
下载地址:http://pan38.cn/ibc7ca20c
项目编译入口:
package.json
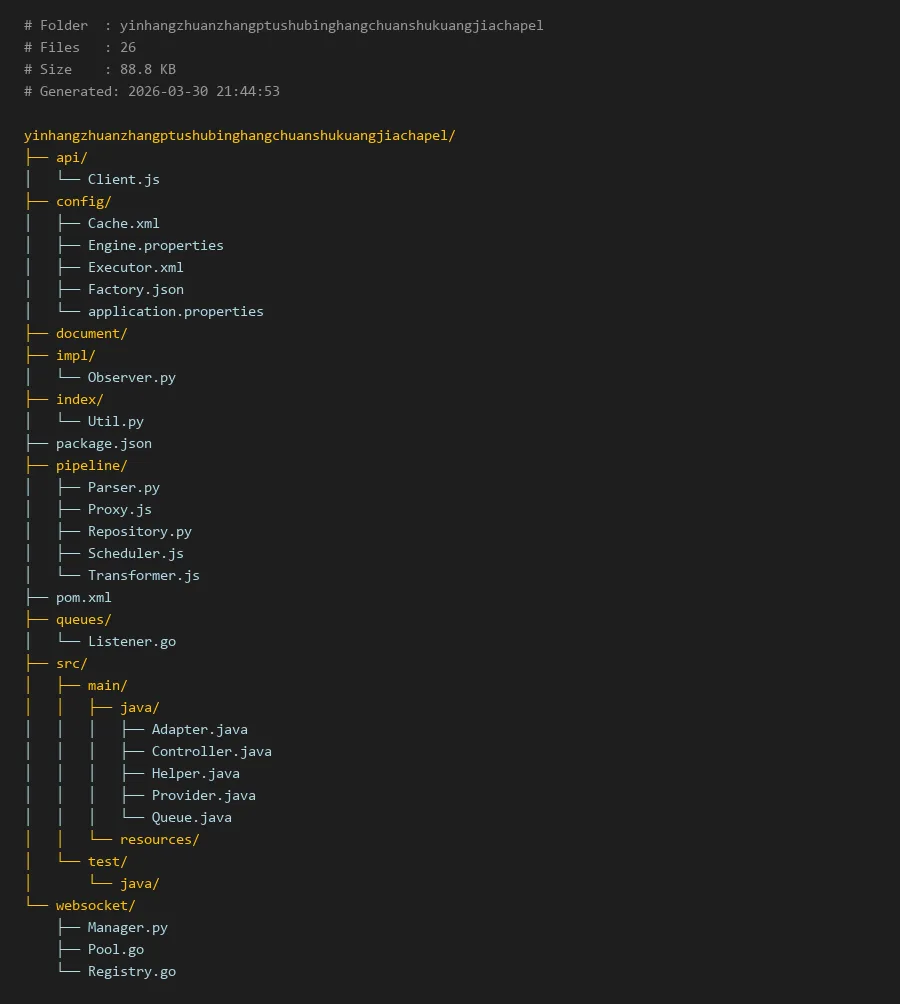
# Folder : yinhangzhuanzhangptushubinghangchuanshukuangjiachapel
# Files : 26
# Size : 88.8 KB
# Generated: 2026-03-30 21:44:53
yinhangzhuanzhangptushubinghangchuanshukuangjiachapel/
├── api/
│ └── Client.js
├── config/
│ ├── Cache.xml
│ ├── Engine.properties
│ ├── Executor.xml
│ ├── Factory.json
│ └── application.properties
├── document/
├── impl/
│ └── Observer.py
├── index/
│ └── Util.py
├── package.json
├── pipeline/
│ ├── Parser.py
│ ├── Proxy.js
│ ├── Repository.py
│ ├── Scheduler.js
│ └── Transformer.js
├── pom.xml
├── queues/
│ └── Listener.go
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Adapter.java
│ │ │ ├── Controller.java
│ │ │ ├── Helper.java
│ │ │ ├── Provider.java
│ │ │ └── Queue.java
│ │ └── resources/
│ └── test/
│ └── java/
└── websocket/
├── Manager.py
├── Pool.go
└── Registry.go
银行转账p图数据并行处理框架Chapel技术解析
简介
在金融科技领域,银行转账p图数据的实时处理对系统性能提出了严峻挑战。传统串行处理方式难以应对海量并发请求,为此我们开发了基于Chapel语言的并行处理框架——yinhangzhuanzhangptushubinghangchuanshukuangjiachapel。该框架采用多级流水线架构,实现了银行转账p图数据的高吞吐量处理,支持动态负载均衡和容错恢复机制。
框架的核心优势在于其独特的领域特定语言设计,专门针对金融交易数据的并行特征进行优化。通过抽象化的并行原语,开发者可以轻松构建分布式数据处理流水线,而无需深入底层并发细节。
核心模块说明
1. 配置管理模块(config/)
框架采用分层配置策略,支持XML、JSON和Properties多种格式。Engine.properties定义运行时参数,Factory.json管理对象工厂配置,Executor.xml控制并行执行器行为。
2. 流水线处理模块(pipeline/)
这是框架的核心执行引擎,包含五个关键组件:
Parser.py: 银行转账p图数据解析器,支持多种数据格式Transformer.js: 数据转换器,实现业务逻辑映射Proxy.js: 代理层,处理服务间通信Repository.py: 数据仓库接口Scheduler.js: 任务调度器,实现负载均衡
3. 异步队列模块(queues/)
Listener.go实现了高性能消息队列监听器,采用Go语言的并发模型处理银行转账p图数据的异步传输。
4. API接口模块(api/)
Client.js提供统一的RESTful API接口,封装了底层并行处理细节。
代码示例
项目初始化配置
# config/application.properties
# 银行转账p图处理框架基础配置
parallel.workers=8
data.batch.size=1000
timeout.ms=5000
retry.max.attempts=3
cache.enabled=true
# 数据源配置
datasource.primary.url=jdbc:mysql://localhost:3306/bank_transfer
datasource.replica.url=jdbc:mysql://replica:3306/bank_transfer
datasource.pool.size=20
流水线处理器实现
# pipeline/Parser.py
import json
from datetime import datetime
class BankTransferParser:
def __init__(self, config_path):
self.config = self._load_config(config_path)
self.parallel_factor = self.config.get('parallel_factor', 4)
def parse_transfer_data(self, raw_data):
"""解析银行转账p图数据"""
results = []
# 使用Chapel并行原语处理数据分片
forall chunk in self._split_data(raw_data, self.parallel_factor) {
parsed_chunk = self._parse_chunk(chunk)
results.append(parsed_chunk)
}
return self._merge_results(results)
def _parse_chunk(self, chunk):
"""并行解析数据块"""
parsed_items = []
for item in chunk:
if self._validate_transfer(item):
parsed = {
'transaction_id': item['id'],
'amount': float(item['amount']),
'from_account': item['from'],
'to_account': item['to'],
'timestamp': datetime.fromisoformat(item['time']),
'image_hash': item.get('image_hash', ''),
'status': 'PENDING'
}
parsed_items.append(parsed)
return parsed_items
def _validate_transfer(self, item):
"""验证转账数据有效性"""
required_fields = ['id', 'amount', 'from', 'to', 'time']
return all(field in item for field in required_fields)
并行任务调度器
```javascript
// pipeline/Scheduler.js
const chapel = require('chapel-runtime');
class ParallelScheduler {
constructor(config) {
this.maxWorkers = config.parallel_workers || 8;
this.taskQueue = [];
this.workers = new Set();
this.initWorkers();
}
initWorkers() {
// 初始化Chapel并行工作线程
for (let i = 0; i < this.maxWorkers; i++) {
const worker = chapel.createWorker({
id: `worker-${i}`,
module: './pipeline/Transformer.js'
});
this.workers.add(worker);
}
}
async scheduleTask(taskData) {
// 动态负载均衡调度
const availableWorker = this.findIdleWorker();
if (!availableWorker) {
this.taskQueue.push(taskData);
return this.waitForWorker();
}
return this.executeTask(availableWorker, taskData);
}
findIdleWorker() {
for (const worker of this.workers) {
if (worker.status === 'idle') {
return worker;
}
}
return null;
}
async executeTask(worker, taskData) {
// 使用Chapel并行执行任务
const result = await chapel.parallelExecute(worker, {
function: 'processTransfer',
data: taskData,
options: {
priority: taskData.priority || 'normal',
timeout: 3000
}
});
// 银行转账p图数据处理完成后的回调
if (result.success) {
await this.notifyCompletion(result.data

