
大模型用得越多,越容易陷入一种混乱状态。
- 这个项目用 OpenAI
- 那个服务接 Dashscope(Qwen)
- 测试环境还跑着本地 vLLM 或 Ollama
- 电脑里配置着一堆 API Key
刚开始问题不大,大家还能靠“记得住”来维持。
但只要项目一多、人数一多,麻烦立刻显现出来:
费用开始失控、模型切换成本极高、权限越来越乱、出了问题也很难排查。
于是,越来越多团队开始引入一个概念:
大模型网关(LLM Gateway)。
在目前的开源方案里,LiteLLM 是非常实用、也非常容易真正落地的一种。
我们按下面这条路线,一步步把它跑起来:
为什么要用 → Docker Compose 部署 → 模型与 Key 管理 → 权限与预算 → 实际调用 → 真实使用场景
一、LiteLLM 是什么?它解决的不是“能不能用”,而是“怎么管”
先说清楚一件事:
LiteLLM 本身不是模型。
它更像是一个统一的大模型代理层,或者你也可以理解为:
所有大模型的 统一入口 + 管理中枢
对外,它暴露的是 OpenAI 兼容 API;
对内,它可以接入各种不同来源的大模型,包括:
- OpenAI / Azure OpenAI
- Anthropic / Gemini / Dashscope
- HuggingFace
- 本地 vLLM、Ollama
- 甚至多家模型同时存在
最终的效果是:
应用侧只需要认一个地址、一个 Virtual Key。
至于后面到底用的是哪家模型、怎么调度、怎么限额,全部交给 LiteLLM 处理。
二、Docker Compose 部署(生产环境强烈推荐)
如果只是本地玩一玩,直接起一个 Docker 容器也可以。
但只要你是长期使用或多人使用,Docker Compose 是最稳妥的方式。
它有几个明显好处:
- 部署结构清晰
- 配置可复现
- 后期升级、迁移成本低
1️⃣ 准备目录结构
litellm/
├── docker-compose.yml
└── .env
保持简洁,后面所有东西都围绕这两个文件来。
2️⃣ 编写 docker-compose.yml
services:
litellm:
build:
context: .
args:
target: runtime
image: docker.litellm.ai/berriai/litellm:main-stable
#########################################
# Uncomment these lines to start proxy with a config.yaml file #
# volumes:
# - ./config.yaml:/app/config.yaml
# command:
# - "--config=/app/config.yaml"
##############################################
ports:
- "4000:4000"
environment:
DATABASE_URL: "postgresql://llmproxy:dbpassword9090@db:5432/litellm"
STORE_MODEL_IN_DB: "True"
env_file:
- .env
depends_on:
- db
healthcheck:
test:
- CMD-SHELL
- python3 -c "import urllib.request; urllib.request.urlopen('http://localhost:4000/health/liveliness')"
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
db:
image: postgres:16
restart: always
container_name: litellm_db
environment:
POSTGRES_DB: litellm
POSTGRES_USER: llmproxy
POSTGRES_PASSWORD: dbpassword9090
ports:
- "5432:5432"
volumes:
- /home/data/litellm/postgres/data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -d litellm -U llmproxy"]
interval: 1s
timeout: 5s
retries: 10
提醒一句:
记得把 db 的 volumes 路径改成您自己机器上的真实路径。
3️⃣ 环境变量 .env
LITELLM_MASTER_KEY=sk-1234
STORE_MODEL_IN_DB=True
这里的 LITELLM_MASTER_KEY,就是后面登录后台用的密码。
4️⃣ 启动服务
docker compose -p litellm up -d
5️⃣ 访问管理界面
浏览器打开:
http://localhost:4000
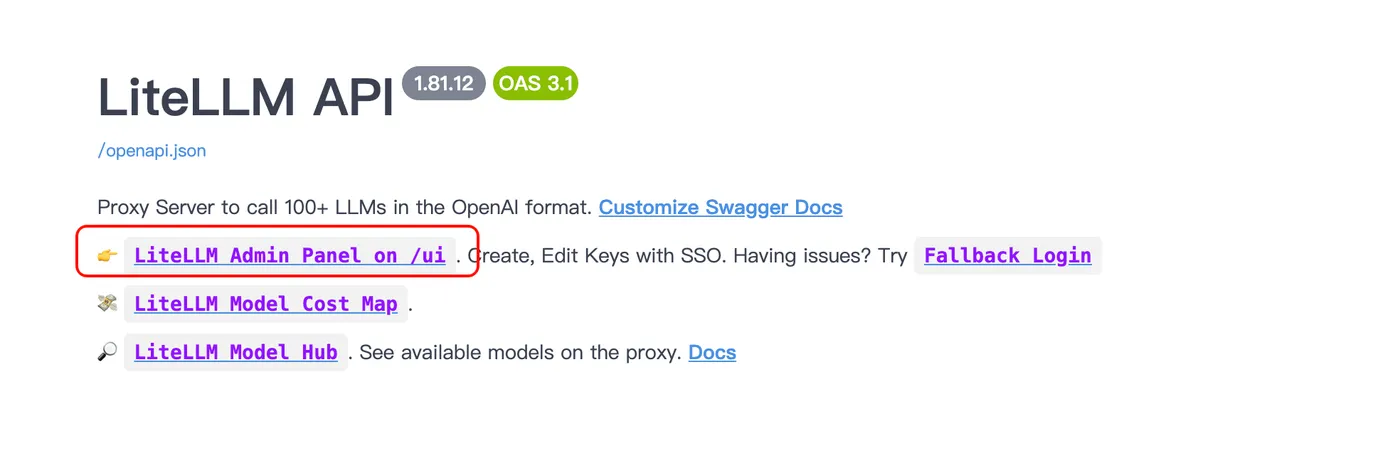
- 用户名:
admin - 密码:
.env里配置的LITELLM_MASTER_KEY
三、如何管理模型?从 Virtual Key 开始
LiteLLM 的核心设计之一,就是用 Virtual Key 来统一管理、隔离使用者和模型资源。
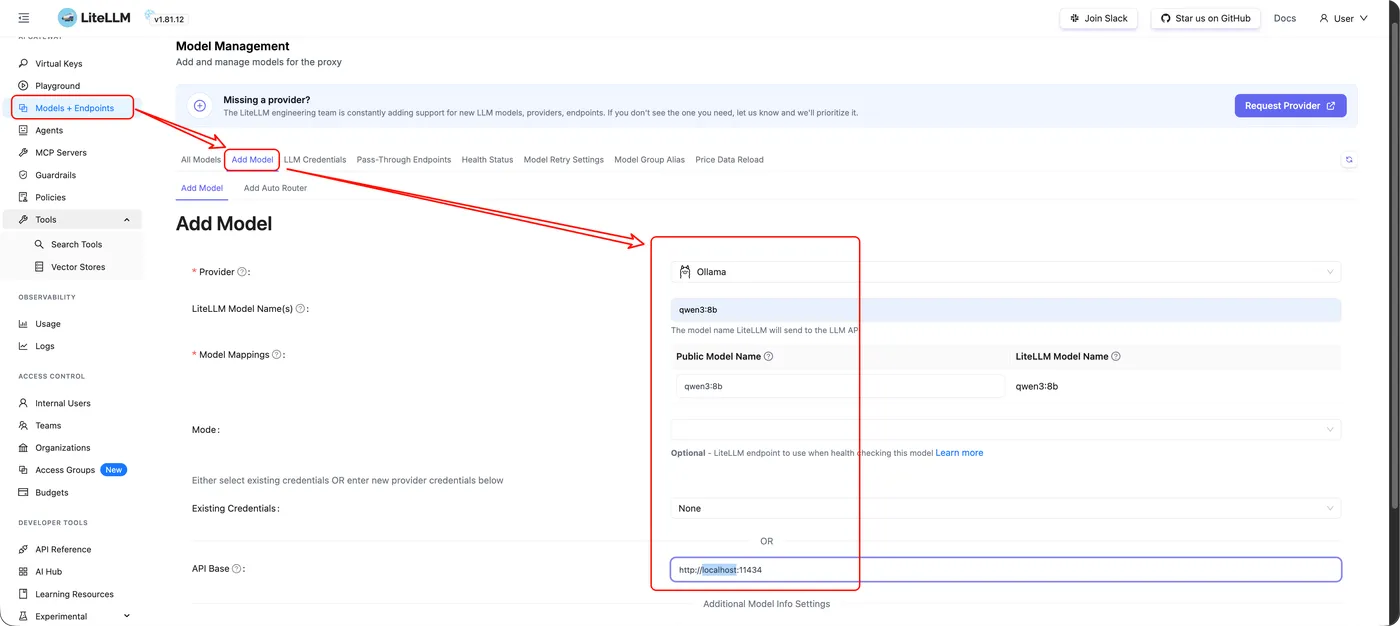
1️⃣ 添加模型(以 Ollama 为例)
在 Models + Endpoints 页面中,选择 Add Model。
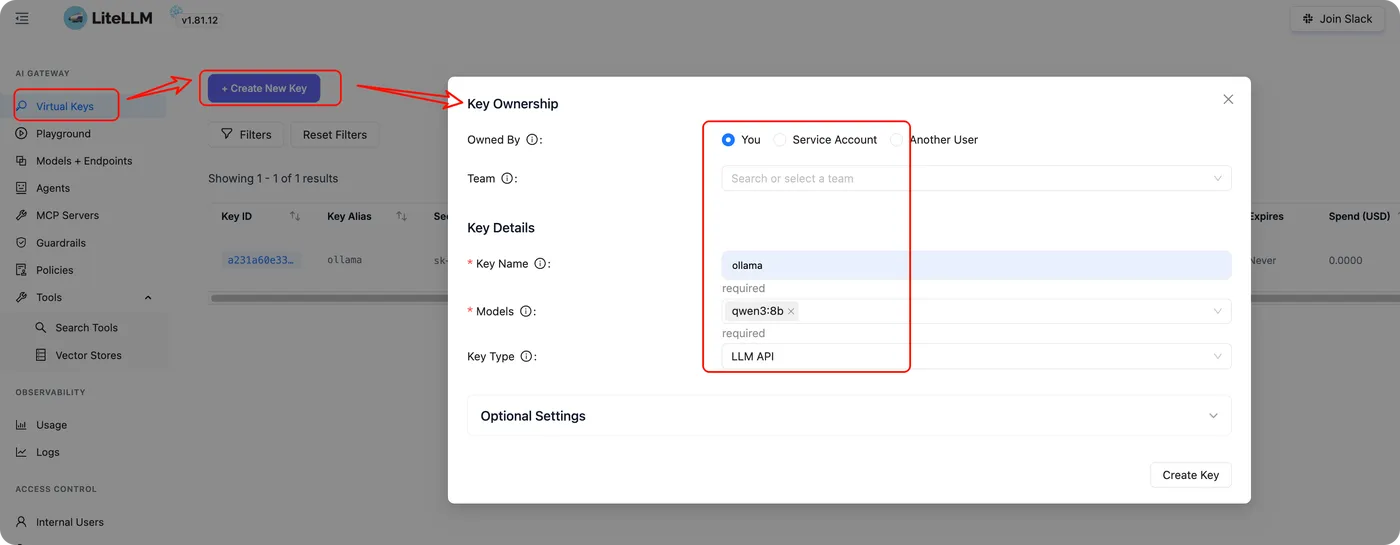
2️⃣ 创建 Virtual Key
- Key 的拥有者可以是你自己、某个服务账号,或者具体成员
- 可以绑定一个或多个模型
- 可以设置预算、速率限制
注意:生成的 Key 只显示一次,一定要保存好。
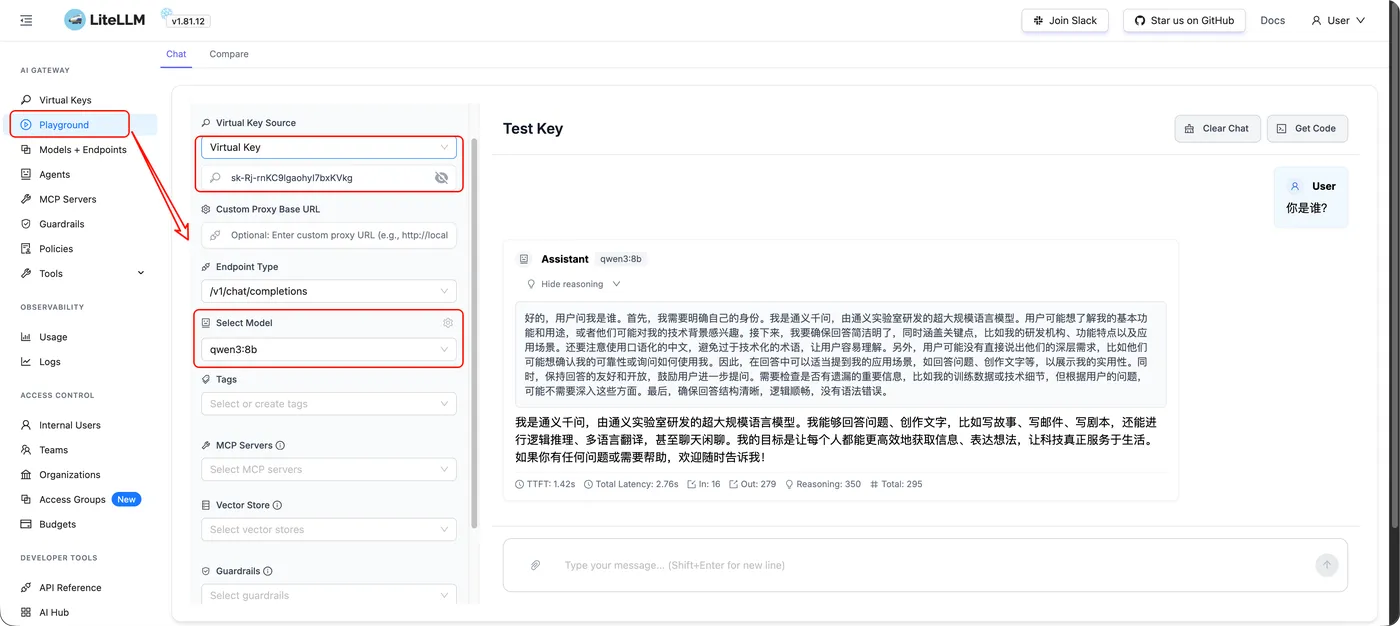
3️⃣ 在线验证是否可用
- 粘贴刚创建的 Virtual Key
- 选择允许使用的模型
- 直接测试请求
四、权限管理(多人协作非常重要)
当开始多人使用时,这一部分非常关键。
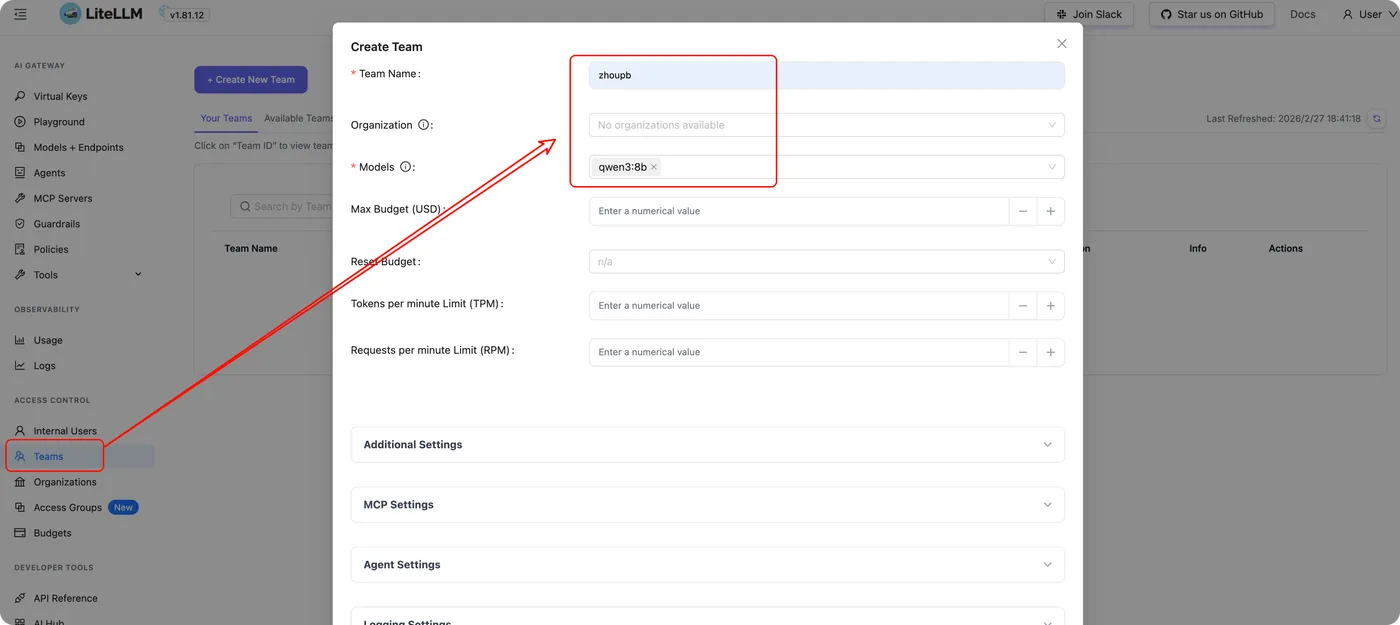
创建团队(Team)
用于统一管理成员和资源。
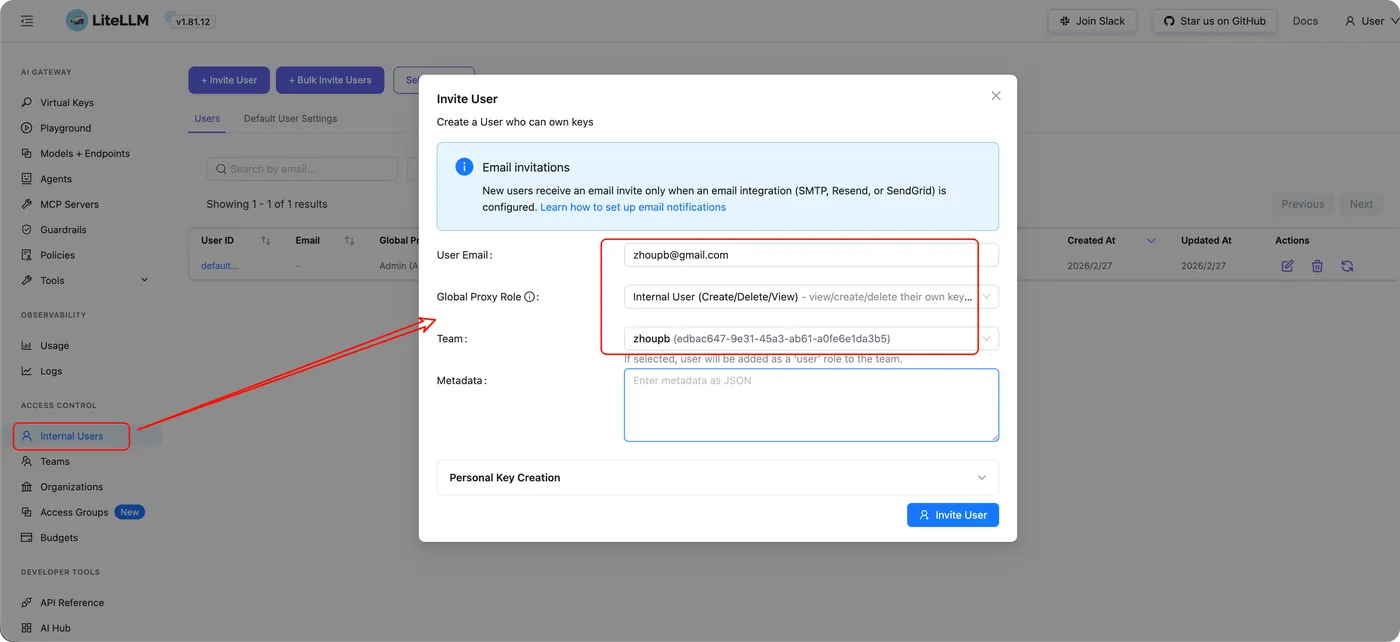
邀请内部用户(Internal User)
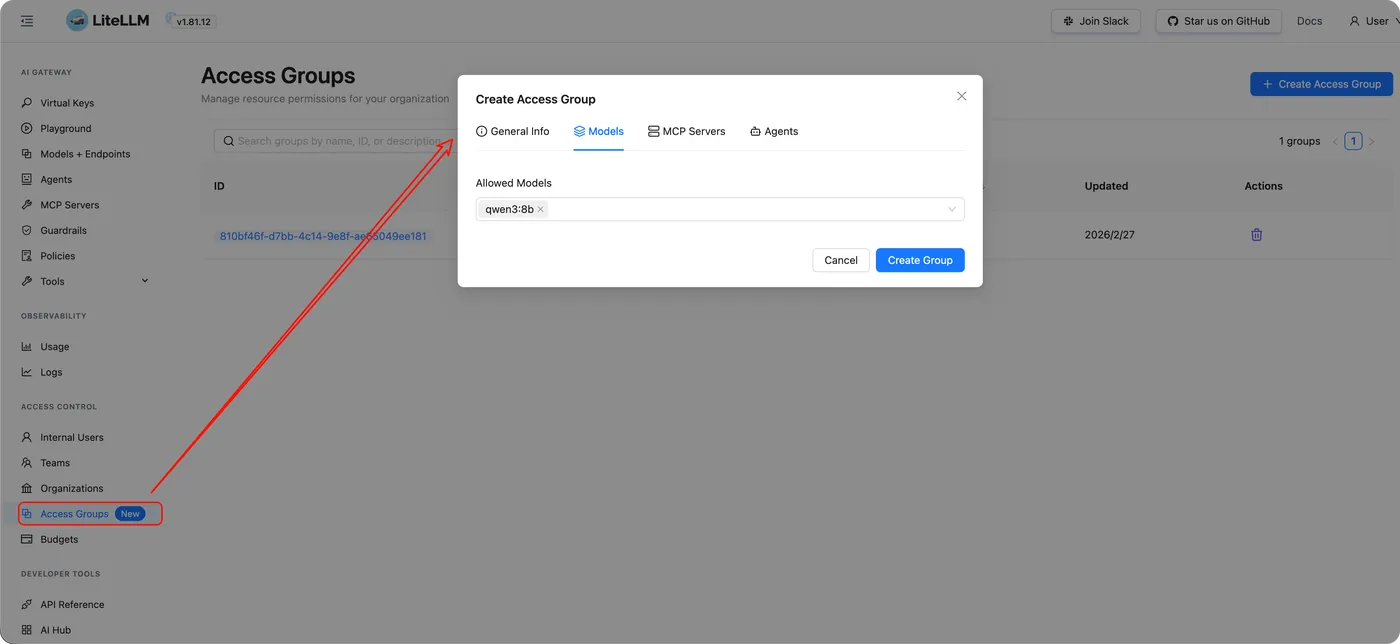
访问组(Access Groups)
通过访问组来控制:
谁能用哪些模型、哪些 Key。
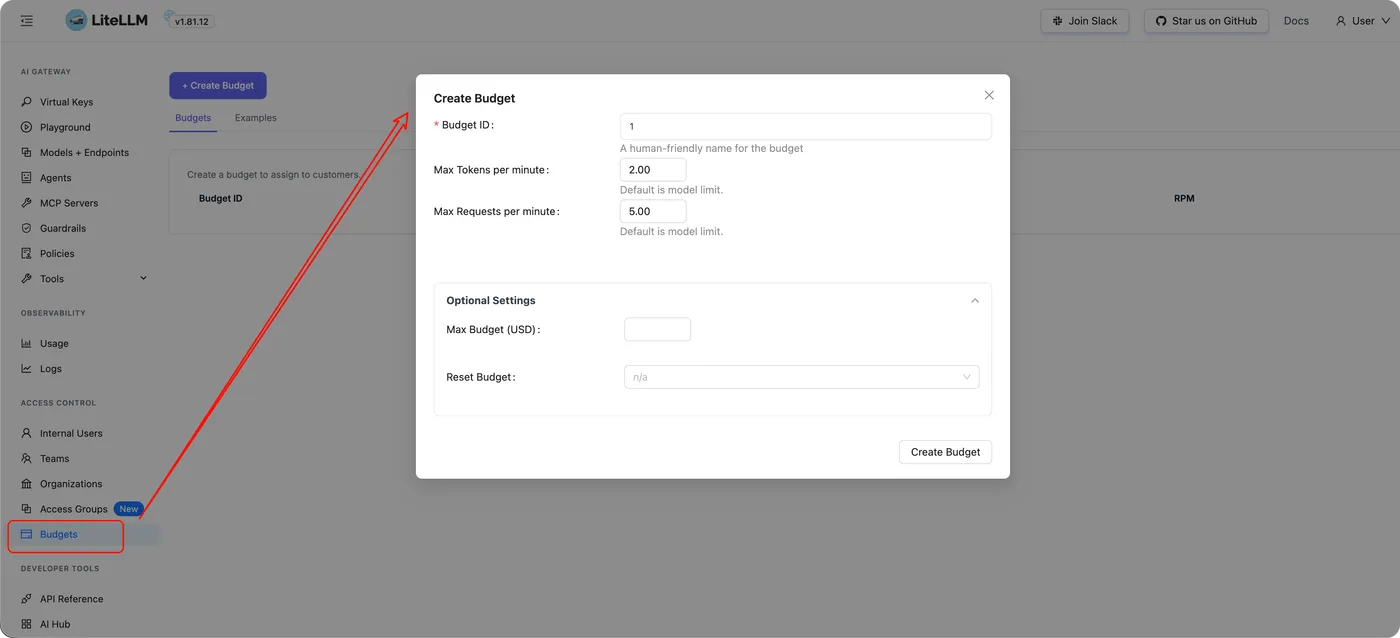
预算管理(Budgets)
如果你接的是收费模型,这一步非常有用。
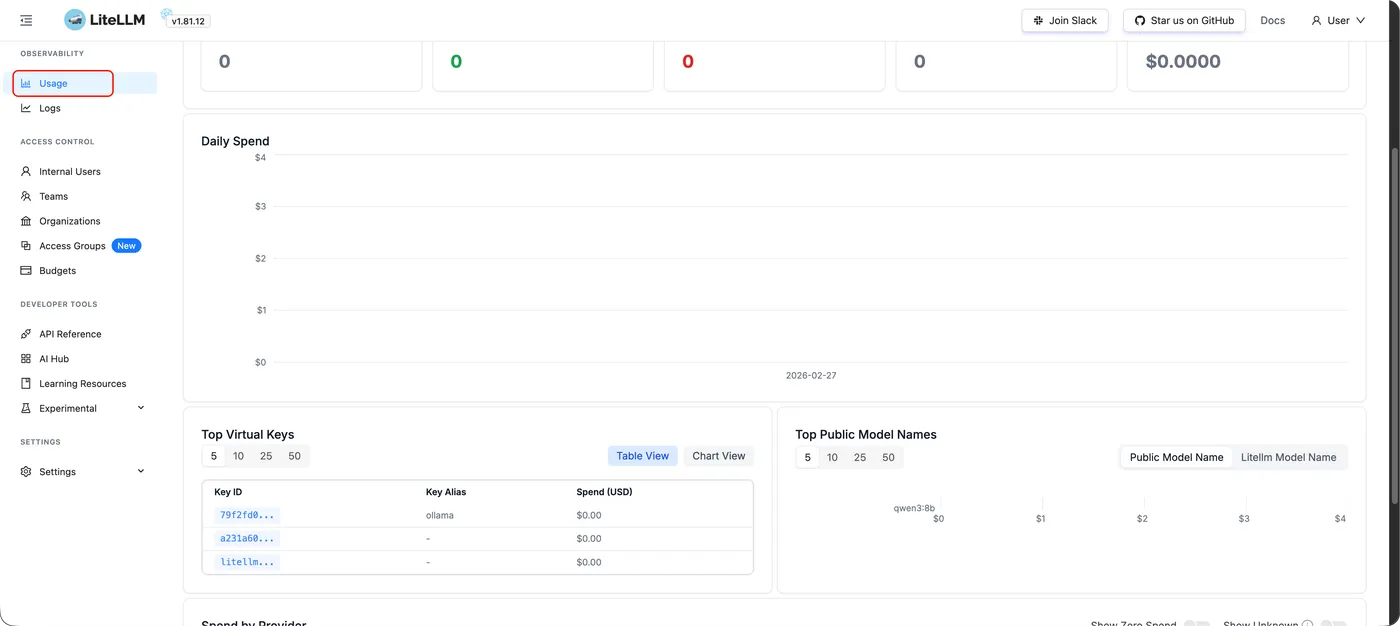
五、可观测性:终于知道钱花哪了
请求消耗统计
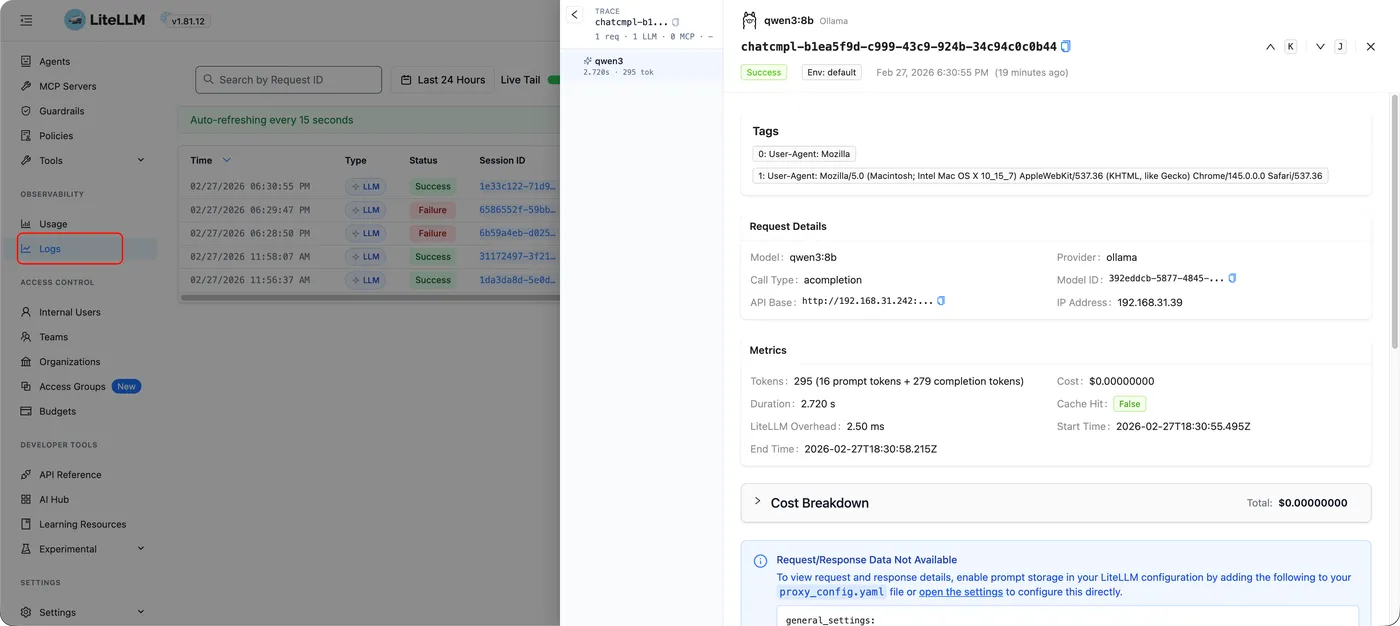
请求日志
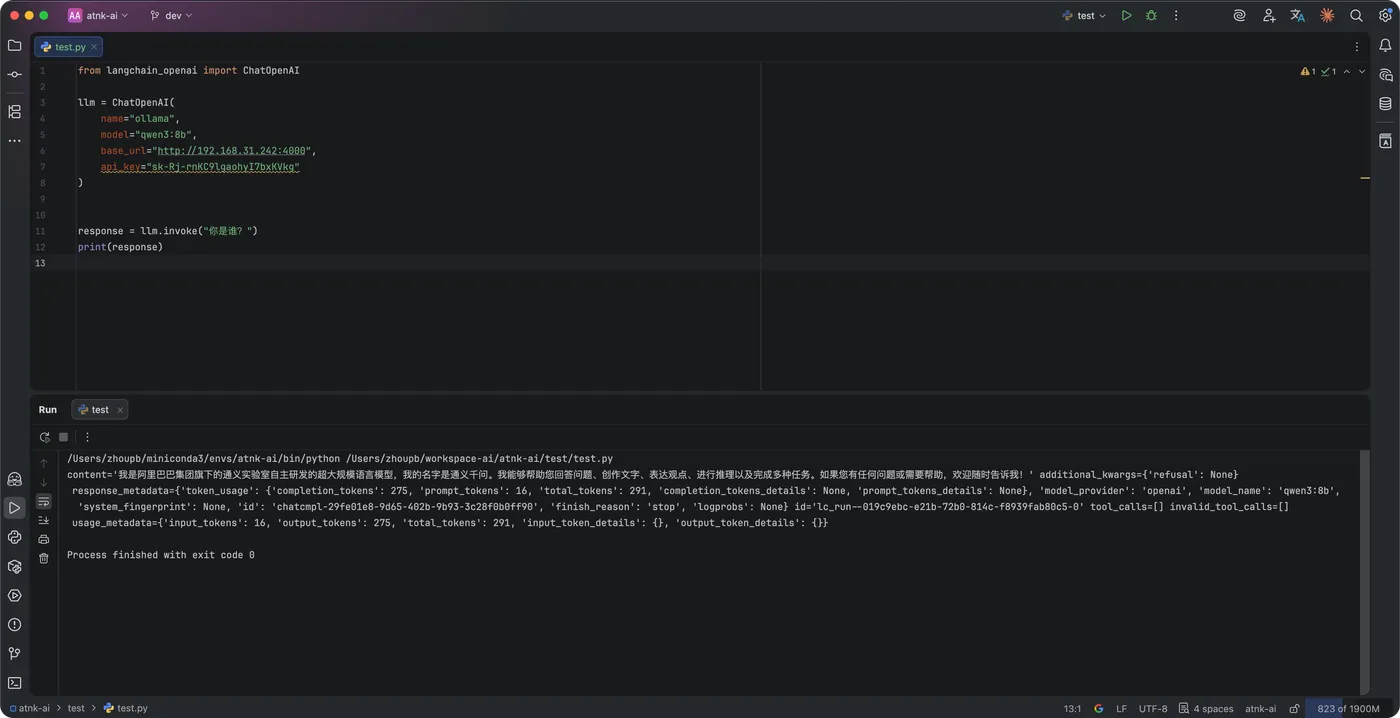
六、应用如何调用?几乎不用改代码
Python 示例
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
name="ollama",
model="qwen3:8b",
base_url="http://192.168.31.242:4000",
api_key="sk-Rj-rnKC9lgaohyI7bxKVkg"
)
response = llm.invoke("你是谁?")
print(response)
核心只有三点:
- 地址指向 LiteLLM
- Key 使用你创建的 Virtual Key
- 模型名来自你在后台定义的模型
七、真实使用场景
场景一:公司级 AI 中台
- 前端、后端、脚本工具
- 全部只接一个 Gateway
- 模型升级对业务透明
场景二:多项目成本可控
- 每个项目一个 Key
- 超额直接拒绝
- 成本一眼就能看清
场景三:模型策略随时调整
今天 GPT-4
明天 Gemini
后天本地模型
只改配置,不动业务代码。
写在最后
很多人刚接触大模型时,最关心的是效果;
真正用久了才发现,最难的是管理、成本和稳定性。
LiteLLM 并不会让模型变聪明,
但它能让你:
- 用得更稳
- 管得更清楚
- 换得更从容
如果你已经不满足“能跑就行”,
那这个网关,确实值得你认真搭一套。

