多表关系与多表查询
本文从 底层原理、关系设计、核心语法、进阶能力、性能优化、避坑指南、实战闭环 7个维度,构建 多表关系与多表查询 的完整知识体系,覆盖从入门到企业级实战的全场景内容,适配 MySQL、PostgreSQL 等主流关系型数据库。
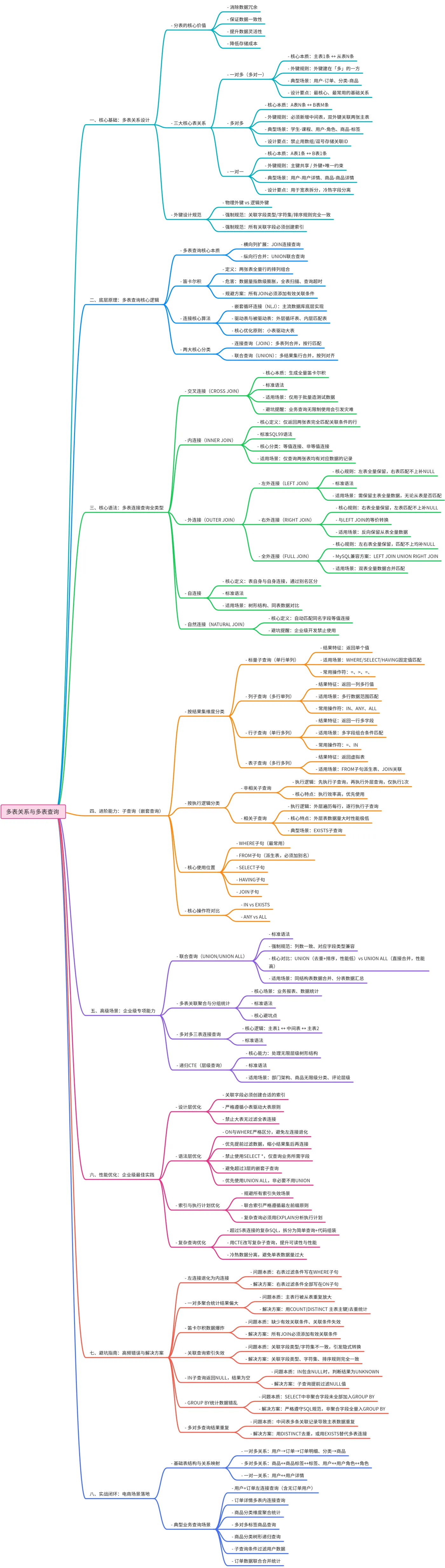
一、多表关系的本质与设计规范
多表查询的前提是合理的多表关系设计,其核心目标是通过分表消除数据冗余、避免更新/插入/删除异常,核心理论依据是关系型数据库的三大范式(核心为第三范式3NF)。
1.1 分表的核心价值
- 消除数据冗余:避免同一份数据在多处重复存储
- 保证数据一致性:减少更新异常,一处修改全表生效
- 提升数据灵活性:支持细粒度的权限控制、索引优化与业务扩展
- 降低存储成本:避免无效字段的空值占用
1.2 三大核心多表关系(一对多/多对多/一对一)
关系的本质是两张表通过主键与外键的关联,实现数据的参照完整性,企业级场景中99%的业务均可通过以下三类关系实现。
| 关系类型 | 核心本质 | 外键设计规则 | 典型业务场景 | 设计要点 |
|---|---|---|---|---|
| 一对多(多对一) | 主表一条记录对应从表多条记录,从表一条记录仅对应主表一条记录 | 外键必须建在「多」的一方,关联主表的主键 | 用户-订单、分类-商品、部门-员工、订单-订单明细 | 最常用、最核心的关系类型,是多表设计的基础 |
| 多对多 | A表一条记录对应B表多条记录,B表一条记录也对应A表多条记录 | 必须新增一张中间表(关联表),中间表包含两个外键,分别关联两张主表的主键,两个外键可组成联合主键 | 学生-课程、用户-角色、商品-标签、角色-权限 | 禁止直接在主表中用数组/逗号分隔存储关联ID,会彻底丧失查询性能与数据规范性 |
| 一对一 | A表一条记录仅对应B表一条记录,B表一条记录仅对应A表一条记录 | 两种方案: 1. 主键共享:从表主键=主表主键,同时作为外键 2. 外键唯一:从表新增外键字段,添加UNIQUE唯一约束,关联主表主键 |
用户-用户详情、商品-商品详情、账户-账户实名认证 | 用于拆分宽表,将高频访问字段与低频大字段分离,提升单表查询性能 |
1.3 外键的实战设计规范
- 物理外键 vs 逻辑外键:
- 物理外键:通过数据库
FOREIGN KEY约束强制保证参照完整性,适合单体系统、强一致性场景;缺点是分布式场景扩展性差、批量数据导入性能低、有锁竞争风险 - 逻辑外键:企业级互联网场景主流方案,仅在代码层面保证关联关系,不创建数据库外键约束,兼顾灵活性与性能,通过业务逻辑保证数据一致性
- 物理外键:通过数据库
- 强制规范:关联字段的数据类型、字符集、排序规则必须完全一致,避免隐式转换导致索引失效;所有关联字段必须创建索引。
二、多表查询的底层原理
多表查询的本质是对多张表的数据集进行「横向列扩展」或「纵向行合并」,通过关联条件过滤无效数据,最终返回符合业务需求的结果集。
2.1 核心底层概念:笛卡尔积
- 定义:两张表的所有行进行全量排列组合,若A表有m行,B表有n行,全笛卡尔积结果为
m * n行 - 无效笛卡尔积的危害:数据量指数级膨胀,导致全表扫描、数据库内存溢出、查询超时
- 避免方案:所有多表连接必须添加有效的关联条件,通过关联条件过滤掉无业务意义的组合行
2.2 多表查询的两大核心分类
| 分类 | 核心本质 | 典型语法 | 业务场景 |
|---|---|---|---|
| 连接查询(JOIN) | 横向扩展:将多张表的列合并到同一个结果集中,通过关联条件匹配行 | INNER JOIN、LEFT JOIN、RIGHT JOIN等 | 需要同时展示多张表的字段,如查询订单+用户姓名+商品信息 |
| 联合查询(UNION) | 纵向扩展:将多个查询的结果集按行合并,要求列数、字段类型完全一致 | UNION、UNION ALL | 合并多个同结构表的数据,如上半年订单+下半年订单、正常用户+注销用户数据合并 |
2.3 数据库连接核心算法(驱动表原理)
主流关系型数据库的连接查询均基于嵌套循环连接(Nested Loop Join, NLJ) 实现,是性能优化的核心底层逻辑:
- 分为驱动表(外层循环表) 和被驱动表(内层循环表)
- 执行逻辑:遍历驱动表的每一行,根据关联条件到被驱动表中匹配符合条件的行,合并后返回结果
- 核心优化原则:小表驱动大表,即数据量小的表作为驱动表,减少外层循环次数,大幅提升查询性能
- 左连接(LEFT JOIN):左表默认为驱动表
- 内连接(INNER JOIN):数据库优化器会自动选择小表作为驱动表
三、多表连接查询全类型详解
主流标准为SQL99语法(JOIN...ON结构),可读性强、业务逻辑与过滤条件解耦,是企业级开发的唯一推荐规范;SQL92语法(逗号分隔表+WHERE写关联条件)已逐步淘汰。
3.1 交叉连接(CROSS JOIN)
- 语法:
SELECT 字段 FROM 表1 CROSS JOIN 表2; - 本质:生成两张表的全笛卡尔积,无关联条件
- 适用场景:仅用于生成测试数据、批量造数,禁止在业务查询中无限制使用
- 注意:SQL92中
SELECT * FROM 表1,表2;等价于交叉连接,无WHERE条件时会生成全笛卡尔积,是初学者高频踩坑点
3.2 内连接(INNER JOIN)
- 核心定义:仅返回两张表中完全匹配关联条件的行,不匹配的行全部舍弃
- 基础语法:
SELECT 表1.字段, 表2.字段 FROM 表1 INNER JOIN 表2 ON 表1.关联字段 = 表2.关联字段 -- 核心关联条件 WHERE 过滤条件; -- 结果集过滤 - 核心分类:
- 等值连接:关联条件为等值判断(=),99%的内连接场景使用,如
user.id = order.user_id - 非等值连接:关联条件为非等值判断(>、<、BETWEEN等),典型场景如薪资等级匹配、数据区间匹配
- 等值连接:关联条件为等值判断(=),99%的内连接场景使用,如
- 关键特性:INNER可省略,直接写JOIN默认是内连接;多表内连接可连续叠加JOIN...ON
- 适用场景:仅需要查询两张表都有对应数据的记录,如查询已下单的用户及其订单信息
3.3 外连接(OUTER JOIN)
- 核心定义:保留某一张表的全部数据,另一张表按关联条件匹配,匹配不上的字段补NULL,解决内连接会舍弃不匹配数据的问题
- OUTER关键字可省略,直接写LEFT/RIGHT JOIN即可
3.3.1 左外连接(LEFT JOIN)
- 核心规则:左表(FROM后的表)的所有行全部保留,右表按关联条件匹配,匹配不上的右表字段补NULL
- 基础语法:
SELECT 表1.字段, 表2.字段 FROM 表1 -- 左表,驱动表,全量保留 LEFT JOIN 表2 ON 表1.关联字段 = 表2.关联字段 -- 关联条件+右表前置过滤 WHERE 结果集过滤; - 适用场景:需要保留主表全部数据,无论从表是否有匹配记录,如查询所有用户及其订单数量(包括无订单的用户)
3.3.2 右外连接(RIGHT JOIN)
- 核心规则:右表(JOIN后的表)的所有行全部保留,左表按关联条件匹配,匹配不上的左表字段补NULL
- 特性:所有RIGHT JOIN均可改写为LEFT JOIN(调换表顺序即可),企业级开发优先使用LEFT JOIN,提升SQL可读性
- 适用场景:反向保留从表数据,如查询所有订单及其对应的用户信息(包括无归属用户的异常订单)
3.3.3 全外连接(FULL JOIN)
- 核心规则:保留左右两张表的全部行,两边匹配不上的字段均补NULL
- 注意:MySQL不支持FULL JOIN,可通过
LEFT JOIN UNION RIGHT JOIN实现等价效果 - 适用场景:需要合并两张表的全量数据,如统计两个渠道的全量用户数据,匹配关联信息
3.4 自连接
- 核心定义:一张表自己和自己进行连接,将同一张表虚拟为两张表,通过别名区分
- 核心场景:处理树形结构数据(部门上下级、商品分类层级、评论回复层级)、同表内数据对比
- 基础语法(示例:查询员工及其上级领导姓名):
SELECT e.emp_name AS 员工姓名, m.emp_name AS 领导姓名 FROM emp e -- 员工表别名e LEFT JOIN emp m -- 同一张表别名m,作为领导表 ON e.manager_id = m.emp_id; -- 关联条件:员工的上级ID=领导的员工ID
3.5 自然连接(NATURAL JOIN)
- 核心定义:自动匹配两张表中同名字段进行等值连接,无需手动写ON关联条件
- 分类:NATURAL INNER JOIN(自然内连接)、NATURAL LEFT JOIN(自然左外连接)
- 避坑提醒:企业级开发禁止使用,若同名字段语义不同(如两张表都有create_time、update_time),会导致关联条件错误,查询结果完全不符合预期
四、子查询(嵌套查询)
子查询指嵌套在其他SQL语句中的SELECT查询,又称嵌套查询,是多表查询的核心补充能力,适用于复杂条件过滤、多步骤数据处理场景。
4.1 子查询的四大分类(按结果集维度)
| 子查询类型 | 结果集特征 | 适用场景 | 常用操作符 |
|---|---|---|---|
| 标量子查询 | 单行单列,返回单个值 | WHERE/SELECT/HAVING子句中的固定值匹配 | =、>、<、>=、<= |
| 列子查询 | 多行单列,返回一列值 | 多行数据的范围匹配 | IN、ANY、ALL |
| 行子查询 | 单行多列,返回一行多字段 | 多字段组合条件匹配 | =、IN |
| 表子查询 | 多行多列,返回一个虚拟表 | FROM子句作为派生表、JOIN子句关联 | 无特殊限制 |
4.2 按执行逻辑分类:非相关子查询 vs 相关子查询
4.2.1 非相关子查询
- 执行逻辑:子查询独立于外层查询,先执行子查询,再执行外层查询,子查询仅执行1次
- 特点:执行效率高,无循环依赖,优先使用
- 示例:查询薪资高于公司平均薪资的员工
SELECT * FROM emp WHERE salary > (SELECT AVG(salary) FROM emp); -- 标量子查询,先执行
4.2.2 相关子查询
- 执行逻辑:子查询依赖外层查询的字段,先遍历外层查询的每一行,再针对每一行执行一次子查询
- 特点:外层表数据量大时,子查询会执行多次,性能极低,非必要不滥用
- 典型场景:EXISTS子查询
SELECT * FROM user u WHERE EXISTS ( SELECT 1 FROM `order` o WHERE o.user_id = u.id AND o.status = 1 ); -- 子查询依赖外层u.id,外层每一行执行一次子查询
4.3 子查询的核心使用位置
- WHERE子句:最常用场景,用于条件过滤,支持标量、列、行子查询
- FROM子句:表子查询,结果集作为派生表(必须加别名),适用于复杂数据预处理
- SELECT子句:标量子查询,用于字段扩展,类似左连接效果,非必要不使用(外层每一行执行一次,性能差)
- HAVING子句:标量子查询,用于分组后的结果过滤
- JOIN子句:表子查询,与派生表进行连接查询
4.4 核心操作符与关键对比
- IN vs EXISTS:
- IN:先执行子查询,获取结果集后再执行外层查询,适合子查询结果集小、外层表大的场景
- EXISTS:判断子查询是否有返回结果,有则返回true,适合外层表小、子查询结果集大的场景
- 注意:IN子查询若返回NULL,整个查询结果为空,需提前过滤NULL值
- ANY vs ALL:
- ANY:与子查询返回的任意一个值匹配即可,如
> ANY(子查询)表示大于子查询结果的最小值 - ALL:与子查询返回的所有值匹配才成立,如
> ALL(子查询)表示大于子查询结果的最大值
- ANY:与子查询返回的任意一个值匹配即可,如
五、企业级多表查询专项能力
5.1 联合查询(UNION/UNION ALL)
- 核心语法:
SELECT 字段1,字段2 FROM 表1 WHERE 条件 UNION [ALL] SELECT 字段1,字段2 FROM 表2 WHERE 条件; - 强制规范:多个查询的字段数量必须完全一致、对应字段的数据类型必须兼容,字段名以第一个查询为准
- UNION vs UNION ALL 核心区别:
- UNION:对合并后的结果集进行去重+排序,性能极低,仅在需要去重时使用
- UNION ALL:直接合并结果集,不去重、不排序,性能提升10倍以上,企业级开发优先使用(确定无重复数据时)
- 适用场景:纵向合并多个同结构表的数据、分表数据合并、不同业务维度的同类型数据汇总
5.2 多表关联聚合与分组统计
- 核心场景:多表连接后进行数据统计,是业务报表的核心能力
- 基础语法示例:统计每个用户的订单数量、订单总金额
SELECT u.id, u.user_name, COUNT(o.id) AS order_count, -- 订单数量 IFNULL(SUM(o.total_amount),0) AS total_amount -- 总金额,无订单补0 FROM user u LEFT JOIN `order` o ON u.id = o.user_id GROUP BY u.id, u.user_name; -- 分组字段必须包含SELECT中非聚合的所有字段 - 核心避坑点:
- 一对多连接后,主表数据会被从表重复放大,导致COUNT/SUM结果偏大,需使用
COUNT(DISTINCT 主表主键)去重统计 - 左连接后聚合函数会忽略NULL值,需用IFNULL函数将NULL转为0,避免统计结果缺失
- 严格遵守
GROUP BY规范:SELECT中出现的非聚合字段,必须全部出现在GROUP BY子句中,避免非严格模式下的数据错乱
- 一对多连接后,主表数据会被从表重复放大,导致COUNT/SUM结果偏大,需使用
5.3 多对多关系的三表连接查询
- 核心逻辑:主表1 ↔ 中间表 ↔ 主表2,通过两次连接实现多对多数据查询
- 示例:查询拥有「超级管理员」角色的所有用户(用户-角色多对多,中间表user_role)
SELECT DISTINCT u.* FROM user u INNER JOIN user_role ur ON u.id = ur.user_id INNER JOIN role r ON ur.role_id = r.id WHERE r.role_name = '超级管理员';
5.4 递归CTE(层级查询)
- 核心能力:通过
WITH RECURSIVE实现树形/层级结构的递归查询,解决自连接无法处理无限层级的痛点(MySQL8.0+、PostgreSQL等均支持) - 适用场景:部门树形结构、商品无限级分类、评论回复层级、组织架构查询
- 基础语法示例:查询部门全层级树形结构
WITH RECURSIVE dept_tree AS ( -- 锚点成员:查询顶级部门 SELECT id, dept_name, parent_id, 1 AS level FROM dept WHERE parent_id IS NULL UNION ALL -- 递归成员:关联自身,查询子部门 SELECT d.id, d.dept_name, d.parent_id, dt.level + 1 AS level FROM dept d INNER JOIN dept_tree dt ON d.parent_id = dt.id ) SELECT * FROM dept_tree;
六、多表查询企业级最佳实践
6.1 核心设计优化
- 关联字段必须创建索引:主键、外键、关联条件字段、过滤条件字段必须建立合适的索引,优先使用联合索引
- 小表驱动大表:严格遵循嵌套循环连接的优化原则,左连接优先选择小表作为左表,内连接无需手动指定,优化器会自动选择
- 避免大表全表连接:禁止对千万级大表直接进行无过滤的全表连接,必须提前通过WHERE条件缩小数据范围
6.2 语法规范优化
- ON与WHERE的严格区分:
- 关联条件、右表的前置过滤条件,必须写在ON子句中
- 最终结果集的全局过滤条件,写在WHERE子句中
- 致命坑:左连接的右表过滤条件写在WHERE中,会导致左连接退化为内连接
- 提前过滤数据:优先在子查询/ON子句中过滤掉无效数据,缩小结果集后再进行连接,而非先全表连接再过滤
- 禁止使用SELECT *:只查询业务需要的字段,减少数据传输与内存占用,避免覆盖索引失效
- 避免多层嵌套子查询:超过3层的嵌套子查询可读性极差,优化器无法优化,优先使用JOIN或CTE改写
- 优先使用UNION ALL替代UNION:仅在必须去重时使用UNION,其余场景全量使用UNION ALL
6.3 索引与执行计划优化
- 避免索引失效场景:关联字段隐式类型转换、模糊查询前缀%、索引字段使用函数、OR连接非索引字段等
- 联合索引遵循最左前缀原则:过滤频率高的字段放在联合索引左侧
- 强制查看执行计划:复杂多表查询必须使用
EXPLAIN查看执行计划,重点关注type、key、rows、Extra字段,避免出现ALL(全表扫描)、Using filesort、Using temporary
6.4 复杂查询优化
- 拆分复杂SQL:将超过5张表连接的复杂SQL,拆分为多个简单查询,通过业务代码组装结果,避免数据库优化器选错执行计划
- 使用CTE提升可读性与性能:MySQL8.0+对CTE有优化,复杂子查询优先使用CTE改写,避免重复执行子查询
- 冷热数据分离:大表查询优先查询热数据,历史冷数据归档到单独的表,避免单表数据量过大导致连接性能下降
七、避坑指南:高频错误与解决方案
| 错误场景 | 问题本质 | 解决方案 |
|---|---|---|
| 左连接右表过滤条件写在WHERE中,结果缺失 | WHERE过滤会剔除右表为NULL的行,左连接退化为内连接 | 右表过滤条件全部写在ON子句中 |
| 一对多连接后COUNT统计结果偏大 | 主表行被从表重复放大,COUNT统计了重复行 | 使用COUNT(DISTINCT 主表主键)去重统计 |
| 多表查询出现笛卡尔积,数据量爆炸 | 缺少关联条件、关联条件失效 | 所有JOIN必须添加有效的关联条件,禁止无ON子句的JOIN |
| 关联查询索引失效,查询超时 | 关联字段类型/字符集不一致,导致隐式转换 | 关联字段的类型、字符集、排序规则必须完全一致 |
| IN子查询返回NULL,结果为空 | IN (..., NULL) 会导致整个判断结果为UNKNOWN,无匹配行 | 子查询中提前过滤NULL值,使用WHERE 字段 IS NOT NULL |
| GROUP BY统计数据错乱 | 非严格模式下,SELECT中非聚合字段未全部加入GROUP BY | 严格遵守SQL规范,SELECT中非聚合字段必须全部出现在GROUP BY中 |
| 多对多查询结果重复 | 中间表多条关联记录导致主表数据重复 | 使用DISTINCT去重,或使用EXISTS子查询替代多表连接 |
八、电商系统全场景多表查询案例
8.1 基础表结构(覆盖全关系类型)
- 一对多:user(用户表) → order(订单表) → order_item(订单明细表);category(分类表) → product(商品表)
- 多对多:product(商品表) ↔ product_tag(中间表) ↔ tag(标签表)
- 一对一:user(用户表) ↔ user_info(用户详情表)
8.2 典型业务查询示例
- 查询所有用户及其最近的订单信息,包括无订单的用户(左连接)
- 查询订单详情,包含用户姓名、商品名称、商品分类(多表内连接)
- 统计每个商品分类的销量、销售额,包括无销量的分类(左连接+聚合)
- 查询带有「新品」标签的所有上架商品(多对多三表连接)
- 查询商品分类的全层级树形结构(递归CTE)
- 查询下单金额超过全平台平均水平的用户(标量子查询)
- 合并正常订单与已取消订单的统计数据(UNION ALL)
总结
多表关系与多表查询的核心逻辑可概括为:
- 先设计,后查询:合理的表关系设计是高效查询的前提,优先遵循三大范式,正确划分一对多、多对多、一对一关系
- 先原理,后语法:理解笛卡尔积、嵌套循环连接、驱动表的底层原理,才能写出高性能的查询语句
- 先业务,后技巧:根据业务需求选择合适的连接类型,能左连接不用内连接?不,是能精准匹配就不用全量保留,能简单查询就不用复杂嵌套
- 先过滤,后连接:永远优先缩小数据范围,再进行多表关联,这是多表查询性能优化的第一性原理
附:思维导图