
下载地址:http://pan38.cn/i3bb058a3
项目编译入口:
package.json
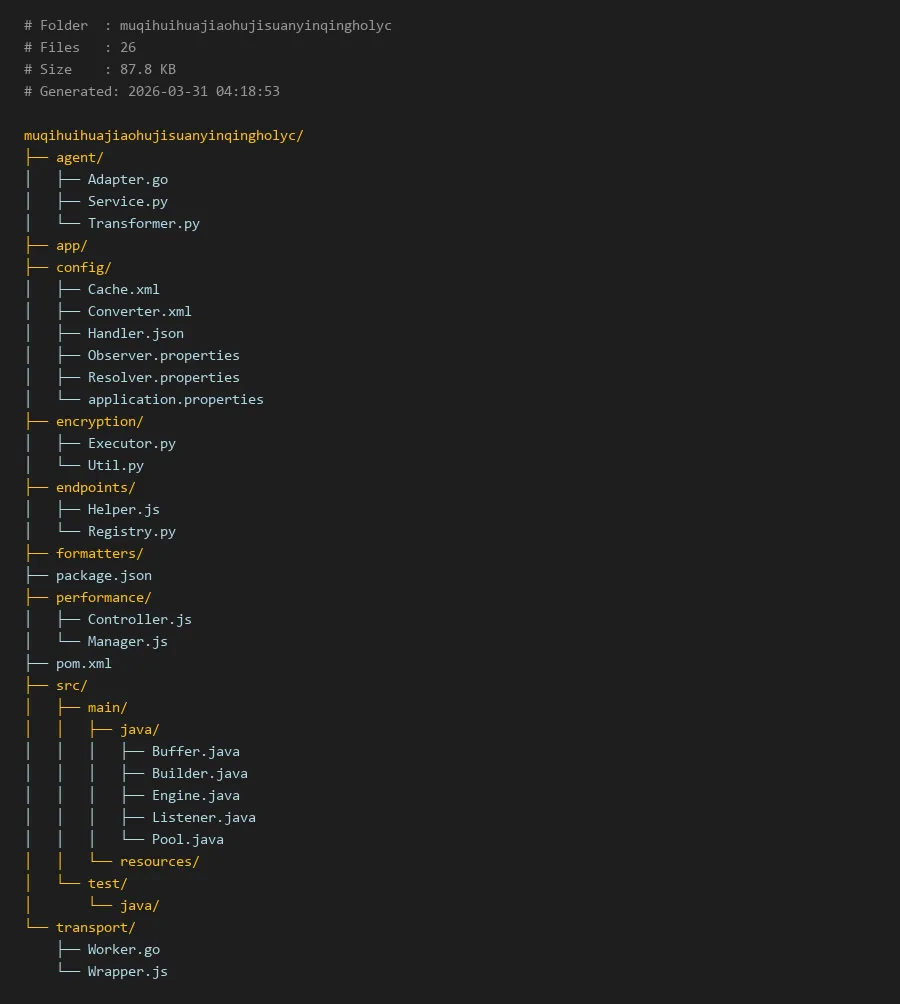
# Folder : muqihuihuajiaohujisuanyinqingholyc
# Files : 26
# Size : 87.8 KB
# Generated: 2026-03-31 04:18:53
muqihuihuajiaohujisuanyinqingholyc/
├── agent/
│ ├── Adapter.go
│ ├── Service.py
│ └── Transformer.py
├── app/
├── config/
│ ├── Cache.xml
│ ├── Converter.xml
│ ├── Handler.json
│ ├── Observer.properties
│ ├── Resolver.properties
│ └── application.properties
├── encryption/
│ ├── Executor.py
│ └── Util.py
├── endpoints/
│ ├── Helper.js
│ └── Registry.py
├── formatters/
├── package.json
├── performance/
│ ├── Controller.js
│ └── Manager.js
├── pom.xml
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Buffer.java
│ │ │ ├── Builder.java
│ │ │ ├── Engine.java
│ │ │ ├── Listener.java
│ │ │ └── Pool.java
│ │ └── resources/
│ └── test/
│ └── java/
└── transport/
├── Worker.go
└── Wrapper.js
muqihuihuajiaohujisuanyinqingholyc:构建高效对话交互引擎的技术实践
简介
muqihuihuajiaohujisuanyinqingholyc 是一个专门为现代对话系统设计的交互计算引擎,它采用模块化架构实现高效的消息处理、转换和响应生成。该引擎特别适合构建需要复杂交互逻辑的聊天模拟器应用,能够处理多种格式的输入输出,并支持实时性能监控。通过精心设计的文件结构,项目实现了关注点分离,使各个功能模块可以独立开发和测试。
核心模块说明
项目包含多个核心模块,每个模块承担特定职责:
- agent模块:负责消息的适配、转换和服务处理,是对话逻辑的核心
- config模块:集中管理所有配置信息,支持多种配置文件格式
- encryption模块:处理数据加密和安全执行任务
- endpoints模块:管理API端点和请求路由
- performance模块:监控系统性能并优化响应时间
- formatters模块:格式化输出内容,确保一致性
这种模块化设计使得引擎可以轻松集成到不同的聊天模拟器项目中,无论是简单的对话机器人还是复杂的多轮交互系统。
代码示例
以下代码示例展示了项目关键模块的实现方式,反映了实际文件结构中的编程实践。
1. Agent服务层实现
agent/Service.py 文件实现了对话服务的核心逻辑:
class DialogueService:
def __init__(self, config_path="config/application.properties"):
self.load_configuration(config_path)
self.conversation_history = []
self.response_cache = {
}
def load_configuration(self, config_path):
"""加载对话引擎配置"""
import json
with open(config_path, 'r') as config_file:
self.config = json.load(config_file)
print(f"配置加载完成: {self.config['engine.name']}")
def process_message(self, user_input, session_id):
"""处理用户输入并生成响应"""
# 检查缓存
cache_key = f"{session_id}:{user_input}"
if cache_key in self.response_cache:
return self.response_cache[cache_key]
# 预处理输入
processed_input = self.preprocess_input(user_input)
# 应用对话逻辑
response = self.apply_dialogue_logic(processed_input, session_id)
# 更新历史记录
self.update_conversation_history(session_id, user_input, response)
# 缓存结果
self.response_cache[cache_key] = response
return response
def preprocess_input(self, text):
"""预处理用户输入"""
from agent.Transformer import TextTransformer
transformer = TextTransformer()
return transformer.normalize(text)
def apply_dialogue_logic(self, text, session_id):
"""应用对话逻辑生成响应"""
# 这里可以集成各种NLP模型
if "帮助" in text:
return "我可以协助您解决各种问题,请告诉我您需要什么帮助?"
elif "时间" in text:
from datetime import datetime
return f"当前时间是:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
else:
return f"已收到您的消息:'{text}'。我正在处理中..."
def update_conversation_history(self, session_id, user_input, response):
"""更新对话历史"""
self.conversation_history.append({
'session_id': session_id,
'user_input': user_input,
'response': response,
'timestamp': datetime.now().isoformat()
})
# 限制历史记录长度
if len(self.conversation_history) > 100:
self.conversation_history = self.conversation_history[-50:]
2. 配置管理实现
config/Handler.json 文件定义了配置处理的结构:
{
"configuration_handlers": {
"properties": {
"handler_class": "PropertiesConfigHandler",
"supported_files": [".properties"],
"priority": 1
},
"json": {
"handler_class": "JsonConfigHandler",
"supported_files": [".json"],
"priority": 2
},
"xml": {
"handler_class": "XmlConfigHandler",
"supported_files": [".xml"],
"priority": 3
}
},
"defaults": {
"cache_enabled": true,
"cache_size": 1000,
"response_timeout": 5000,
"max_concurrent_sessions": 100
}
}
config/application.properties 文件包含引擎的主要配置:
# 引擎基础配置
engine.name=muqihuihuajiaohujisuanyinqingholyc
engine.version=1.0.0
engine.mode=production
# 性能配置
performance.monitoring.enabled=true
performance.metrics.interval=60
performance.alert.threshold=2000
# 对话配置
dialogue.max_history_length=20
dialogue.response.timeout=3000
dialogue.fallback.enabled=true
# 缓存配置
cache.provider=memory
cache.ttl=3600
cache.max_size=5000
3. 端点注册与管理
endpoints/Registry.py 文件实现了API端点的动态注册:
```python
class EndpointRegistry:
def init(self):
self.endpoints = {}
self.middleware_chain =

