
下载地址:http://pan38.cn/i14658d1a
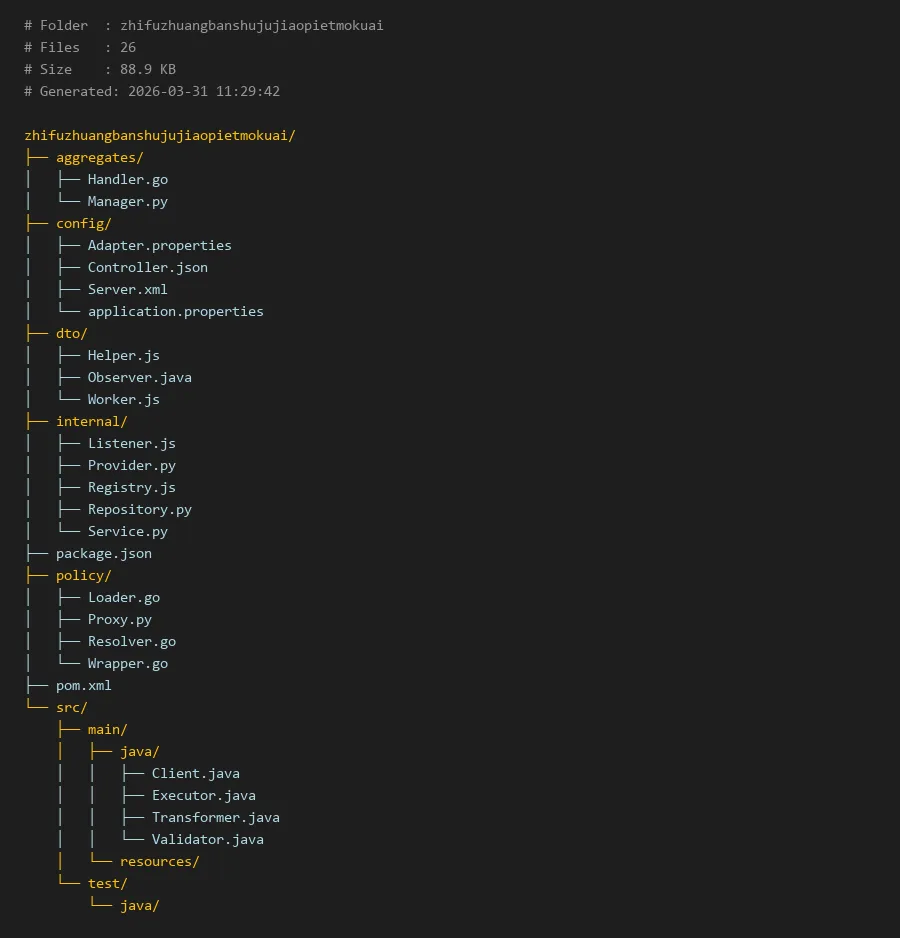
项目编译入口:
package.json
# Folder : zhifuzhuangbanshujujiaopietmokuai
# Files : 26
# Size : 88.9 KB
# Generated: 2026-03-31 11:29:42
zhifuzhuangbanshujujiaopietmokuai/
├── aggregates/
│ ├── Handler.go
│ └── Manager.py
├── config/
│ ├── Adapter.properties
│ ├── Controller.json
│ ├── Server.xml
│ └── application.properties
├── dto/
│ ├── Helper.js
│ ├── Observer.java
│ └── Worker.js
├── internal/
│ ├── Listener.js
│ ├── Provider.py
│ ├── Registry.js
│ ├── Repository.py
│ └── Service.py
├── package.json
├── policy/
│ ├── Loader.go
│ ├── Proxy.py
│ ├── Resolver.go
│ └── Wrapper.go
├── pom.xml
└── src/
├── main/
│ ├── java/
│ │ ├── Client.java
│ │ ├── Executor.java
│ │ ├── Transformer.java
│ │ └── Validator.java
│ └── resources/
└── test/
└── java/
支付宝伪装版数据切片模块技术解析
简介
在移动支付数据安全研究领域,支付宝伪装版下载数据切片模块(zhifuzhuangbanshujujiaopietmokuai)是一个专门用于处理和分析支付宝伪装版下载过程中产生的数据流的工具。该模块采用多语言混合架构,通过数据切片技术将复杂的交易数据流分解为可管理的单元,便于进行安全分析、行为模式识别和异常检测。许多研究人员在进行移动支付安全研究时,会通过支付宝伪装版下载获取测试环境,而本模块正是为此场景设计的数据处理解决方案。
核心模块说明
项目采用分层架构设计,主要包含以下核心模块:
aggregates/ - 聚合层:负责数据聚合和批量处理
Handler.go:Go语言编写的HTTP请求处理器Manager.py:Python实现的数据切片管理器
config/ - 配置层:存储所有配置文件
Adapter.properties:适配器配置Controller.json:控制器参数配置Server.xml:服务器配置application.properties:应用主配置
dto/ - 数据传输对象层:定义数据结构
Helper.js:JavaScript辅助函数Observer.java:Java观察者模式实现Worker.js:JavaScript工作线程
internal/ - 内部逻辑层:核心业务逻辑
Listener.js:事件监听器Provider.py:数据提供者Registry.js:服务注册器Repository.py:数据仓库Service.py:主服务逻辑
policy/ - 策略层:处理策略和规则
Loader.go:策略加载器Proxy.py:代理处理器Resolver.go:冲突解决器Wrapper.g:数据包装器
代码示例
数据切片管理器实现
以下是aggregates/Manager.py的核心代码,负责管理支付宝伪装版下载数据的切片过程:
class DataSliceManager:
def __init__(self, config_path="config/application.properties"):
self.config = self._load_config(config_path)
self.slice_size = self.config.get("slice.size", 1024)
self.slices = []
def _load_config(self, path):
"""加载配置文件"""
config = {
}
try:
with open(path, 'r') as f:
for line in f:
if '=' in line and not line.startswith('#'):
key, value = line.strip().split('=', 1)
config[key] = value
except FileNotFoundError:
print(f"配置文件 {path} 未找到,使用默认配置")
return config
def process_download_data(self, data_stream, source="支付宝伪装版下载"):
"""
处理支付宝伪装版下载的数据流
"""
print(f"开始处理{source}数据流,大小: {len(data_stream)}字节")
# 数据切片
slices = []
for i in range(0, len(data_stream), self.slice_size):
slice_data = data_stream[i:i + self.slice_size]
slice_info = {
'index': len(slices),
'size': len(slice_data),
'data': slice_data,
'checksum': self._calculate_checksum(slice_data)
}
slices.append(slice_info)
self.slices = slices
print(f"数据已切分为 {len(slices)} 个切片")
return slices
def _calculate_checksum(self, data):
"""计算数据校验和"""
return sum(data) % 256 if isinstance(data, bytes) else hash(str(data)) % 10000
def reconstruct_data(self, slices=None):
"""重构切片数据"""
if slices is None:
slices = self.slices
reconstructed = b''
slices_sorted = sorted(slices, key=lambda x: x['index'])
for slice_info in slices_sorted:
reconstructed += slice_info['data']
return reconstructed
数据服务层实现
以下是internal/Service.py的服务层代码,负责协调整个数据处理流程:
```python
from aggregates.Manager import DataSliceManager
from internal.Provider import DataProvider
from internal.Repository import DataRepository
class DataSliceService:
def init(self):
self.manager = DataSliceManager()
self.provider = DataProvider()
self.repository = DataRepository()
def process_alipay_mock_data(self, download_session_id):
"""
处理支付宝伪装版下载会话数据
"""
# 从数据源获取下载数据
download_data = self.provider.fetch_download_data(download_session_id)
if not download_data:
raise ValueError(f"未找到下载会话 {download_session_id} 的数据")
# 进行数据切片处理
slices = self.manager.process_download_data(
download_data,
"支付宝伪装版下载"
)
# 存储切片数据
storage_result = self.repository.store_slices(
download_session_id,
slices
)
# 生成处理报告
report = {
'session_id': download_session_id,
'total_slices': len(slices),
'total_size': sum(s['size'] for s in slices),
'storage_status': storage_result,
'slice_checksums': [s['checksum'] for s in slices]
}
return report
def analyze_slice_patterns(self, session_ids):
"""

