
做PostgreSQL数据分析时,你是不是经常遇到这样的难题?
比如,想对比每个员工的工资和他所在部门的平均工资,用普通聚合函数(avg)会把整个部门合并成一行,看不到每个员工的原始工资;又比如,想算每个月的累积销售额,手动逐行累加又麻烦又容易错;再比如,想给每个部门的员工按工资排名,不想打乱原有数据的行数……
这些看似棘手的问题,用窗口函数就能轻松解决。它就像一个“智能放大镜”——既能透过它看到当前行周围的相关数据,计算出统计结果,又不会破坏原始数据的每一行,保留所有细节。
今天咱们就从0到1,由浅入深吃透窗口函数,没有复杂的底层原理堆砌,全是新手能看懂的大白话+可直接复制运行的例子,看完就能上手实操。
一、先搞懂:什么是窗口函数?
窗口函数,本质就是“带观察窗口的统计函数”。
咱们先对比一个你可能熟悉的东西——普通聚合函数(比如sum、avg、count)。比如你用select depname, avg(salary) from empsalary group by depname;,得到的是每个部门的平均工资,每个部门只显示一行,原始的员工信息(比如empno、个人salary)就看不到了。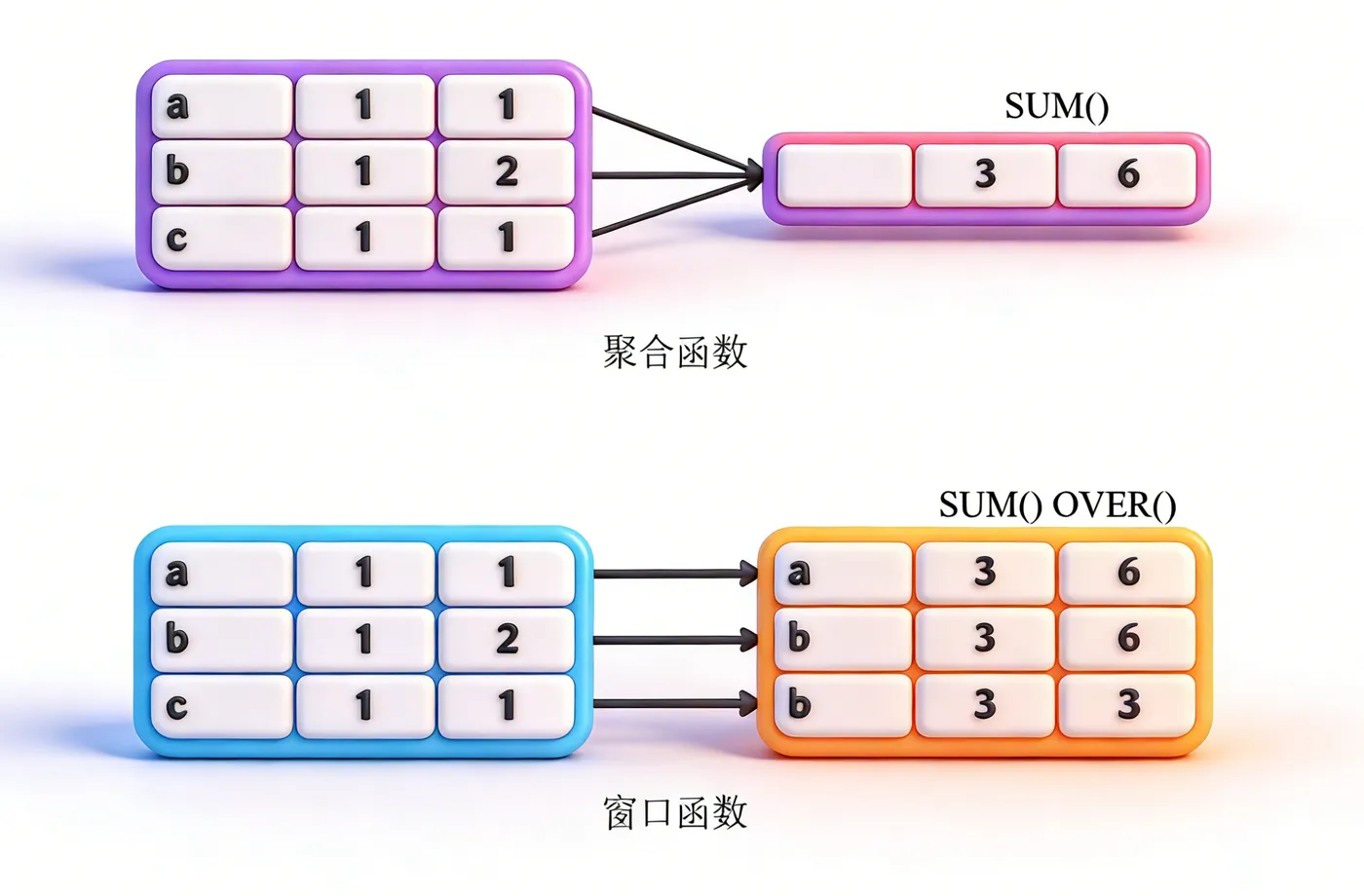
但窗口函数不一样:它计算统计值时,会给当前行“画一个窗口”,这个窗口里包含了和当前行相关的一批数据(比如同一个部门的所有员工),计算完之后,原始行的所有信息都会保留,不会被合并。
举个最直观的例子:用窗口函数查每个员工工资和部门平均工资,结果里会有每个员工的empno、salary,还有一列部门平均工资,一行都不会少——这就是窗口函数的核心优势:统计不丢行,细节不遗漏。
官方定义太生硬,咱们记这句就行:窗口函数对与当前行相关的一组数据进行计算,不合并行,保留原始数据的完整性,同时能拿到统计结果。
二、必懂的3个基本概念
窗口函数的核心,就是3个概念:窗口、分区、窗口帧。不用死记硬背,结合例子一看就懂。
1. 窗口(Window):你要观察的“数据范围”
窗口就是窗口函数要计算的“数据范围”——比如“当前员工所在部门的所有员工”“当前月份及之前3个月的销量”,这些范围就是窗口。
这个范围不是固定的,会跟着当前行变化:比如员工A在研发部,他的窗口就是研发部所有员工;员工B在销售部,他的窗口就是销售部所有员工,一行一个窗口,灵活得很。
2. 分区(Partition By):给数据“分组”,窗口只在组内生效
分区就相当于“分组筛选”,用Partition By 字段来指定,意思是“把数据按这个字段分成几组,窗口函数只在每组内部计算,不跨组”。
比如“按部门分区”,那么计算平均工资时,只会计算当前员工所在部门的平均,不会把研发部和销售部的工资混在一起算——这和group by分组很像,但区别在于:group by合并行,Partition By不合并行。
补充:如果不写Partition By,就相当于所有数据分成一组,窗口函数对全表数据计算。
3. 窗口帧(Frame):窗口里的“小范围”
窗口帧是窗口里的“更小范围”——比如“窗口是部门所有员工,窗口帧是当前员工及之前2个员工”,窗口函数若作用于窗口帧,就只计算这个小范围内的数据。大部分新手入门时会用默认窗口帧,但要想灵活用好转移动平均、累计统计等场景,必须吃透窗口帧的核心选项。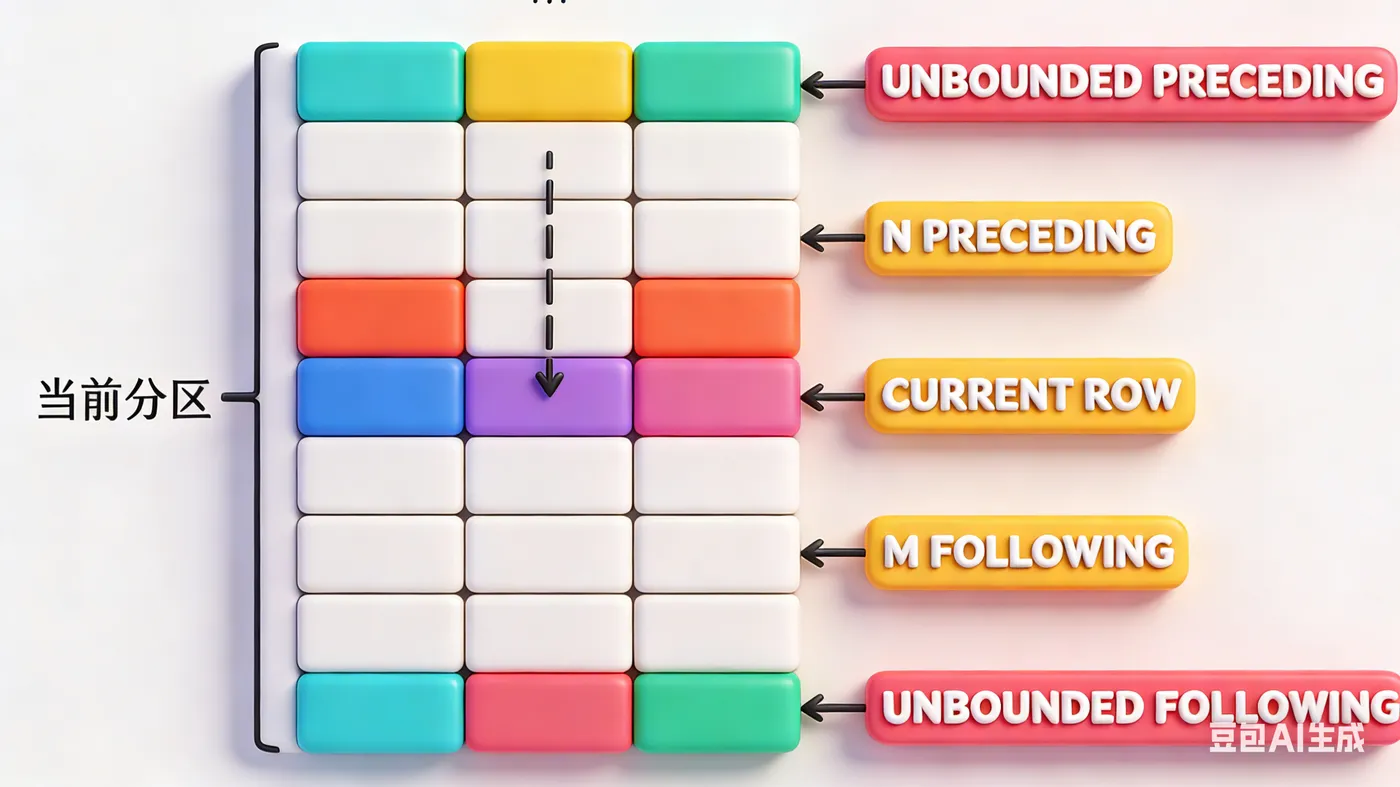
窗口帧由 frame_start(帧起始位置)和 frame_end(帧结束位置)定义,常用选项共6个,3个用于起始、3个用于结束,下面用大白话+简单例子,逐个讲清含义和用法,新手能直接套用:
(1)frame_start(帧起始位置):3个核心选项
作用:指定窗口帧从哪一行开始,必须和 frame_end 配合使用(可省略frame_end,默认是CURRENT ROW),结合帧模式(ROWS/GROUPS/RANGE,新手先重点记ROWS模式,最常用)讲解:
- UNBOUNDED PRECEDING:帧从“分区的第一行”开始(最开头的行),常用在累计求和、累计平均场景。
通俗理解:从分组的第一行,一直到后面指定的结束位置,覆盖分区开头到结束位置的所有行。
例子(ROWS模式):ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(帧从分区第一行到当前行,适合累计求和)。
- offset PRECEDING(可简写为“N PRECEDING”,N是数字):帧从“当前行前面第N行”开始,N必须是非负整数(不能是负数、NULL,也不能是变量)。
通俗理解:往前数N行,从那一行开始,到后面指定的结束位置,比如N=2,就是当前行前面第2行。
例子(ROWS模式):ROWS BETWEEN 2 PRECEDING AND CURRENT ROW(帧从当前行前面2行到当前行,共3行,适合近3期移动平均)。
- CURRENT ROW:帧从“当前行”开始,是最灵活的起始选项,可搭配不同结束位置实现多种需求。
通俗理解:不往前数、不往后数,直接从当前行开始,到后面指定的结束位置。
例子(ROWS模式):ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING(帧从当前行到后面1行,共2行,适合近2期移动统计)。
(2)frame_end(帧结束位置):3个核心选项
作用:指定窗口帧到哪一行结束,必须配合 frame_start 使用,不能单独出现,同样结合ROWS模式讲解(新手优先掌握):
- CURRENT ROW:帧到“当前行”结束,是默认的结束选项(若只写frame_start,不写frame_end,就默认结束于当前行)。
通俗理解:从起始位置开始,一直到当前行结束,不包含当前行后面的行。
例子(ROWS模式):ROWS BETWEEN 1 PRECEDING AND CURRENT ROW(帧从当前行前面1行到当前行,共2行)。
- offset FOLLOWING(可简写为“M FOLLOWING”,M是数字):帧到“当前行后面第M行”结束,M必须是非负整数,和offset PRECEDING对应。
通俗理解:从起始位置开始,往后数M行,到那一行结束,比如M=1,就是当前行后面1行。
例子(ROWS模式):ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING(帧从当前行到后面1行,共2行)。
- UNBOUNDED FOLLOWING:帧到“分区的最后一行”结束(最末尾的行),常用在反向累计、全分区后半部分统计场景。
通俗理解:从起始位置开始,一直到分区的最后一行,覆盖起始位置到分区末尾的所有行。
例子(ROWS模式):ROWS BETWEEN 2 PRECEDING AND UNBOUNDED FOLLOWING(帧从当前行前面2行到分区最后一行)。
(3)关键补充:帧选项的使用规则
顺序不能乱:frame_start的位置不能在frame_end后面,比如
ROWS BETWEEN CURRENT ROW AND 2 PRECEDING(从当前行到前面2行)是错误的,因为前面2行在当前行之前,起始位置在结束位置后面,无法构成有效帧;特殊限制:frame_start不能用UNBOUNDED FOLLOWING(结束选项不能当起始),frame_end不能用UNBOUNDED PRECEDING(起始选项不能当结束);
简化写法:若frame_start是UNBOUNDED PRECEDING、frame_end是CURRENT ROW,可简写为
ROWS UNBOUNDED PRECEDING(和默认帧规则一致);若frame_start是N PRECEDING、frame_end是CURRENT ROW,可简写为ROWS N PRECEDING。
简单记2个默认规则(结合上面选项,更易理解):
如果写了
Order By(排序),默认窗口帧是“从分组开头到当前行,包括和当前行值相同的行”(等价于RANGE UNBOUNDED PRECEDING,本质是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),比如按工资排序,当前行工资5000,帧里就包含所有工资≤5000的行,直到当前行;如果没写
Order By,默认窗口帧就是整个分区(等价于RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING),比如整个部门的所有员工。
三、窗口函数的详细语法
窗口函数的语法很固定,核心就一个OVER子句——所有窗口函数,后面都要跟OVER(),括号里放分区、排序、窗口帧的规则。
1. 核心语法结构(3种常用形式)
最基础、最常用的3种写法,覆盖90%的场景:
-- 1. 无分区、无排序(全表一个窗口,不排序)
函数名(参数) OVER ()
-- 2. 有分区、无排序(按字段分组,组内不排序)
函数名(参数) OVER (PARTITION BY 分区字段)
-- 3. 有分区、有排序(按字段分组,组内按指定规则排序)
函数名(参数) OVER (PARTITION BY 分区字段 ORDER BY 排序字段 [ASC/DESC])
补充2个进阶写法(后面例子会用到):
带窗口帧:比如
OVER (PARTITION BY 字段 ORDER BY 字段 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)(窗口帧是当前行及之前2行);命名窗口:如果多个窗口函数用相同的分区/排序规则,可以先命名窗口,再引用,避免重复写,比如
WINDOW w AS (PARTITION BY depname ORDER BY salary) SELECT sum(salary) OVER w, avg(salary) OVER w ...。
2. 语法细节拆解
OVER是窗口函数的标志:没有OVER,就是普通聚合函数;有OVER,就是窗口函数;Partition By后面只能跟“字段或表达式”,不能跟查询结果的列名(比如不能写Partition By 部门,要写Partition By depname,depname是表的字段名);Order By可以指定排序方向(ASC升序、DESC降序),还能处理NULL值(NULLS FIRST让NULL排在前面,NULLS LAST让NULL排在后面);窗口函数只能写在
SELECT列表和ORDER BY里,不能写在WHERE、GROUP BY里(比如不能写WHERE avg(salary) OVER () > 5000,要实现这种需求,得用子查询)。
四、常用窗口函数说明(每个都配简单例子,一看就会)
窗口函数主要分2类:专用窗口函数(专门用于排序、取前后行)、聚合窗口函数(用普通聚合函数充当窗口函数,比如sum、avg)。
咱们只讲新手最常用的,不搞冷门函数,每个函数配1句通俗解释+1行简单SQL,结合前面的empsalary表(员工表:depname部门、empno员工号、salary工资)。
1. 专用窗口函数(重点记前3个)
| 函数名 | 通俗说明 | 核心用法示例(结合empsalary表) |
|---|---|---|
| row_number() | 给每个分区内的行分配连续序号,不重复(哪怕值相同,序号也不一样) | row_number() OVER (PARTITION BY depname ORDER BY salary DESC)(给各部门员工按工资降序编连续序号) |
| rank() | 分区内排名,值相同则排名相同,会有间隙(2个第1名,下一个是第3名) | rank() OVER (PARTITION BY depname ORDER BY salary DESC)(各部门员工工资降序排名,允许排名间隙) |
| dense_rank() | 分区内排名,值相同则排名相同,无间隙(2个第1名,下一个是第2名) | dense_rank() OVER (PARTITION BY depname ORDER BY salary DESC)(各部门员工工资降序排名,无排名间隙) |
| lag(字段, 偏移量, 默认值) | 取当前行“前面第N行”的指定字段值,无对应行返回默认值(默认偏移量1,默认值NULL) | lag(salary, 1, 0) OVER (ORDER BY salary)(取每个员工前面1个员工的工资,无则返回0) |
| lead(字段, 偏移量, 默认值) | 取当前行“后面第N行”的指定字段值,无对应行返回默认值(与lag相反) | lead(salary, 1, 0) OVER (ORDER BY salary)(取每个员工后面1个员工的工资,无则返回0) |
| percent_rank() | 返回相对排名(百分比),公式:(当前rank值-1)/(分区总行数-1),取值0~1 | percent_rank() OVER (PARTITION BY depname ORDER BY salary DESC)(计算各部门员工工资的相对排名) |
| cume_dist() | 返回累计分布值,公式:(当前行及之前同组行数)/分区总行数,取值1/N~1(N为分区行数) | cume_dist() OVER (PARTITION BY depname ORDER BY salary DESC)(计算各部门员工工资的累计分布) |
| ntile(分组数) | 将分区内的行尽量平均分成N组,返回当前行的组号(1~N),适合按比例划分数据 | ntile(2) OVER (PARTITION BY depname ORDER BY salary DESC)(各部门员工按工资降序分成2组) |
| first_value(字段) | 返回窗口帧内第一行的指定字段值,默认帧为“分组开头到当前行” | first_value(salary) OVER (PARTITION BY depname ORDER BY salary DESC)(取各部门到当前行的最高工资) |
| last_value(字段) | 返回窗口帧内最后一行的指定字段值,默认帧为“分组开头到当前行”(默认返回当前行) | last_value(salary) OVER (PARTITION BY depname ORDER BY salary DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)(取各部门最后一行员工工资) |
| nth_value(字段, n) | 返回窗口帧内第n行的指定字段值(n从1开始),不足n行返回NULL | nth_value(salary, 3) OVER (PARTITION BY depname ORDER BY salary DESC)(取各部门工资降序后的第3名工资) |
补充说明:以上11个均为PostgreSQL内置专用窗口函数,其中row_number、rank、dense_rank、percent_rank、cume_dist、ntile属于“排名类窗口函数”,依赖ORDER BY排序;lag、lead属于“取前后行类窗口函数”,可配合排序使用;first_value、last_value、nth_value属于“取帧内特定行类窗口函数”,依赖窗口帧设置。
2. 聚合窗口函数
普通聚合函数(sum、avg、count、max、min),加上OVER子句,就变成了聚合窗口函数,核心作用是“计算当前窗口内的统计值”。
| 函数名 | 通俗说明 | 核心用法示例(结合empsalary表) |
|---|---|---|
| avg(字段) OVER (...) | 计算当前窗口(或窗口帧)内指定字段的平均值 | avg(salary) OVER (PARTITION BY depname)(计算各部门员工的平均工资) |
| sum(字段) OVER (...) | 计算当前窗口(或窗口帧)内指定字段的总和 | sum(salary) OVER (PARTITION BY depname ORDER BY salary)(计算各部门员工工资的累积和) |
| count(字段) OVER (...) | 计算当前窗口(或窗口帧)内非NULL值的行数,count(*)则统计所有行数 | count(empno) OVER (PARTITION BY depname)(统计各部门的员工人数) |
| max(字段) OVER (...) | 计算当前窗口(或窗口帧)内指定字段的最大值 | max(salary) OVER (PARTITION BY depname)(计算各部门员工的最高工资) |
| min(字段) OVER (...) | 计算当前窗口(或窗口帧)内指定字段的最小值 | min(salary) OVER (PARTITION BY depname)(计算各部门员工的最低工资) |
补充:所有普通聚合函数,只需添加OVER子句,即可作为聚合窗口函数使用,核心优势是“统计不合并行”,保留原始数据细节。
例子:计算每个员工工资和部门平均工资、部门最高工资
select depname, empno, salary, avg(salary) OVER (PARTITION BY depname) 部门平均工资, max(salary) OVER (PARTITION BY depname) 部门最高工资 from empsalary;
五、窗口函数的执行原理(浅显易懂,不用深钻)
新手不用搞懂底层源码,只要记住“窗口函数的执行顺序”,就能避开80%的坑,理解为什么有些写法可行、有些不可行。
查询的执行顺序(简化版,重点记窗口函数的位置):
FROM/WHERE(取数据、过滤数据) → GROUP BY(分组合并行) → HAVING(过滤分组) → 窗口函数(计算统计值,不合并行) → SELECT(显示结果) → ORDER BY(最终排序)
从这个顺序能看出2个关键:
窗口函数在GROUP BY之后执行,所以如果先分组合并了行,窗口函数只能看到分组后的行(比如先按部门分组算平均工资,再用窗口函数,就只能拿到每个部门的平均工资,看不到单个员工);
窗口函数在SELECT之前执行,所以SELECT里可以用窗口函数的结果,但WHERE里不能(因为WHERE执行时,窗口函数还没计算出结果)。
举个坑例:想查“工资高于部门平均工资的员工”,不能写select * from empsalary where salary > avg(salary) OVER (PARTITION BY depname);,因为WHERE比窗口函数先执行,此时avg(salary)还没计算出来。
正确写法:用子查询,先算出部门平均工资,再过滤(后面举例会详细讲)。
六、由浅入深举例说明(从最简单到稍复杂,可直接复制运行)
所有例子都用同一个测试表empsalary,先创建表并插入数据(新手可以跟着执行,熟悉数据):
-- 创建员工工资表
CREATE TABLE empsalary (
depname varchar(20), -- 部门名称
empno int, -- 员工编号
salary int -- 工资
);
-- 插入测试数据
INSERT INTO empsalary VALUES
('develop', 11, 5200),
('develop', 7, 4200),
('develop', 9, 4500),
('develop', 8, 6000),
('develop', 10, 5200),
('personnel', 5, 3500),
('personnel', 2, 3900),
('sales', 3, 4800),
('sales', 1, 5000),
('sales', 4, 4800);
例子1:最简单的窗口函数(无分区、无排序)
需求:查询所有员工的工资,以及全公司的平均工资(所有员工一个窗口)。
select depname, empno, salary,
avg(salary) OVER () 全公司平均工资
from empsalary;
执行结果(简化):
执行结果(简化):
| depname | empno | salary | 全公司平均工资 |
|---|---|---|---|
| develop | 11 | 5200 | 4710.0000000000000000 |
| develop | 7 | 4200 | 4710.0000000000000000 |
| ... | ... | ... | 4710.0000000000000000 |
(所有行的“全公司平均工资”均为4710,保留所有原始员工信息)
解释:没有Partition By,所有员工是一个窗口,avg(salary) OVER ()计算全公司平均工资,每一行都显示这个值,保留所有原始员工信息。
例子2:带分区(按部门分组,最常用场景)
需求:查询每个员工的工资,以及他所在部门的平均工资、最高工资(按部门分区,只计算本部门的统计值)。
select depname, empno, salary,
avg(salary) OVER (PARTITION BY depname) 部门平均工资,
max(salary) OVER (PARTITION BY depname) 部门最高工资
from empsalary;
执行结果(简化):
执行结果(简化):
| depname | empno | salary | 部门平均工资 | 部门最高工资 |
|---|---|---|---|---|
| develop | 11 | 5200 | 5020.0000 | 6000 |
| develop | 7 | 4200 | 5020.0000 | 6000 |
| personnel | 5 | 3500 | 3700.0000 | 3900 |
| personnel | 2 | 3900 | 3700.0000 | 3900 |
解释:按depname(部门)分区,每个部门是一个窗口,研发部的窗口只包含研发部员工,所以部门平均工资只有研发部的5020,不会和人事部、销售部混淆。
例子3:带分区+排序(排名场景)
需求:给每个部门的员工按工资降序排名,工资相同的员工,排名相同且无间隙(用dense_rank)。
select depname, empno, salary,
dense_rank() OVER (PARTITION BY depname ORDER BY salary DESC) 部门工资排名
from empsalary;
执行结果(关键部分):
执行结果(关键部分):
| depname | empno | salary | 部门工资排名 |
|---|---|---|---|
| develop | 8 | 6000 | 1 |
| develop | 11 | 5200 | 2 |
| develop | 10 | 5200 | 2 |
| develop | 9 | 4500 | 3 |
| develop | 7 | 4200 | 4 |
解释:按部门分区(每个部门单独排名),按工资降序排序,工资相同(5200)的两个员工,排名都是2,下一个员工排名是3(无间隙),这就是dense_rank的作用。
例子4:带子查询(解决“过滤窗口函数结果”的坑)
需求:查询“工资高于本部门平均工资”的员工信息(前面说过,WHERE里不能直接用窗口函数,所以用子查询)。
-- 子查询:先算出每个员工的部门平均工资,命名为dep_avg_sal
-- 外层查询:过滤出salary > dep_avg_sal的员工
select * from (
select depname, empno, salary,
avg(salary) OVER (PARTITION BY depname) dep_avg_sal
from empsalary
) as temp -- 子查询必须取别名(temp是临时别名)
where salary > dep_avg_sal;
执行结果:
执行结果:
| depname | empno | salary | dep_avg_sal |
|---|---|---|---|
| develop | 8 | 6000 | 5020.0000000000000000 |
| personnel | 2 | 3900 | 3700.0000000000000000 |
| sales | 1 | 5000 | 4866.6666666666666667 |
解释:子查询先计算出每个员工的部门平均工资,外层查询再根据这个结果过滤,就能拿到工资高于部门平均的员工,完美避开WHERE不能用窗口函数的坑。
七、重点案例:移动平均值和累积求和(实战高频)
移动平均值和累积求和,是窗口函数最常用的两个实战场景(比如销量分析、业绩统计),咱们单独拿出来详细讲,用一个更贴近实战的“商品销量表”举例,新手能直接套用。
先创建销量表并插入数据(按月统计商品销量):
-- 创建商品销量表
CREATE TABLE product_sales (
product_id varchar(10), -- 商品ID
sale_month date, -- 销售月份(格式:YYYY-MM-DD)
sales int -- 当月销量
);
-- 插入测试数据(2026年1-10月,A、B两种商品的销量)
INSERT INTO product_sales VALUES
('A001', '2026-01-01', 100),
('A001', '2026-02-01', 120),
('A001', '2026-03-01', 150),
('A001', '2026-04-01', 130),
('A001', '2026-05-01', 160),
('A001', '2026-06-01', 180),
('A001', '2026-07-01', 170),
('A001', '2026-08-01', 190),
('A001', '2026-09-01', 200),
('A001', '2026-10-01', 220),
('B001', '2026-01-01', 80),
('B001', '2026-02-01', 90),
('B001', '2026-03-01', 110),
('B001', '2026-04-01', 100),
('B001', '2026-05-01', 120);
案例1:移动平均值(实战场景:平滑销量波动,看趋势)
什么是移动平均值?比如“近3个月移动平均销量”,就是每个月的销量,加上前2个月的销量,求平均值——能过滤掉单月销量的波动,更清晰看到销量趋势(比如单月销量突然下降,但移动平均还是平稳的,说明不是整体趋势下滑)。
需求:计算每种商品的“近3个月移动平均销量”(窗口帧:当前月份及之前2个月,按月份升序排序)。
select product_id, sale_month, sales,
-- 移动平均:avg(sales) 窗口:按商品分区、按月份升序,窗口帧是当前行及之前2行
avg(sales) OVER (
PARTITION BY product_id
ORDER BY sale_month
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW -- 关键:窗口帧设置
) as 近3个月移动平均销量
from product_sales;
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW:窗口帧设置,意思是“当前行及之前2行”(总共3行,即近3个月);如果不写这句,默认的窗口帧是“从分组开头到当前行”(等价于
ROWS UNBOUNDED PRECEDING),会变成“累积平均”,不是“移动平均”——这是新手最容易踩的坑!
执行结果(A001商品部分):
执行结果(A001商品部分):
| product_id | sale_month | sales | 近3个月移动平均销量 | 说明 |
|---|---|---|---|---|
| A001 | 2026-01-01 | 100 | 100.0000000000000000 | 只有1个月,平均就是自身 |
| A001 | 2026-02-01 | 120 | 110.0000000000000000 | 1月+2月,平均(100+120)/2=110 |
| A001 | 2026-03-01 | 150 | 123.3333333333333333 | 1+2+3月,平均≈123.33 |
| A001 | 2026-04-01 | 130 | 133.3333333333333333 | 2+3+4月,平均≈133.33 |
| A001 | 2026-05-01 | 160 | 146.6666666666666667 | 3+4+5月,平均≈146.67 |
实战解读:从移动平均销量能看出,A001商品的销量整体呈上升趋势,虽然4月销量(130)比3月(150)下降,但移动平均还是上升的,说明只是单月波动,不是趋势下滑。
案例2:累积求和(实战场景:统计累计业绩、累计销量)
什么是累积求和?比如“截至当月的累计销量”,就是1月销量、1+2月销量、1+2+3月销量……一直累积到当前月份,是业绩统计中最常用的需求。
需求:计算每种商品“截至当月的累计销量”(按月份升序,累积到当前月)。
select product_id, sale_month, sales,
-- 累积求和:sum(sales) 窗口:按商品分区、按月份升序,默认窗口帧(从开头到当前行)
sum(sales) OVER (
PARTITION BY product_id
ORDER BY sale_month
) as 截至当月累计销量
from product_sales;
关键语法解释:
累积求和不需要特意设置窗口帧,用默认帧即可——因为写了
ORDER BY sale_month,默认帧是“从分组开头到当前行”(等价于ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),正好符合“累积”的需求;如果想显式写窗口帧,也可以写成
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(UNBOUNDED PRECEDING表示“分组开头”),和默认效果完全一致。
执行结果(A001商品部分):
执行结果(A001商品部分):
| product_id | sale_month | sales | 截至当月累计销量 | 说明 |
|---|---|---|---|---|
| A001 | 2026-01-01 | 100 | 100 | 1月累计:100 |
| A001 | 2026-02-01 | 120 | 220 | 1+2月累计:220 |
| A001 | 2026-03-01 | 150 | 370 | 1+2+3月累计:370 |
| A001 | 2026-04-01 | 130 | 500 | 累计:370+130=500 |
| A001 | 2026-10-01 | 220 | 1620 | 1-10月累计:所有月份销量相加 |
实战解读:截至10月份,A001商品的累计销量是1620,通过累计求和,能快速看出商品的整体销售进度,比如对比目标销量(比如2000),就能知道完成了多少。
其实窗口函数一点都不复杂,多练几遍前面的例子,尤其是移动平均和累积求和,很快就能熟练上手。如果觉得例子不够,或者有具体的业务场景想套用,也可以根据自己的需求调整SQL~



