
最近在社区里看到不少开发者在讨论大模型落地时,总被三个概念搞得晕头转向:迁移学习、微调和知识蒸馏。有人以为它们是并列的技术,有人把微调和蒸馏混为一谈,甚至在实际项目中选错了方向——明明要降低推理延迟,却硬上全量微调,最后资源花了不少,线上还是跑不动。

其实这三者既有联系又有本质区别,理清了它们的关系,你才能针对业务场景做出正确选型。今天用几个职场小故事,帮你一次性搞懂。
一、迁移学习:站在巨人肩膀上的“哲学”
先说一个最常见的误解:很多人把迁移学习当成一种具体的算法,和微调、蒸馏并列。其实不然。
迁移学习是一套顶层指导思想,是所有“基于预训练模型”技术的总称。它的核心逻辑只有一句话:别从零开始造轮子。
想象一下:你开公司招人,是愿意招一个读完大学、有基础认知和通用能力的毕业生,还是愿意招一个刚上幼儿园的孩子,从识字算数开始教?答案不言而喻。
放到大模型里:现在的开源基座模型(如Llama 3、Qwen等),人家用几千张A100、花了几千万算力训出来的通用能力,你放着不用,非要自己从随机权重开始训练,那不是费力不讨好吗?
所以,只要你的训练过程不是从零随机初始化权重,而是用了别人预训练好的权重当起点,不管你后续做了什么操作——哪怕只是简单地在你的数据上继续训练——本质上都算用了迁移学习。
二、微调:给大模型做“岗前培训”
理解了迁移学习这个大框架,我们再看里面的具体操作。微调是目前大模型落地最常用的手段,它的目标是:让啥都懂一点的通用模型,变成懂你家业务、能搞定专属场景的行业专家。
继续用职场比喻:你招来的大学毕业生,学习能力强,但他不懂你们公司的内部黑话,不知道你们的客服SOP,更不懂你们医疗/法律/工业领域的专属规则。怎么办?你把公司攒了好几年的业务资料、标注好的文件夹拿出来,给他做集中的岗前培训。培训完了,他还是他,底层的认知能力没变,但已经完全适配你们公司的业务需求了。
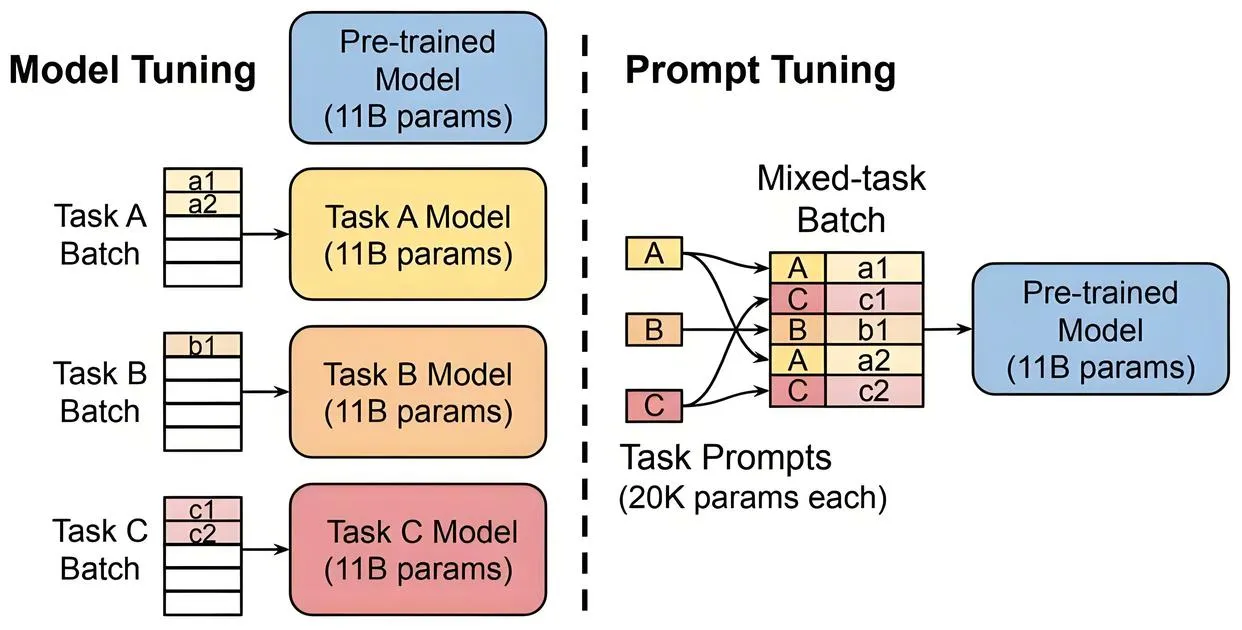
落到技术层面,微调就是拿着预训练好的模型权重,在你自己的业务数据集上继续跑反向传播,更新模型的参数。现在常用的LoRA、P-Tuning等方法,本质上是“省钱版的微调”——把模型99%以上的权重冻结不动,只更新极少一部分参数,效果接近全量微调,但算力成本大大降低。
什么时候必须用微调?
通用基座对你的垂直业务理解不到位(如医疗问诊、法律合规)
需要模型固定输出特定格式或风格(如必须输出JSON、必须用客服标准话术)
微调的核心目标只有一个:把你专属业务场景的效果提上去。
三、知识蒸馏:大模型当“师父”,小模型学艺
最容易和微调搞混的就是知识蒸馏,因为它也涉及训练过程。但两者的核心目的从根上就不一样——蒸馏的目标从来不是提升效果,而是在尽量保住效果的前提下,把模型体积压下去、把推理速度提上来。
再打个比方:你们公司有个深耕行业几十年的老专家,能力强、经验足,但薪资高、响应慢,一个人只能同时对接几个项目,铺不到一线。你想找个实习生来干活,薪资低、响应快、能批量复制,但实习生底子薄,直接上岗肯定不行。怎么办?让老专家手把手带徒弟。
老专家带徒弟,不只是告诉他“这道题的正确答案是A”,更重要的是,会把自己的思考逻辑、判断标准、为什么选A不选BCD的原因,全教给徒弟。
蒸馏就是这个逻辑:
- Teacher模型:效果好、参数量大的模型(老专家)
- Student模型:你想要训的小参数量模型(实习生)
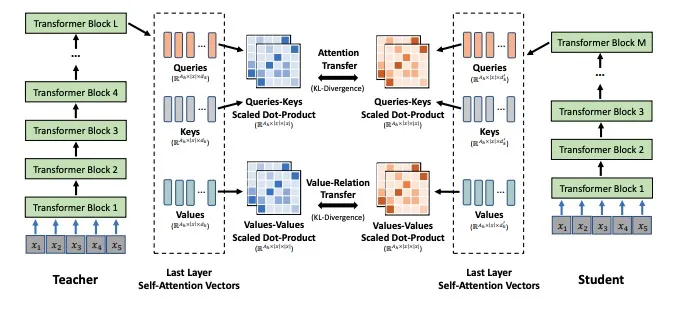
训练时,Teacher模型不仅给出真实标签,还会把自己的输出分布、中间层的特征全给Student模型。Student要学的,不只是“答对题”,更要学老师的“思考方式”。等学成出师,Student虽然参数量小、推理速度快,但干活的效果能无限接近Teacher。
什么时候该用蒸馏?
大模型效果确实好,但部署成本太高、推理速度太慢,线上业务扛不住(如高并发客服场景)
需要做端侧部署(把模型放到手机、嵌入式设备上)
蒸馏的核心目标也很明确:降成本、提速度,同时尽量保住效果。
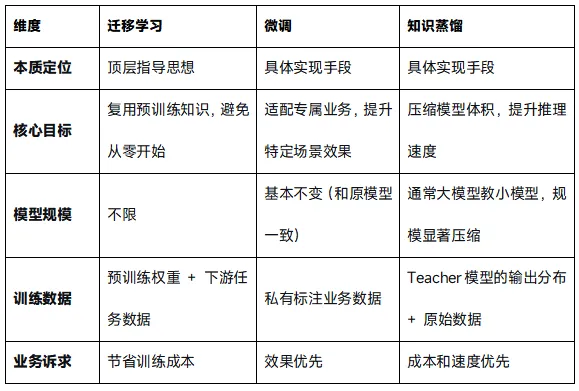
四、一张表看清三者的关系
为了更直观地对比,我们整理了一个表格:
五、实战中到底怎么选?
理论说完了,真到干活的时候,该怎么决策?一般按三步走:
第一步:先测基座模型,别急着训练
拿主流的开源基座(Llama 3、Qwen等)直接测你的业务场景,看零样本效果能否满足需求。很多人上来就要微调,结果测完发现基座直接够用,白白浪费时间和算力。如果效果够了,恭喜你,直接上线,省大钱了。
第二步:评估预算和业务对延迟的硬性要
如果你不差钱,服务器算力管够,核心诉求就是极致的效果,那直接上微调。数据多就做全量微调,数据少就用LoRA等高效方法。
如果预算有限,或业务有硬性延迟要求(如必须毫秒级响应),或者要做端侧部署,大模型根本满足不了,那优先考虑蒸馏。找个效果好的大模型当老师,训一个小模型(比如把7B蒸馏到1B/2B),成本和速度直接降一个量级。
第三步:看你手里的高质量标注数据量
有大量高质量私有数据 → 微调的效果会更稳,上限更高。
标注数据很少,甚至几乎没有 → 蒸馏有时更香,因为大模型可以给你生成大量的伪标签数据,喂给小模型训练,完美解决数据不足的问题。
六、组合拳才是王道
其实现在的真实落地场景,很少有人只用单一技术,大多是打组合拳。比如:
先拿千亿参数的闭源大模型,蒸馏出一个7B的开源模型;
再拿自己的业务数据做LoRA微调;
既拿到了大模型的能力,又适配了业务,还兼顾了部署成本和推理速度。效果往往出奇的好。
技术没有高下之分,能解决你的业务问题的,就是最合适的。理清概念只是第一步,动手实践才是关键。如果你正在学习大模型落地,想系统掌握从原理到实战的全流程,可以了解一下咕泡科技的大模型开发课程——从迁移学习、微调到蒸馏,都有配套项目和一线案例,帮你少走弯路。
毕竟,站在巨人的肩膀上,才能看得更远。
