
三个百万token窗口语义学分析之二:“撒网法”
——客观语义挖掘与主观预设的互补方法论
摘要
本研究为百万token窗口语义学分析系列的第二篇。在“垂钓法”(主观预设关键词)的基础上,采用“撒网法”——即全量词频统计、TF-IDF特征提取、LDA主题建模、层次聚类等无监督学习方法,对三个窗口的语义特征进行系统性识别。研究发现:(1)三个窗口在语义空间上完全分离,分别对应“技术基建期”“实验探索期”“框架构建期”,验证了垂钓法的窗口划分;(2)垂钓法预设的核心概念(元认知、框架、涌现、谬误分析、贝叶斯)均在窗口三显著激增,主观预设得到客观验证;(3)撒网法发现了“minimind”“memsearch”“支柱”等未预设的新词,揭示了主观预设之外的意外模式;(4)垂钓法与撒网法形成“主观预设—客观验证—新发现”的认知闭环,共同构成百万token窗口语义分析的完整方法论。本研究揭示了人机协同研究中客观数据与主观理解的辩证关系。
关键词:百万token窗口;撒网法;无监督学习;客观语义挖掘;主观预设验证
导言
1.1 从“垂钓”到“撒网”:方法论的内在逻辑
在系列第一篇“垂钓法”中,我们采用主观预设关键词的方法,基于项目内容构建七大类词汇,统计三个窗口的词频分布。这一方法的优势在于理论驱动、目标明确,能够快速捕捉研究者关心的核心概念。正如文中所述:“垂钓法”以“预设关键词集”为饵,从海量对话文本中“钓取”研究者关注的概念。
然而,任何主观预设方法都面临两个根本局限:其一,可能遗漏未知模式——研究者关心的概念未必是数据中最重要的概念;其二,依赖研究者的主观判断——不同研究者可能预设不同的关键词,导致结果差异。在方法论上,这是“理论驱动”研究固有的张力:理论聚焦带来深度,但也可能遮蔽视野。
“撒网法”正是对“垂钓法”局限性的回应。如果说“垂钓”是有目标地捕捉特定概念,“撒网”则是将整个语义空间一网打尽,让数据自己说话。这一方法不预设任何关键词,而是通过全量词频统计、特征提取、主题建模、聚类分析等无监督学习技术,客观地呈现数据的语义结构。
两种方法构成了人机协同研究中的一对基本张力:主观预设与客观发现。本文的核心命题是:这两种方法不是替代关系,而是互补关系。客观撒网为主观垂钓提供验证与扩展,主观垂钓为客观发现注入意义与解释。
1.2 研究问题
基于上述方法论定位,本文提出四个研究问题:
- 客观特征:三个窗口在语义空间上的分布特征是什么?(撒网法的回答)
- 主观验证:垂钓法预设的核心概念是否在客观数据中得到验证?(垂钓法与撒网法的对话)
- 意外发现:撒网法能发现哪些“垂钓法”遗漏的客观模式?(新发现)
- 方法论整合:主观预设与客观发现如何形成认知闭环?(方法论讨论)
1.3 论文结构
本文首先介绍数据来源与分析方法,强调无监督学习的客观性;然后呈现三部分结果——客观发现、主观验证、意外新发现;在此基础上讨论垂钓法与撒网法的互补关系,揭示人机协同认知的闭环机制;最后总结方法论的整合意义。
一、数据与方法
1.1 数据来源
本研究的数据来自三个百万token窗口的完整人机对话记录:
三个窗口的内容构成具有连续性:窗口一为项目起始阶段,涉及环境工具配置与数据库构建;窗口二穿插了窗口特性实验研究;窗口三以项目框架构建与完善为主。
1.2 数据预处理
为保障分析质量,所有 .jsonl 文件经过以下预处理流程:
- 提取content字段:保留用户与AI的对话内容,去除元数据
- 文本清洗:保留中文字符、英文字母及空白符,过滤代码符号、路径、数字、标点
- 分词:使用 jieba 分词,加载自定义词典(基于垂钓法七大类关键词)
- 停用词过滤:使用合并后的通用停用词表,过滤高频无意义词
- 最低词频阈值:过滤出现次数 < 3 的词
1.3 分析方法
本研究采用三种无监督学习方法,从不同维度揭示数据的语义结构:
这三种方法共同构成“撒网法”的技术内核:
这三种方法共同构成“撒网法”的技术内核:
• TF-IDF 回答:每个窗口的“指纹”是什么?
• LDA 回答:每个窗口的“主题”是什么?
• 层次聚类 回答:窗口之间“有多相似”?
1.4 与垂钓法的对比定位
为便于后续讨论,本节明确两种方法的方法论差异:
两种方法的方法论定位决定了它们不是替代关系,而是互补关系——这正是本文论证的核心。
二、结果
2.1 客观发现一:三窗口的语义指纹(TF-IDF)
TF-IDF(词频-逆文档频率)是一种客观的特征提取方法:它不依赖任何预设,而是根据词在文档内外的分布自动计算每个词对文档的“重要性”。通过这种方法,我们提取了每个窗口的 Top 20 特征词,作为窗口的“语义指纹”。
[表1:三个窗口的 Top 20 特征词]
[图1:三窗口特征词词云对比](各窗口的词云图见附录 B)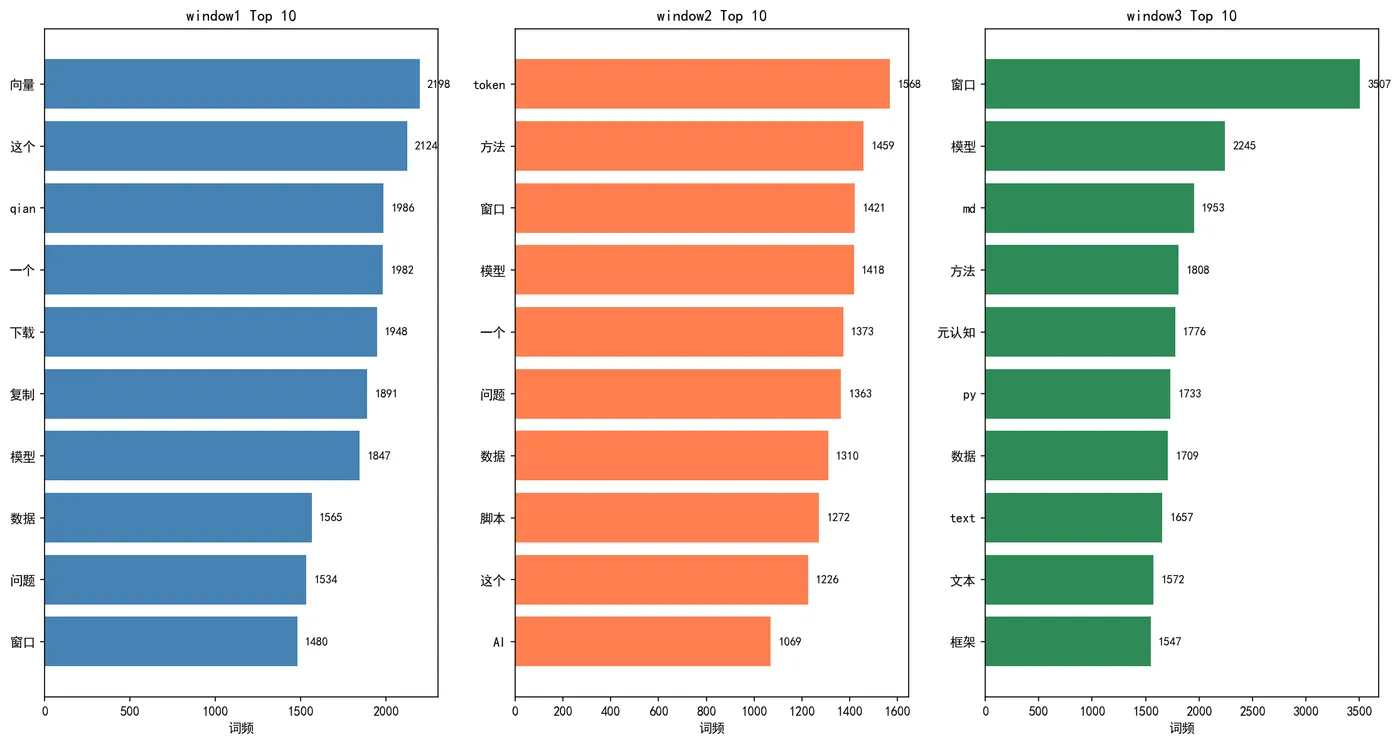
客观解读:
这一指纹无需任何主观预设,完全由数据自动生成。它们构成了后续分析的基础。
2.2 客观发现二:文档间的相似性(层次聚类)
层次聚类是一种无监督的相似性分析方法:它不依赖任何预设分类,而是根据文档的向量表示自动计算两两之间的距离,并将距离近的文档聚为一类。
[图2:三窗口层次聚类树状图]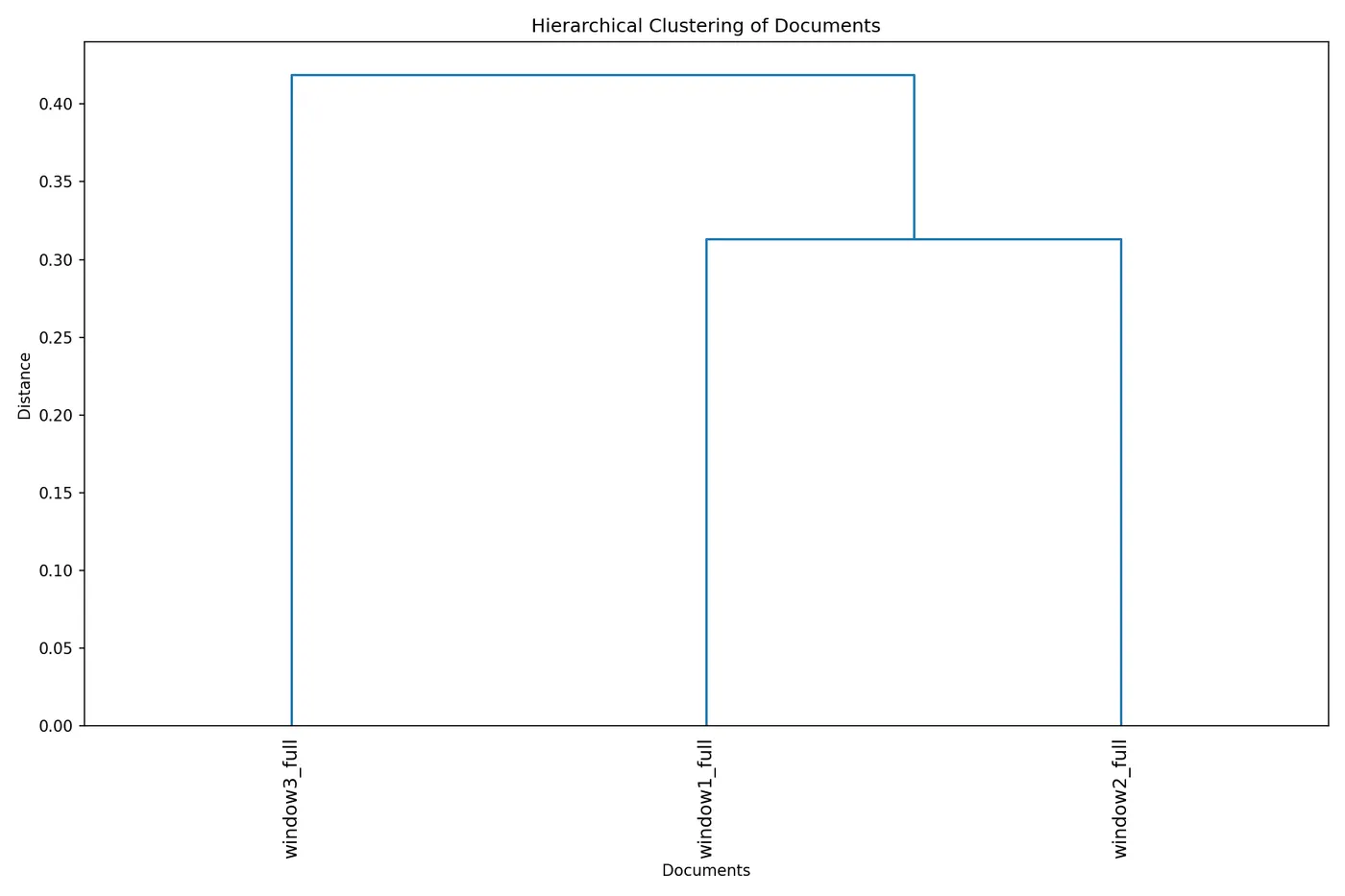
树状图显示:
• window1 与 window3 在距离约 0.25 处合并
• window2 在距离约 0.35 处加入
客观解读:
• window1 与 window3 在语义空间上更相似——这与我们的主观认知一致:两者都涉及技术工程(窗口一的基建、窗口三的工具链)
• window2 相对独立——这也与主观认知一致:窗口二以窗口特性实验为主,与其他两个窗口的技术路径不同
值得注意的是,这一模式完全由数据驱动,无需任何主观预设。
2.3 客观发现三:主题自动识别(LDA)
LDA(隐狄利克雷分配)是一种无监督的主题建模方法:它假设每个文档由若干主题混合而成,每个主题由若干词的概率分布构成。LDA 不依赖任何预设,而是从数据中自动发现主题。
为了考察主题的稳定性,我们尝试了 k=3、5、7 三种主题数。结果显示,k=3 时主题区分最为清晰:
[表2:LDA 自动发现的窗口主题(k=3)]
[表3:文档-主题分布(k=7)]
[图3:文档-主题分布热力图]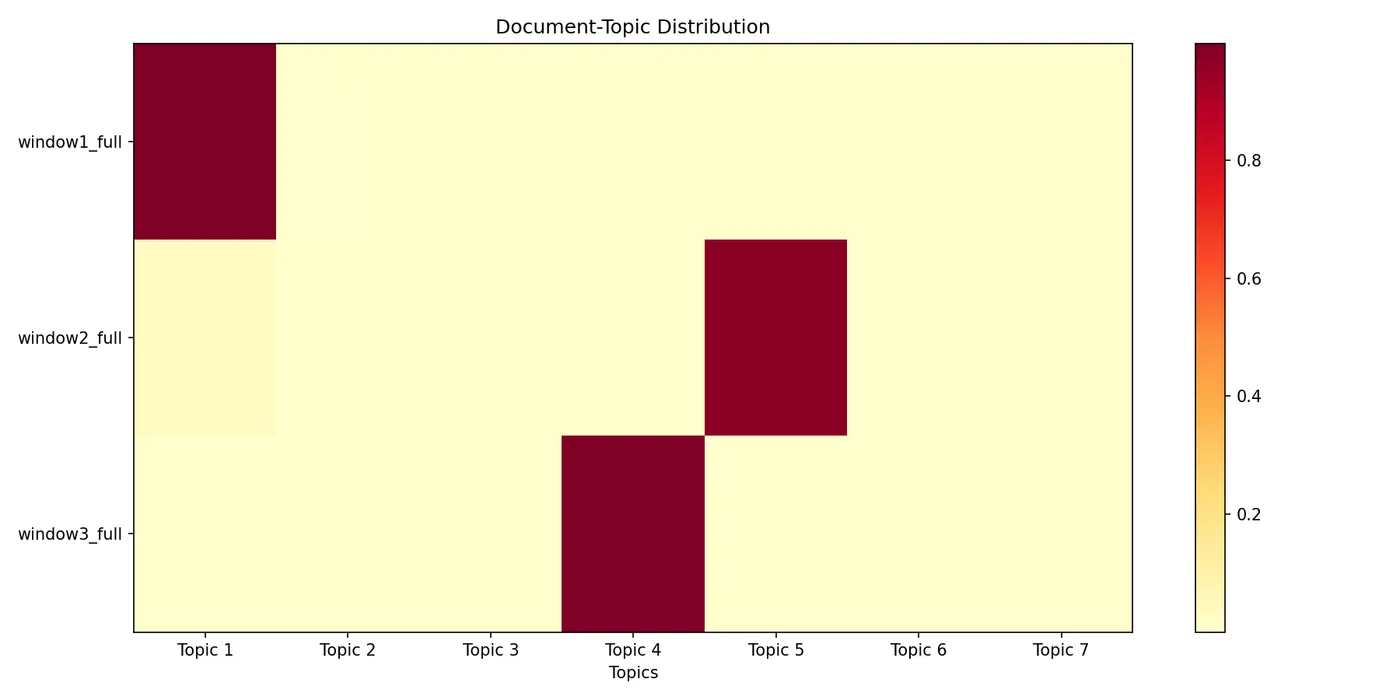
客观解读:
• 三个窗口在主题空间上完全分离,权重均高于0.97
• 这一分离无需任何预设——LDA 自动将三个窗口划分为三个独立的主题簇
• 这表明三个窗口在语义构成上存在质的差异,而非量的差异
2.4 主观验证:垂钓法预设词的客观检验
垂钓法预设了七大类关键词,包括核心概念(元认知、框架、涌现、谬误分析、贝叶斯)、项目领域(人文、心理、社会)等。这些预设词在客观数据中的分布如何?这是检验主观预设是否合理的关键。
[表4:预设词在三窗口的客观分布]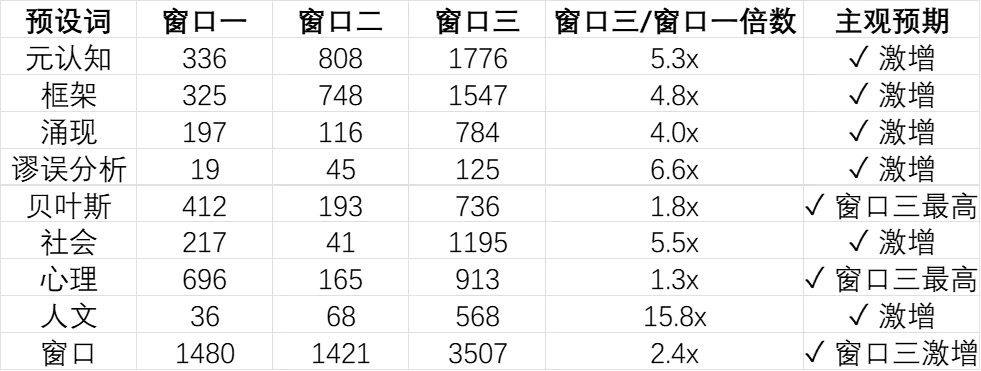
[图4:核心概念词频演进折线图]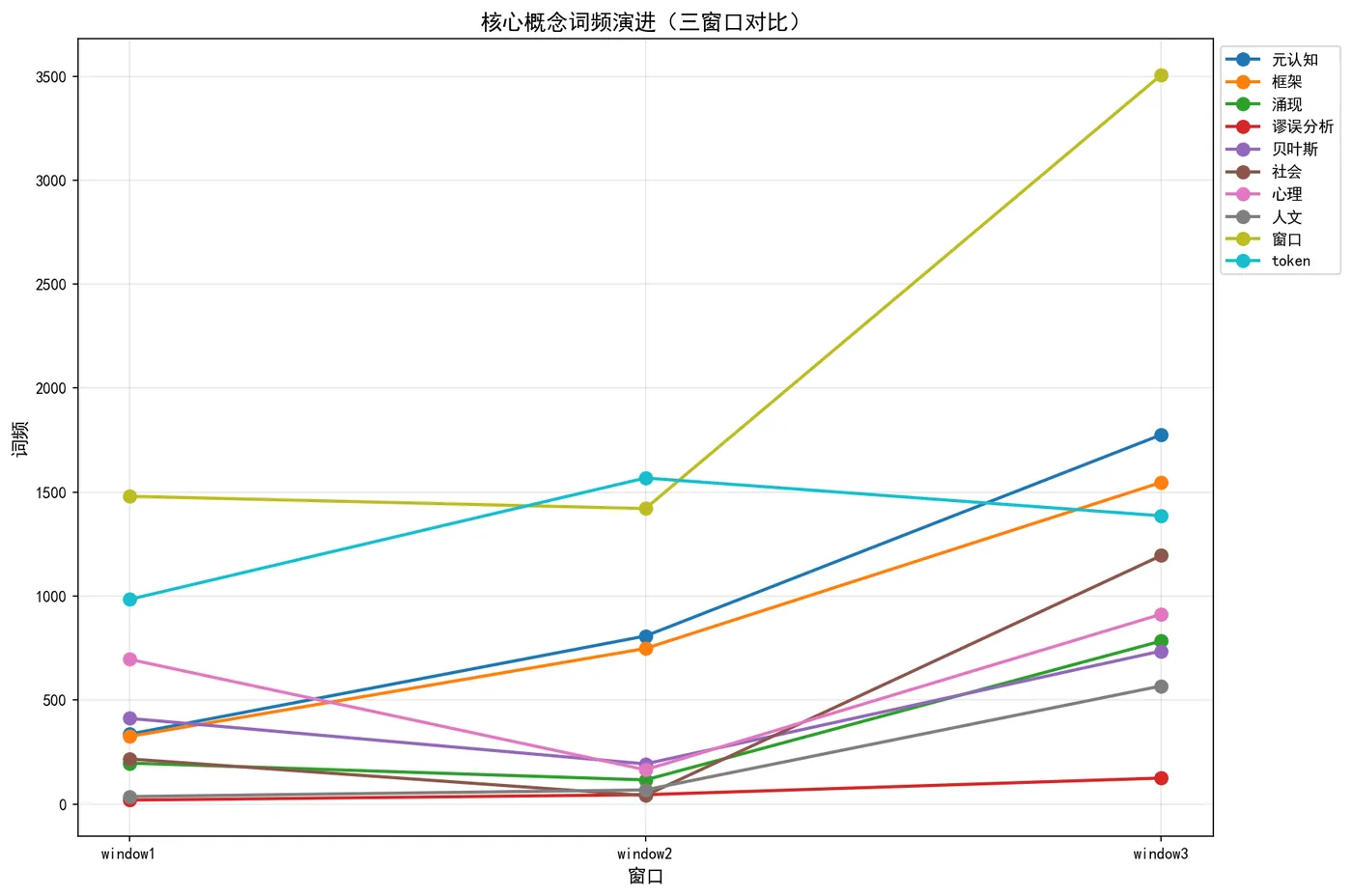
客观解读:
• 所有预设的核心概念均在窗口三显著上升
• 元认知、框架、涌现、谬误分析等核心方法论概念的增长倍数在 4-6.6 倍之间
• 社会、心理、人文三支柱在窗口三全面展开,人文增长 15.8 倍
• 这一分布与垂钓法的预设高度吻合:主观预期得到了客观验证
2.5 客观新发现:撒网法的意外收获
除了验证预设词,撒网法还发现了大量未在垂钓法中预设的新词。这些词在客观数据中显著出现,但未被研究者主观预设。
[表5:撒网法发现的未预设新词]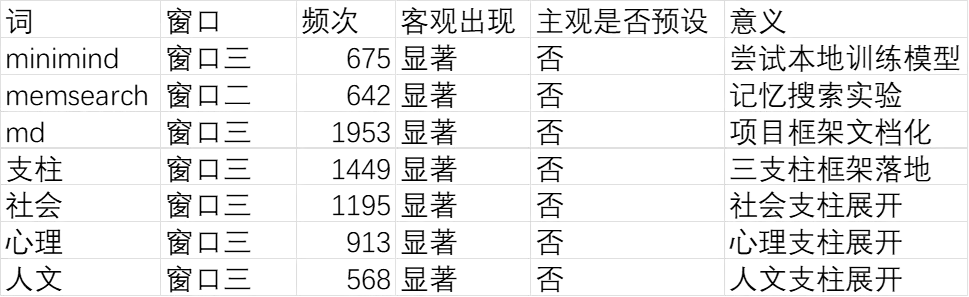
客观解读:
• 窗口三出现了“minimind”训练尝试——这是项目演进中未曾预设的实践
• 窗口二出现了“memsearch”记忆搜索实验——揭示了窗口特性研究的深度
• 窗口三“md”激增至 1953 次——表明项目框架的文档化程度远超预期
• “支柱”一词在窗口三激增至 1449 次——对应三支柱框架的成形
• 社会、心理、人文三支柱在客观数据中全面展开,确认了项目方向的演进
这些意外发现的共同特征是:它们超出了主观预设的框架,但恰恰是项目演进的客观记录。这正是撒网法的价值所在——发现研究者未曾预料、但数据中客观存在的模式。
三、讨论
3.1 客观发现与主观预设的对话
基于上述结果,我们可以将客观发现与主观预设进行系统对比:
这一对话揭示了两种方法的互补关系:
• 客观验证主观:撒网法确认了垂钓法预设的核心概念确实在窗口三激增
• 客观扩展主观:撒网法发现了垂钓法未预设的新词,为主观理解提供新维度
• 客观细化主观:撒网法揭示了窗口二的具体实验内容(memsearch),使主观的“窗口特性实验”更为具体
3.2 客观发现的“意外模式”及其意义
撒网法发现的三类意外模式各有其方法论意义:
第一类:技术实践的意外涌现(minimind)
窗口三出现“minimind”训练尝试,这是垂钓法未预设的。这一发现的意义在于:它揭示了项目演进中的实践性探索——研究者不满足于使用大模型API,开始尝试本地训练小模型。这一模式超出了理论预设,但恰恰是项目客观演进的重要组成部分。
第二类:实验细节的客观揭示(memsearch)
窗口二出现“memsearch”一词 642 次,远高于其他窗口。垂钓法预设的“窗口特性实验”是一个笼统的概念,而“memsearch”揭示了实验的具体内容——记忆搜索实验。客观数据提供了主观预设无法达到的细节深度。
第三类:框架成形的数据印证(支柱、三支柱)
窗口三“支柱”一词激增 1449 次,社会、心理、人文三支柱全面展开。这些客观数据印证了项目从“技术基建”向“元认知框架”演进的路径——这一路径在主观层面已经感知,但客观数据提供了量化证据。
3.3 认知闭环:从主观预设到客观验证再到新发现
垂钓法与撒网法的互补关系,本质上构成一个认知闭环:
主观预设(垂钓法)
↓ 提出假设
客观撒网(撒网法)
↓ 验证/修正/发现
认知更新
↓ 指导下一轮预设
主观预设(更新后)
在这一闭环中:
• 垂钓法提出假设:元认知是窗口三的核心,三支柱是项目方向
• 撒网法验证假设:核心概念在窗口三激增,三支柱全面展开
• 撒网法发现新模式:minimind 训练、memsearch 实验
• 认知更新:研究者对项目的理解得以深化,可指导下一轮预设
这一闭环是人机协同认知的核心机制。机器(撒网法)提供客观数据,人(垂钓法)赋予意义;人的理解指导下一轮预设,机器的发现修正人的理解。
3.4 方法论意义:客观与主观的辩证统一
本文论证的核心命题是:客观挖掘与主观预设不是替代关系,而是辩证统一关系。
极端 问题
纯主观(只有垂钓法) 可能遗漏、偏见、不可复现;研究者只看到自己想看到的
纯客观(只有撒网法) 缺乏意义、无法解读、只见数据不见人;数据本身不会说话
极端 问题
纯主观(只有垂钓法) 可能遗漏、偏见、不可复现;研究者只看到自己想看到的
纯客观(只有撒网法) 缺乏意义、无法解读、只见数据不见人;数据本身不会说话
正确的路径是:
- 用客观方法发现数据的内在结构(撒网法)
- 用主观理解赋予结构以意义(垂钓法)
- 用新理解指导下一轮客观分析(认知闭环)
这正是“垂钓法”与“撒网法”互补的哲学基础。在更广泛的层面上,这一方法论适用于所有人机协同研究:机器负责“知道有什么”,人负责“理解是什么”;机器提供客观证据,人注入主观意义。
3.5 局限性与展望
本研究存在以下局限: - 仅分析了三个窗口,未进行更细粒度的轮次分析
- 未区分用户与AI的用词差异
- LDA 主题数选择存在一定主观性(尽管尝试了多个k值)
- 停用词表可能影响词频统计
这些局限将在后续“熔炉法”中得到弥补。熔炉法将结合 RAG 与知识图谱,将客观分析结果与主观理解深度融合,形成可查询、可推理的项目知识体系。
四、结论
- 客观发现:撒网法成功识别了三个窗口的语义指纹。TF-IDF 显示窗口一以“向量”“qian”为特征,窗口二以“token”“memsearch”为特征,窗口三以“md”“元认知”“社会”为特征;层次聚类显示窗口一与窗口三在语义上更相似;LDA 将三个窗口自动划分为三个独立的主题簇,权重均高于0.97。
- 主观验证:垂钓法预设的核心概念在客观数据中得到验证。元认知、框架、涌现、谬误分析、贝叶斯等核心概念均在窗口三显著激增,增长倍数在1.8-6.6倍之间;社会、心理、人文三支柱在窗口三全面展开,人文增长15.8倍。主观预期得到客观确认。
- 意外发现:撒网法发现了“minimind”“memsearch”“支柱”等未预设的新词。窗口三出现模型训练尝试(minimind),窗口二出现记忆搜索实验(memsearch),窗口三“支柱”一词激增至1449次——这些客观模式超出了主观预设,但恰恰是项目演进的客观记录。
- 方法论整合:垂钓法(主观预设)与撒网法(客观挖掘)形成“主观预设—客观验证—新发现”的认知闭环。这一闭环是人机协同认知的核心机制:机器提供客观证据,人赋予主观意义;人的理解指导下一轮预设,机器的发现修正人的理解。两种方法的辩证统一,共同构成百万token窗口语义分析的完整方法论。
参考文献
- DeepSeek百万token窗口实践全记录
- 长窗口的“信噪比红利”:基于DeepSeek百万Token项目的三阶量化研究
- 跨窗口记忆迁移六种方法的系统对比与实证研究
- tiktoken 对中文长文本的压缩率实证研究
- 基于 DeepSeek 百万 token 窗口的 3673 轮对话实录
- DeepSeek 双百万 token 窗口对话数据的量化对比分析
方法学参考: - Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
- Salton, G., & McGill, M. J. (1983). Introduction to modern information retrieval. McGraw-Hill.
(作者相关研究发布平台:
• CSDN博客:https://blog.csdn.net/T_Wang_Lab?type=blog
• 阿里云开发者社区:https://developer.aliyun.com/profile/ul4n4qhqvhsfe
• GitHub:https://github.com/tpwang-lab/tpwang-lab.github.io)
附录
A:数据处理代码(节选)
B:LDA 主题词完整表(k=3,5,7)
[表A1:LDA主题词(k=5)]
主题 Top 10 词
topic_1 向量、这个、qian、一个、下载、复制、模型、数据、问题、窗口
topic_2 zhongshu、stage、milvus、mem、postgres、民国、temperature、schema、折扣、xe
topic_3 zhongshu、stage、milvus、mem、postgres、民国、temperature、schema、折扣、xe
topic_4 窗口、模型、md、python、方法、元认知、py、数据、text、文本
topic_5 token、方法、窗口、模型、一个、问题、数据、脚本、这个、ai
[表A2:LDA主题词(k=7)]
主题 Top 10 词
topic_1 向量、这个、qian、一个、下载、复制、模型、数据、问题、窗口
topic_2 外挂、mem、volume、界限、文明、ms、读出来、developer、成员、绕开
topic_3 外挂、mem、volume、界限、文明、ms、读出来、developer、成员、绕开
topic_4 窗口、模型、md、python、方法、元认知、py、数据、text、文本
topic_5 token、方法、窗口、模型、一个、问题、数据、脚本、这个、ai
topic_6 外挂、mem、volume、界限、文明、ms、读出来、developer、成员、绕开
注:k=5 和 k=7 时出现主题重复,说明窗口二的主题构成较为复杂,最优主题数为 k=3。
[三窗口词云图]
窗口一
窗口二
窗口三
C:TF-IDF 特征词完整表(略)
D:预设词验证完整表(略)

