
下载地址:http://lanzou.co/i79981686
项目编译入口:
package.json
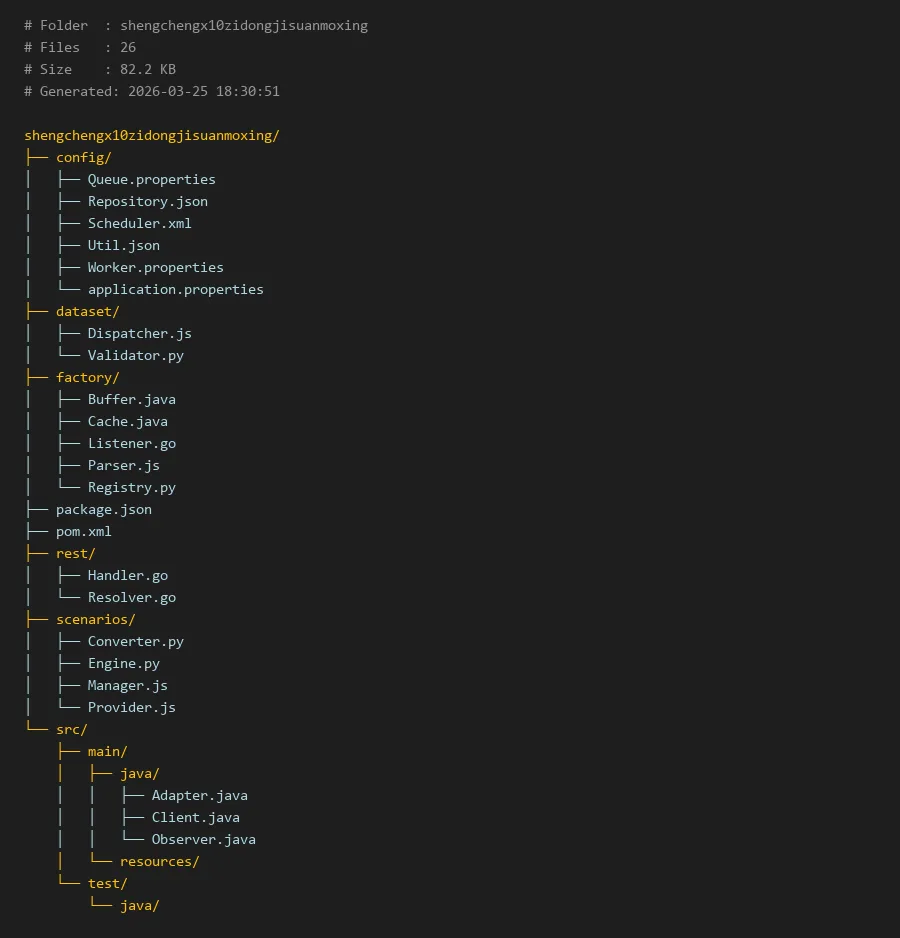
# Folder : shengchengx10zidongjisuanmoxing
# Files : 26
# Size : 82.2 KB
# Generated: 2026-03-25 18:30:51
shengchengx10zidongjisuanmoxing/
├── config/
│ ├── Queue.properties
│ ├── Repository.json
│ ├── Scheduler.xml
│ ├── Util.json
│ ├── Worker.properties
│ └── application.properties
├── dataset/
│ ├── Dispatcher.js
│ └── Validator.py
├── factory/
│ ├── Buffer.java
│ ├── Cache.java
│ ├── Listener.go
│ ├── Parser.js
│ └── Registry.py
├── package.json
├── pom.xml
├── rest/
│ ├── Handler.go
│ └── Resolver.go
├── scenarios/
│ ├── Converter.py
│ ├── Engine.py
│ ├── Manager.js
│ └── Provider.js
└── src/
├── main/
│ ├── java/
│ │ ├── Adapter.java
│ │ ├── Client.java
│ │ └── Observer.java
│ └── resources/
└── test/
└── java/
shengchengx10zidongjisuanmoxing
简介
shengchengx10zidongjisuanmoxing是一个面向自动化计算模型生成的系统框架,旨在通过模块化设计实现高效的计算任务调度、数据处理和模型构建。该系统采用多语言混合架构,充分利用各种编程语言的优势,构建了一个灵活、可扩展的自动化计算平台。
系统核心设计理念是将计算任务分解为独立的模块,通过配置驱动的方式实现任务编排。项目结构清晰,各目录承担特定职责:config目录存放系统配置,dataset处理数据相关逻辑,factory提供核心组件工厂,rest实现API接口,scenarios包含具体业务场景实现。
核心模块说明
配置管理模块
config目录包含系统所有配置文件,采用多种格式以适应不同需求:
- application.properties:主配置文件,定义系统全局参数
- Queue.properties:消息队列配置
- Worker.properties:工作节点配置
- XML/JSON格式文件用于结构化配置
数据处理模块
dataset目录负责数据的调度和验证:
- Dispatcher.js:数据分发器,将输入数据路由到相应处理单元
- Validator.py:数据验证器,确保输入数据符合规范
工厂模块
factory目录实现核心组件的工厂模式:
- Buffer.java:数据缓冲区,临时存储处理中的数据
- Cache.java:缓存组件,提升数据访问性能
- Listener.go:事件监听器,响应系统状态变化
- Parser.js:数据解析器,处理不同格式的数据
- Registry.py:组件注册器,管理可用组件
REST接口模块
rest目录提供HTTP API接口:
- Handler.go:请求处理器,处理HTTP请求
- Resolver.go:路由解析器,将请求映射到相应处理器
场景模块
scenarios目录包含具体业务场景实现:
- Converter.py:数据转换器,在不同格式间转换数据
- Engine.p:计算引擎,执行核心计算逻辑
代码示例
配置文件示例
# config/application.properties
# 系统基础配置
system.name=shengchengx10zidongjisuanmoxing
system.version=1.0.0
system.mode=production
# 计算参数配置
computation.threads=8
computation.timeout=300
computation.memory.max=4096
# 日志配置
logging.level=INFO
logging.path=./logs
logging.rotation.size=100MB
{
"config/Repository.json": {
"repositories": [
{
"id": "model_repo_1",
"type": "git",
"url": "https://github.com/example/models.git",
"branch": "main",
"auth": {
"type": "ssh",
"key_path": "/path/to/private_key"
}
},
{
"id": "data_repo_1",
"type": "s3",
"bucket": "model-data-bucket",
"region": "us-east-1",
"credentials": {
"profile": "default"
}
}
],
"cache": {
"enabled": true,
"ttl": 3600,
"max_size": 1000
}
}
}
数据处理模块示例
```python
dataset/Validator.py
import json
import jsonschema
from typing import Dict, Any, Optional
from dataclasses import dataclass
@dataclass
class ValidationResult:
is_valid: bool
errors: list
warnings: list
class DataValidator:
def init(self, schema_path: str = None):
self.schemas = {}
if schema_path:
self.load_schemas(schema_path)
def load_schemas(self, path: str):
"""加载验证模式"""
with open(path, 'r') as f:
self.schemas = json.load(f)
def validate_model_input(self, data: Dict[str, Any],
model_type: str) -> ValidationResult:
"""验证模型输入数据"""
if model_type not in self.schemas:
return ValidationResult(
is_valid=False,
errors=[f"Schema for {model_type} not found"],
warnings=[]
)
schema = self.schemas[model_type]
validator = jsonschema.Draft7Validator(schema)
errors = []
for error in validator.iter_errors(data):
errors.append({
'path': list(error.path),
'message': error.message,
'validator': error.validator
})
warnings = self._check_data_quality(data, model_type)
return ValidationResult(
is_valid=len(errors) == 0,
errors=errors,
warnings=warnings
)
def _check_data_quality(self, data: Dict[str, Any],
model_type: str) -> list:
"""检查数据质量"""
warnings = []
# 检查缺失值
for key, value in data.items():
if value is None:
warnings.append(f"Field '{key}' contains null value")
# 检查数值范围
if model_type == 'regression':
numeric_fields = ['feature1', 'feature2', 'feature3']
for field in numeric_fields:
if field in data and isinstance(data[field], (int, float)):
if data[field] < 0 or data[field] > 100:
warnings.append(
f"Field '{field}'

