
下载地址:http://pan38.cn/i0ce43a6e
项目编译入口:
package.json
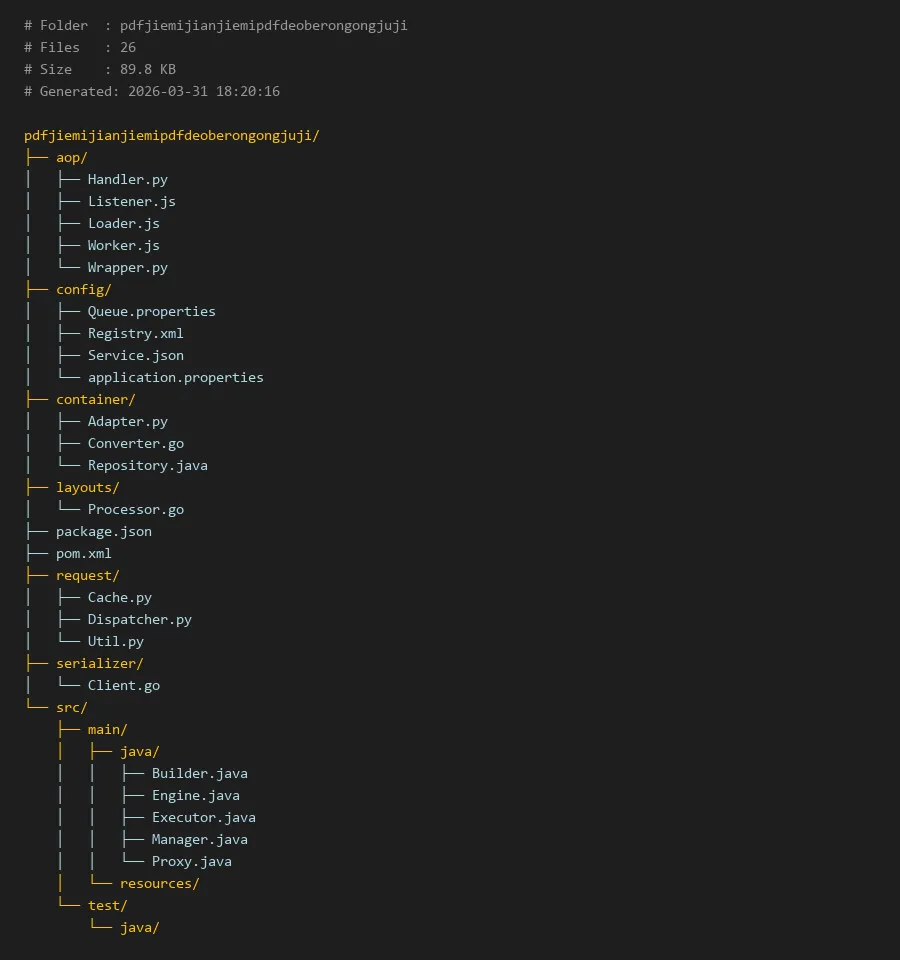
# Folder : pdfjiemijianjiemipdfdeoberongongjuji
# Files : 26
# Size : 89.8 KB
# Generated: 2026-03-31 18:20:16
pdfjiemijianjiemipdfdeoberongongjuji/
├── aop/
│ ├── Handler.py
│ ├── Listener.js
│ ├── Loader.js
│ ├── Worker.js
│ └── Wrapper.py
├── config/
│ ├── Queue.properties
│ ├── Registry.xml
│ ├── Service.json
│ └── application.properties
├── container/
│ ├── Adapter.py
│ ├── Converter.go
│ └── Repository.java
├── layouts/
│ └── Processor.go
├── package.json
├── pom.xml
├── request/
│ ├── Cache.py
│ ├── Dispatcher.py
│ └── Util.py
├── serializer/
│ └── Client.go
└── src/
├── main/
│ ├── java/
│ │ ├── Builder.java
│ │ ├── Engine.java
│ │ ├── Executor.java
│ │ ├── Manager.java
│ │ └── Proxy.java
│ └── resources/
└── test/
└── java/
pdfjiemijianjiemipdfdeoberongongjuji:一个模块化的PDF处理工具
简介
在当今数字化办公环境中,PDF文档因其跨平台、格式固定的特性而广泛应用。然而,加密的PDF文件常常给用户带来访问障碍,这时就需要专业的解密工具。许多用户会问"pdf解密软件哪个好",其实答案往往取决于具体需求。今天介绍的pdfjiemijianjiemipdfdeoberongongjuji项目,是一个开源的、模块化的PDF处理工具集,它采用多语言混合架构,提供了灵活的PDF解密和内容提取功能。
该项目采用微服务架构思想,将不同的功能模块分离,通过配置文件进行组装。这种设计使得系统具有高度的可扩展性和可维护性。项目结构清晰,包含AOP切面、配置管理、容器适配、请求处理等多个核心模块,每个模块都可以独立开发和测试。
核心模块说明
1. AOP切面模块(aop/)
这个目录包含了系统的横切关注点处理逻辑,采用面向切面编程思想:
Handler.py:Python实现的通用处理器,负责异常处理和日志记录Listener.js:JavaScript事件监听器,用于监控PDF处理状态Loader.js:动态加载模块的JavaScript实现Worker.js:工作线程管理,处理并发解密任务Wrapper.py:Python装饰器包装器,为函数添加额外功能
2. 配置模块(config/)
集中管理所有配置文件,支持多种格式:
Queue.properties:消息队列配置Registry.xml:服务注册与发现配置Service.json:微服务定义文件application.properties:主应用程序配置
3. 容器模块(container/)
提供依赖注入和对象管理功能:
Adapter.py:Python适配器模式实现,兼容不同PDF库Converter.go:Go语言实现的格式转换器Repository.java:Java数据访问层,管理PDF元数据
4. 布局处理模块(layouts/)
Processor.go:Go语言实现的PDF布局处理器,分析文档结构
5. 请求处理模块(request/)
处理用户请求和缓存:
Cache.py:Python实现的缓存机制,提升重复解密效率Dispatcher.py:请求分发器,路由到相应处理器Util.py:通用工具函数集合
代码示例
项目初始化配置
# config/application.properties 示例
pdf.decryption.algorithm=AES-256
pdf.decryption.max_attempts=3
pdf.decryption.timeout=30000
pdf.output.dir=./decrypted/
pdf.log.level=INFO
pdf.parallel.workers=4
PDF解密处理器实现
# aop/Handler.py 示例
import logging
from functools import wraps
from typing import Callable, Any
class PDFDecryptionHandler:
def __init__(self):
self.logger = logging.getLogger(__name__)
def error_handler(self, func: Callable) -> Callable:
@wraps(func)
def wrapper(*args, **kwargs) -> Any:
try:
self.logger.info(f"开始处理PDF解密: {args[0] if args else '未知文件'}")
result = func(*args, **kwargs)
self.logger.info("PDF解密处理完成")
return result
except Exception as e:
self.logger.error(f"PDF解密失败: {str(e)}")
raise
return wrapper
def performance_monitor(self, func: Callable) -> Callable:
@wraps(func)
def wrapper(*args, **kwargs) -> Any:
import time
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
self.logger.debug(f"函数 {func.__name__} 执行时间: {end_time - start_time:.2f}秒")
return result
return wrapper
容器适配器实现
```python
container/Adapter.py 示例
from abc import ABC, abstractmethod
import PyPDF2
import pikepdf
class PDFAdapter(ABC):
@abstractmethod
def decrypt(self, file_path: str, password: str) -> bool:
pass
@abstractmethod
def extract_text(self, file_path: str) -> str:
pass
class PyPDF2Adapter(PDFAdapter):
def decrypt(self, file_path: str, password: str) -> bool:
try:
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
if reader.is_encrypted:
return reader.decrypt(password)
return True
except Exception as e:
raise Exception(f"PyPDF2解密失败: {str(e)}")
def extract_text(self, file_path: str) -> str:
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
text += page.extract_text()
return text
class PikePDFAdapter(PDFAdapter):
def decrypt(self, file_path: str, password: str) -> bool:
try:
with pikepdf.open(file_path, password=password) as pdf:
return True
except pikepdf.PasswordError:
return False
except Exception as e:
raise Exception(f"Pike

