
下载地址:http://pan38.cn/ib543436e
项目编译入口:
package.json
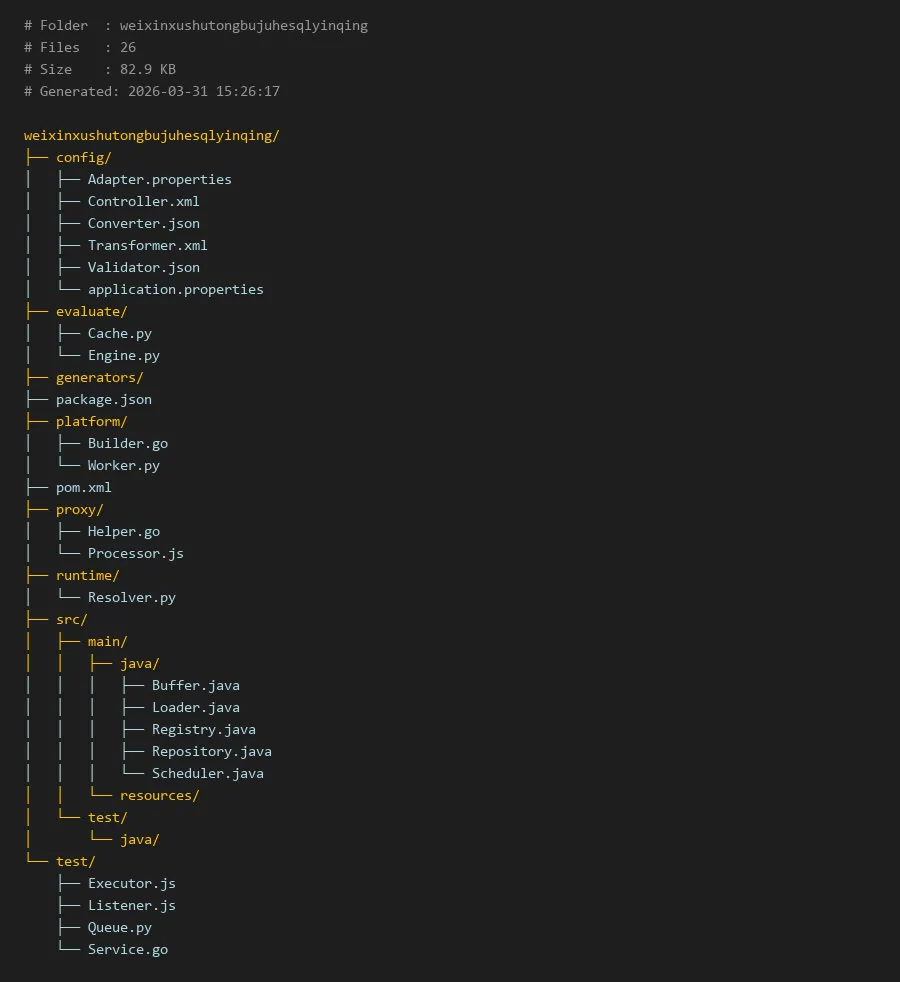
# Folder : weixinxushutongbujuhesqlyinqing
# Files : 26
# Size : 82.9 KB
# Generated: 2026-03-31 15:26:17
weixinxushutongbujuhesqlyinqing/
├── config/
│ ├── Adapter.properties
│ ├── Controller.xml
│ ├── Converter.json
│ ├── Transformer.xml
│ ├── Validator.json
│ └── application.properties
├── evaluate/
│ ├── Cache.py
│ └── Engine.py
├── generators/
├── package.json
├── platform/
│ ├── Builder.go
│ └── Worker.py
├── pom.xml
├── proxy/
│ ├── Helper.go
│ └── Processor.js
├── runtime/
│ └── Resolver.py
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Buffer.java
│ │ │ ├── Loader.java
│ │ │ ├── Registry.java
│ │ │ ├── Repository.java
│ │ │ └── Scheduler.java
│ │ └── resources/
│ └── test/
│ └── java/
└── test/
├── Executor.js
├── Listener.js
├── Queue.py
└── Service.go
weixinxushutongbujuhesqlyinqing:微信虚拟余额聚合SQL引擎技术解析
简介
weixinxushutongbujuhesqlyinqing是一个专门为微信虚拟余额场景设计的聚合SQL查询引擎。在复杂的金融业务中,特别是涉及微信虚拟余额的多维度统计场景,传统数据库查询往往面临性能瓶颈和业务逻辑复杂的问题。本项目通过构建一个中间层引擎,将分散的数据源聚合处理,提供统一的SQL查询接口,显著提升了查询效率和开发体验。
该引擎支持多数据源适配、实时数据转换和智能缓存策略,特别适合处理高并发的微信虚拟余额查询请求。项目采用模块化设计,包含配置管理、查询引擎、代理层、运行时解析等核心模块,支持Java、Python、Go等多种语言组件协同工作。
核心模块说明
配置模块 (config/)
配置模块是整个引擎的神经中枢,负责管理所有运行时配置:
application.properties:全局应用配置,包含数据库连接、线程池大小等Adapter.properties:数据源适配器配置,定义不同数据源的连接参数Controller.xml:查询路由控制规则,指定不同SQL模式的处理逻辑Converter.json:数据转换规则,定义字段映射和类型转换Transformer.xml:查询语句转换规则,用于SQL重写和优化Validator.json:查询参数验证规则,确保输入安全性
查询引擎模块 (evaluate/)
这是核心计算模块,负责SQL解析和执行:
Engine.py:主查询引擎,实现SQL解析、执行计划生成和结果聚合Cache.py:智能缓存管理,支持多级缓存策略和缓存失效机制
平台模块 (platform/)
提供基础平台能力:
Builder.go:查询构建器,将解析后的SQL转换为可执行任务Worker.py:工作节点管理,负责任务分发和执行监控
代理模块 (proxy/)
处理客户端请求和协议转换:
Helper.go:请求辅助工具,处理连接池和负载均衡Processor.js:请求处理器,实现HTTP/WebSocket协议支持
运行时模块 (runtime/)
Resolver.py:运行时解析器,处理动态SQL和参数绑定
源代码模块 (src/)
Java核心实现:
Buffer:数据缓冲区实现,支持流式处理
代码示例
1. 配置模块示例
首先查看全局配置文件,了解引擎的基本配置:
# application.properties
engine.name=weixinxushutongbujuhesqlyinqing
engine.version=2.1.0
datasource.primary.type=mysql
datasource.primary.url=jdbc:mysql://localhost:3306/wechat_balance
datasource.primary.username=admin
datasource.primary.password=encrypted_password
datasource.secondary.type=redis
datasource.secondary.url=redis://localhost:6379/0
cache.enabled=true
cache.ttl=300
query.timeout=5000
max.connections=100
数据源适配器配置定义了如何处理不同的数据源:
# Adapter.properties
mysql.adapter.class=com.wechat.sql.MySQLAdapter
mysql.adapter.driver=com.mysql.cj.jdbc.Driver
mysql.adapter.pool.size=20
redis.adapter.class=com.wechat.cache.RedisAdapter
redis.adapter.max.idle=10
redis.adapter.max.total=50
mongo.adapter.class=com.wechat.nosql.MongoAdapter
mongo.adapter.connection.per.host=10
查询控制规则定义了SQL路由逻辑:
<!-- Controller.xml -->
<controllers>
<controller pattern="SELECT.*FROM wechat_virtual_balance">
<route to="primary" />
<cache enabled="true" ttl="60" />
<transformer ref="balance_transformer" />
</controller>
<controller pattern="SELECT.*FROM user_transaction.*WHERE.*time >">
<route to="secondary" />
<parallel enabled="true" workers="4" />
<validator ref="time_validator" />
</controller>
<controller pattern="INSERT.*UPDATE.*DELETE.*">
<route to="primary" />
<cache invalidate="true" />
<audit enabled="true" />
</controller>
</controllers>
2. 查询引擎核心实现
查询引擎的主逻辑实现,展示如何处理微信虚拟余额查询:
```python
evaluate/Engine.py
import sqlparse
from datetime import datetime
from typing import Dict, List, Any
from .Cache import QueryCache
class SQLQueryEngine:
def init(self, config_path: str):
self.config = self._load_config(config_path)
self.cache = QueryCache(
max_size=self.config['cache']['max_size'],
ttl=self.config['cache']['ttl']
)
self.adapters = self._init_adapters()
def execute_query(self, sql: str, params: Dict[str, Any] = None) -> List[Dict]:
"""执行SQL查询,支持参数化查询"""
# 检查缓存
cache_key = self._generate_cache_key(sql, params)
cached_result = self.cache.get(cache_key)
if cached_result:
return cached_result
# 解析SQL
parsed = sqlparse.parse(sql)[0]
# 路由决策
route_info = self._determine_route(

