
下载地址:http://pan38.cn/i64e8bc04
项目编译入口:
package.json
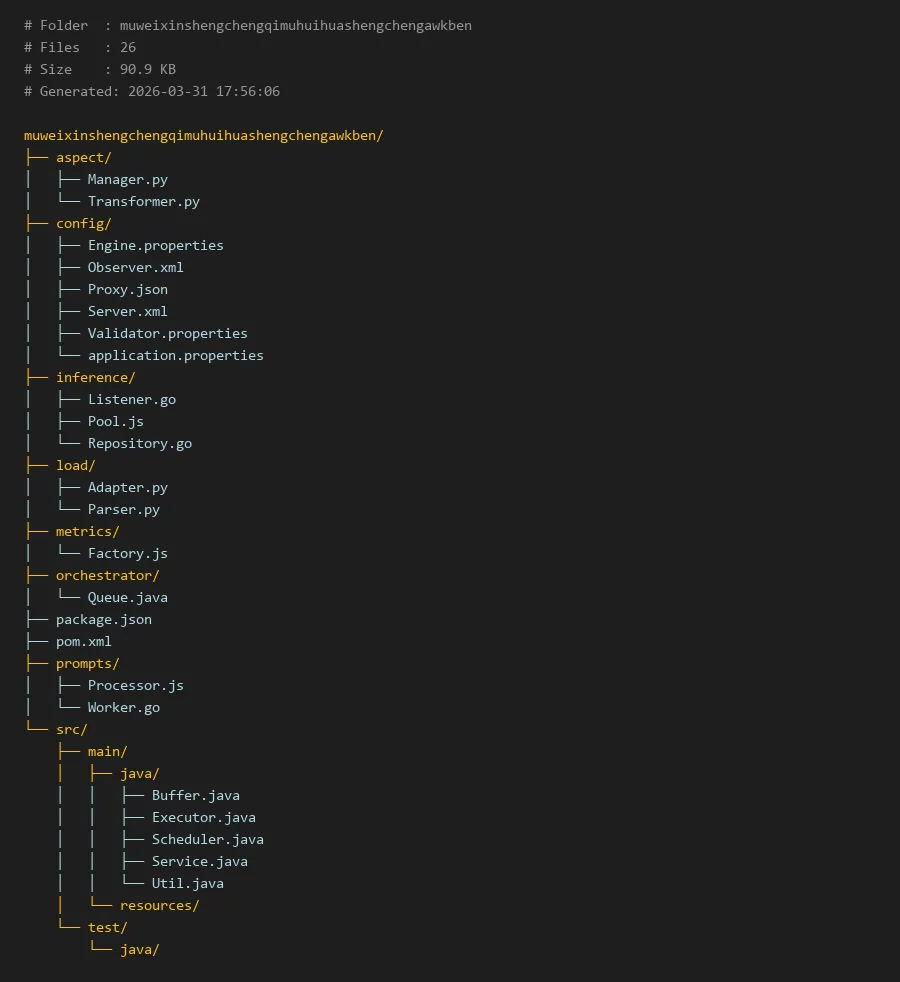
# Folder : muweixinshengchengqimuhuihuashengchengawkben
# Files : 26
# Size : 90.9 KB
# Generated: 2026-03-31 17:56:06
muweixinshengchengqimuhuihuashengchengawkben/
├── aspect/
│ ├── Manager.py
│ └── Transformer.py
├── config/
│ ├── Engine.properties
│ ├── Observer.xml
│ ├── Proxy.json
│ ├── Server.xml
│ ├── Validator.properties
│ └── application.properties
├── inference/
│ ├── Listener.go
│ ├── Pool.js
│ └── Repository.go
├── load/
│ ├── Adapter.py
│ └── Parser.py
├── metrics/
│ └── Factory.js
├── orchestrator/
│ └── Queue.java
├── package.json
├── pom.xml
├── prompts/
│ ├── Processor.js
│ └── Worker.go
└── src/
├── main/
│ ├── java/
│ │ ├── Buffer.java
│ │ ├── Executor.java
│ │ ├── Scheduler.java
│ │ ├── Service.java
│ │ └── Util.java
│ └── resources/
└── test/
└── java/
muweixinshengchengqimuhuihuashengchengawkben:模拟微信聊天生成器的技术实现
简介
在自然语言处理和对话生成领域,构建高质量的聊天模拟系统一直是个挑战。muweixinshengchengqimuhuihuashengchengawkben项目提供了一个完整的解决方案,专门用于生成逼真的微信风格对话。这个项目通过多语言混合架构和模块化设计,实现了从数据加载到对话生成的完整流程。本文将深入探讨该项目的核心模块,并通过具体代码示例展示如何构建一个功能完善的模拟微信聊天生成器。
核心模块说明
项目采用分层架构设计,主要包含以下核心模块:
- 配置管理模块 (config/):集中管理所有配置文件,支持多种格式(properties、XML、JSON)
- 数据加载模块 (load/):负责数据解析和适配,支持多种数据源格式
- 切面处理模块 (aspect/):实现横切关注点,如日志、监控和转换逻辑
- 推理引擎模块 (inference/):核心的对话生成和响应处理逻辑
- 编排模块 (orchestrator/):管理任务队列和流程协调
- 指标监控模块 (metrics/):收集和报告系统性能指标
代码示例
1. 配置管理模块示例
首先让我们查看配置文件的加载和解析机制。项目支持多种配置格式,以下是JSON配置的解析示例:
# config/Proxy.json 配置文件示例
{
"proxy_settings": {
"enabled": true,
"max_connections": 100,
"timeout": 30,
"retry_attempts": 3,
"conversation_templates": [
"casual_chat",
"business_discussion",
"friend_conversation"
]
},
"generation_parameters": {
"temperature": 0.7,
"max_length": 200,
"top_p": 0.9,
"repetition_penalty": 1.2
}
}
2. 数据加载模块实现
数据加载模块负责处理不同格式的输入数据。以下是Python解析器的核心实现:
# load/Parser.py
import json
import xml.etree.ElementTree as ET
import yaml
from datetime import datetime
class DataParser:
def __init__(self, config_path):
self.config = self._load_config(config_path)
self.conversation_cache = {
}
def _load_config(self, path):
"""加载配置文件"""
with open(path, 'r', encoding='utf-8') as f:
if path.endswith('.json'):
return json.load(f)
elif path.endswith('.xml'):
return self._parse_xml(f.read())
elif path.endswith('.properties'):
return self._parse_properties(f)
def parse_conversation_data(self, raw_data, data_type='json'):
"""解析对话数据"""
if data_type == 'json':
return self._parse_json_conversation(raw_data)
elif data_type == 'xml':
return self._parse_xml_conversation(raw_data)
else:
raise ValueError(f"Unsupported data type: {data_type}")
def _parse_json_conversation(self, json_data):
"""解析JSON格式的对话数据"""
conversations = []
for conv in json_data.get('conversations', []):
parsed_conv = {
'id': conv['id'],
'participants': conv['participants'],
'messages': [],
'metadata': conv.get('metadata', {
})
}
for msg in conv['messages']:
parsed_msg = {
'sender': msg['sender'],
'content': msg['content'],
'timestamp': datetime.fromisoformat(msg['timestamp']),
'message_type': msg.get('type', 'text')
}
parsed_conv['messages'].append(parsed_msg)
conversations.append(parsed_conv)
return conversations
3. 切面处理模块示例
切面模块提供了横切关注点的统一处理。以下是Transformer类的实现:
```python
aspect/Transformer.py
import re
from typing import Dict, List, Any
class ConversationTransformer:
"""对话数据转换器"""
def __init__(self):
self.wechat_patterns = {
'voice_call': r'\[语音通话\]',
'video_call': r'\[视频通话\]',
'red_packet': r'\[微信红包\]',
'location': r'\[位置\]',
'emoji': r'\[表情\]'
}
def transform_to_wechat_format(self, conversation: Dict[str, Any]) -> Dict[str, Any]:
"""将普通对话转换为微信格式"""
transformed = {
'chat_id': conversation['id'],
'participants': self._format_participants(conversation['participants']),
'messages': [],
'settings': {
'theme': 'default',
'notification': True
}
}
for msg in conversation['messages']:
wechat_msg = self._convert_message_to_wechat(msg)
transformed['messages'].append(wechat_msg)
return transformed
def _convert_message_to_wechat(self, message: Dict) -> Dict:
"""转换单条消息为微信格式"""
content = message['content']
# 检测并转换特殊

