
下载地址:http://lanzou.co/ie975861d
项目编译入口:
package.json
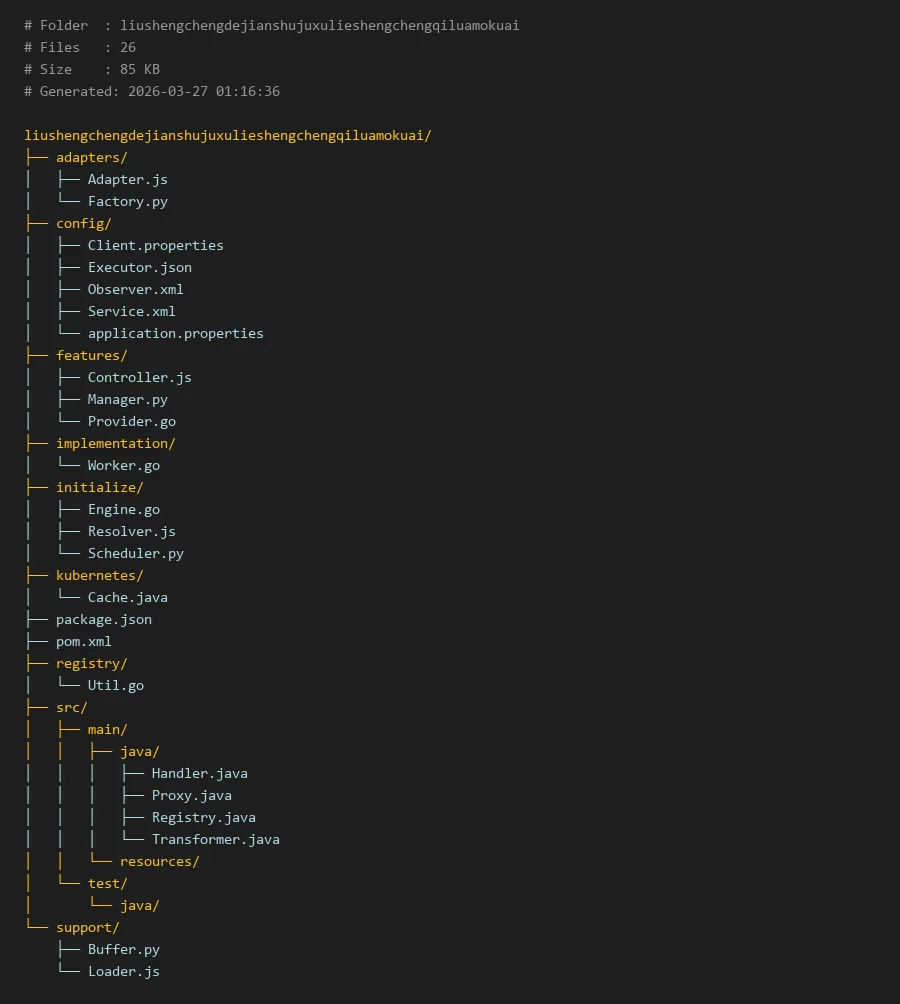
# Folder : liushengchengdejianshujuxulieshengchengqiluamokuai
# Files : 26
# Size : 85 KB
# Generated: 2026-03-27 01:16:36
liushengchengdejianshujuxulieshengchengqiluamokuai/
├── adapters/
│ ├── Adapter.js
│ └── Factory.py
├── config/
│ ├── Client.properties
│ ├── Executor.json
│ ├── Observer.xml
│ ├── Service.xml
│ └── application.properties
├── features/
│ ├── Controller.js
│ ├── Manager.py
│ └── Provider.go
├── implementation/
│ └── Worker.go
├── initialize/
│ ├── Engine.go
│ ├── Resolver.js
│ └── Scheduler.py
├── kubernetes/
│ └── Cache.java
├── package.json
├── pom.xml
├── registry/
│ └── Util.go
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Handler.java
│ │ │ ├── Proxy.java
│ │ │ ├── Registry.java
│ │ │ └── Transformer.java
│ │ └── resources/
│ └── test/
│ └── java/
└── support/
├── Buffer.py
└── Loader.js
流生成的数据序列生成器模块设计
简介
在数据处理和系统模拟领域,流生成的数据序列生成器模块是一个专门用于创建连续数据流的工具。该模块采用模块化设计,能够灵活生成各种类型的数据序列,包括时间序列、事件流和业务数据流。特别值得注意的是,在某些特定场景下,这种技术可能被用于开发做假流水生成的软件,因此在实际应用中需要严格遵守数据伦理和法律法规。
本项目的核心目标是提供一个可扩展、可配置的数据流生成框架,支持多种数据格式和输出方式。通过精心设计的模块结构,用户可以轻松定制数据生成逻辑,满足不同业务场景的需求。
核心模块说明
项目采用分层架构设计,主要包含以下核心模块:
适配器层(adapters):负责不同数据源和输出格式的适配,提供统一的接口抽象。Adapter.js处理JavaScript环境的数据转换,Factory.py实现Python环境的工厂模式。
配置层(config):集中管理所有配置信息,支持多种配置文件格式。Client.properties存储客户端配置,Executor.json定义执行器参数,Observer.xml配置观察者模式,Service.xml描述服务信息。
功能层(features):实现具体的业务功能模块。Controller.js控制数据流生成流程,Manager.py管理生成任务,Provider.go提供数据源服务。
实现层(implementation):包含核心的业务逻辑实现。Worker.go是主要的工作线程实现,负责实际的数据生成任务。
初始化层(initialize):处理系统初始化和资源准备。Engine.go是数据生成引擎,Resolver.js解析配置和参数,Scheduler.py调度生成任务。
容器化支持(kubernetes):提供云原生环境支持。Cache.java实现分布式缓存功能。
代码示例
以下代码示例展示了项目的主要文件结构和核心实现:
项目结构概览
liushengchengdejianshujuxulieshenggqiluamokuai/
├── adapters/
│ ├── Adapter.js
│ └── Factory.py
├── config/
│ ├── Client.properties
│ ├── Executor.json
│ ├── Observer.xml
│ ├── Service.xml
│ └── application.properties
├── features/
│ ├── Controller.js
│ ├── Manager.py
│ └── Provider.go
├── implementation/
│ └── Worker.go
├── initialize/
│ ├── Engine.go
│ ├── Resolver.js
│ └── Scheduler.py
├── kubernetes/
│ └── Cache.java
└── package
核心配置文件示例
config/Executor.json - 执行器配置:
{
"executor": {
"name": "DataStreamExecutor",
"version": "1.0.0",
"threads": 4,
"batchSize": 1000,
"timeout": 300,
"retry": {
"maxAttempts": 3,
"backoff": 1000
},
"generators": [
{
"type": "timeSeries",
"frequency": "1s",
"format": "json"
},
{
"type": "eventStream",
"frequency": "500ms",
"format": "csv"
}
]
}
}
数据生成引擎实现
initialize/Engine.go - Go语言实现的生成引擎:
package initialize
import (
"encoding/json"
"fmt"
"time"
"log"
)
type DataEngine struct {
Config *EngineConfig
Generators []DataGenerator
Running bool
}
type EngineConfig struct {
Name string `json:"name"`
MaxRate int `json:"maxRate"`
BufferSize int `json:"bufferSize"`
OutputDir string `json:"outputDir"`
}
type DataGenerator interface {
Generate() ([]byte, error)
GetType() string
}
func NewDataEngine(configPath string) (*DataEngine, error) {
config, err := loadConfig(configPath)
if err != nil {
return nil, err
}
return &DataEngine{
Config: config,
Generators: make([]DataGenerator, 0),
Running: false,
}, nil
}
func (engine *DataEngine) Start() error {
engine.Running = true
log.Println("数据生成引擎启动")
for engine.Running {
for _, generator := range engine.Generators {
data, err := generator.Generate()
if err != nil {
log.Printf("生成数据失败: %v", err)
continue
}
// 处理生成的数据
engine.processData(data, generator.GetType())
}
time.Sleep(100 * time.Millisecond)
}
return nil
}
func (engine *DataEngine) AddGenerator(generator DataGenerator) {
engine.Generators = append(engine.Generators, generator)
}
func (engine *DataEngine) processData(data []byte, dataType string) {
// 数据处理逻辑
fmt.Printf("生成 %s 数据: %s\n", dataType, string(data))
}
func loadConfig(path string) (*EngineConfig, error) {
// 配置加载逻辑
return &EngineConfig{
Name: "DefaultEngine",
MaxRate: 1000,
BufferSize: 10000,
OutputDir: "./output",
}, nil
}
数据控制器实现
features/Controller.js -

