744
项目编译入口:
package.json
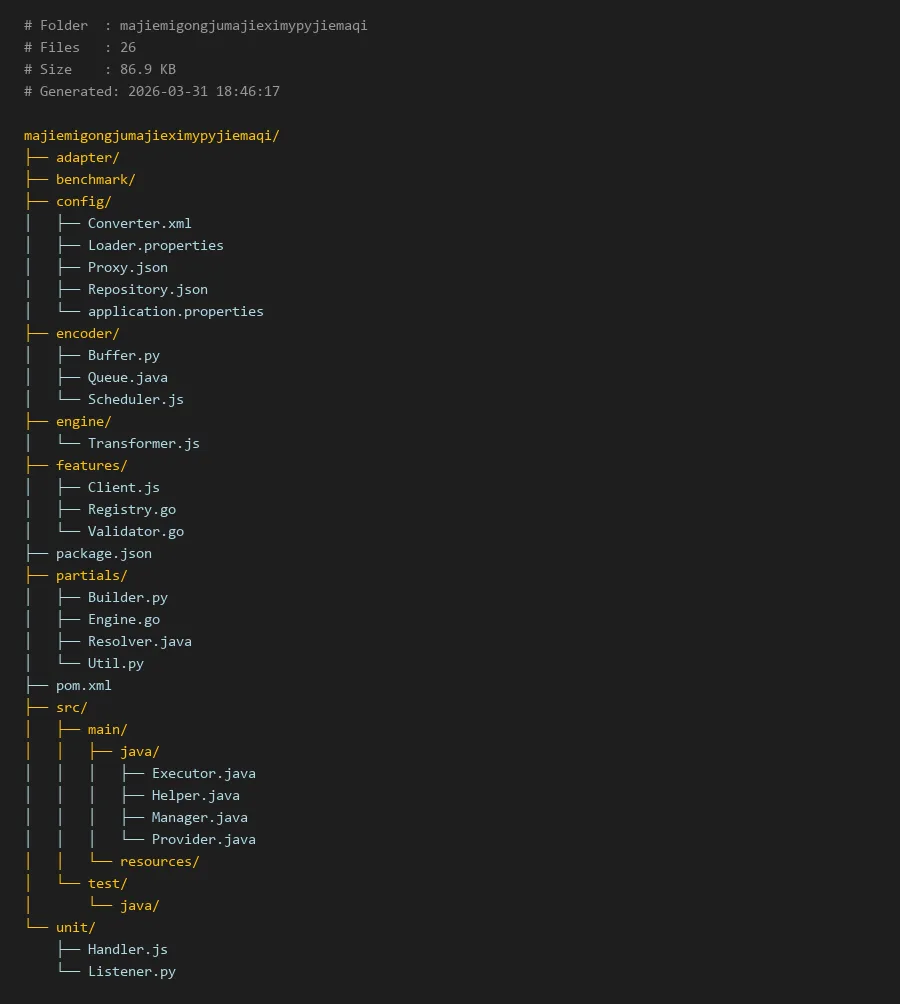
# Folder : majiemigongjumajieximypyjiemaqi
# Files : 26
# Size : 86.9 KB
# Generated: 2026-03-31 18:46:17
majiemigongjumajieximypyjiemaqi/
├── adapter/
├── benchmark/
├── config/
│ ├── Converter.xml
│ ├── Loader.properties
│ ├── Proxy.json
│ ├── Repository.json
│ └── application.properties
├── encoder/
│ ├── Buffer.py
│ ├── Queue.java
│ └── Scheduler.js
├── engine/
│ └── Transformer.js
├── features/
│ ├── Client.js
│ ├── Registry.go
│ └── Validator.go
├── package.json
├── partials/
│ ├── Builder.py
│ ├── Engine.go
│ ├── Resolver.java
│ └── Util.py
├── pom.xml
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Executor.java
│ │ │ ├── Helper.java
│ │ │ ├── Manager.java
│ │ │ └── Provider.java
│ │ └── resources/
│ └── test/
│ └── java/
└── unit/
├── Handler.js
└── Listener.py
majiemigongjumajieximypyjiemaqi:一个多语言乱码解密工具的实现
简介
majiemigongjumajieximypyjiemaqi 是一个专门用于处理各种编码乱码问题的多语言工具集。在现代软件开发中,我们经常遇到不同系统间数据交换时产生的编码混乱问题,特别是当数据经过多个中间件处理后,原始编码信息可能丢失或错误解析。这个项目通过统一的架构设计,支持多种编程语言实现,能够智能识别和转换各种常见的乱码情况。
该工具的核心价值在于其模块化设计,每个组件都专注于解决特定的编码问题。无论是处理中文字符的GBK/UTF-8混用,还是处理特殊符号的编码转换,这个乱码解密工具都能提供可靠的解决方案。项目采用多语言混合开发,充分利用各种语言在特定领域的优势,形成了一个功能强大的乱码解密工具生态系统。
核心模块说明
项目采用分层架构设计,主要包含以下几个核心模块:
配置层(config/):存放各种配置文件,包括转换规则、代理设置、应用属性等。这些配置文件定义了工具的行为和转换逻辑。
编码器层(encoder/):包含不同语言实现的编码处理组件,负责具体的编码转换操作。每个文件针对特定场景优化,如Buffer.py处理Python的字节缓冲,Queue.java处理Java的队列操作,Scheduler.js管理JavaScript的异步调度。
引擎层(engine/):核心转换引擎,Transformer.js实现了主要的编码转换算法,支持多种编码格式的自动检测和转换。
功能层(features/):提供具体的功能实现,如客户端连接、注册管理、数据验证等。
部分组件层(partials/):包含各种辅助工具和构建器,支持不同语言的特定需求。
代码示例
配置文件示例
让我们首先查看配置模块中的关键文件,这些文件定义了乱码解密的基本规则:
<!-- config/Converter.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<conversion-rules>
<rule name="gbk-to-utf8">
<source-encoding>GBK</source-encoding>
<target-encoding>UTF-8</target-encoding>
<priority>1</priority>
<description>将GBK编码转换为UTF-8编码</description>
</rule>
<rule name="iso8859-to-utf8">
<source-encoding>ISO-8859-1</source-encoding>
<target-encoding>UTF-8</target-encoding>
<priority>2</priority>
<description>将ISO-8859-1编码转换为UTF-8编码</description>
</rule>
<rule name="auto-detect">
<source-encoding>AUTO</source-encoding>
<target-encoding>UTF-8</target-encoding>
<priority>0</priority>
<description>自动检测源编码并转换为UTF-8</description>
</rule>
</conversion-rules>
# config/application.properties
# 乱码解密工具核心配置
decoder.max-buffer-size=1048576
decoder.default-charset=UTF-8
decoder.fallback-charset=ISO-8859-1
decoder.auto-detect=true
decoder.concurrent-threads=4
# 日志配置
logging.level.com.majiemi=DEBUG
logging.file=logs/decoder.log
编码器实现示例
编码器模块包含不同语言的实现,以下是Python缓冲处理的示例:
```python
encoder/Buffer.py
import codecs
from typing import Optional, Union
class DecodingBuffer:
"""处理乱码解码的缓冲器"""
def __init__(self, initial_size: int = 1024):
self.buffer = bytearray(initial_size)
self.position = 0
self.capacity = initial_size
def append(self, data: bytes) -> None:
"""向缓冲区添加数据"""
data_len = len(data)
if self.position + data_len > self.capacity:
self._resize(max(self.capacity * 2, self.position + data_len))
self.buffer[self.position:self.position + data_len] = data
self.position += data_len
def decode_with_fallback(self, encoding: str = 'utf-8',
fallback_encodings: list = None) -> str:
"""尝试使用多种编码解码,解决乱码问题"""
if fallback_encodings is None:
fallback_encodings = ['gbk', 'gb2312', 'big5', 'iso-8859-1']
encodings_to_try = [encoding] + fallback_encodings
for enc in encodings_to_try:
try:
result = self.buffer[:self.position].decode(enc)
# 验证解码结果是否包含常见乱码字符
if not self._contains_garbled_chars(result):
return result
except (UnicodeDecodeError, LookupError):
continue
# 所有编码都失败,使用替换策略
return self.buffer[:self.position].decode(encoding, errors='replace')
def _contains_garbled_chars(self, text: str) -> bool:
"""检测文本是否包含乱码字符"""
garbled_patterns = ['�', '��', '�']
for pattern in garbled_patterns:
if pattern in text:
return True

