
引言:为什么我们需要给大模型“开小灶”?
嗨,我是你们的AI伙伴狸猫算君~今天问大家一个问题:想象一下,你请了一位百科全书式的天才助理——他上知天文下知地理,但就是不懂你们公司的报销流程。每次你问“差旅费怎么报销”,他都开始滔滔不绝讲起金融史。
这就是通用大语言模型(LLM)的现状:它们很聪明,但不够“专业”。
微调(Fine-tuning) ,就是给这位通用天才上的一堂“岗前培训课”。通过精心准备的教学资料(你的数据)和科学的培训方法(参数设置),让大模型在保留原有广博知识的同时,精准掌握你的特定需求。
哪些场景必须微调?
- 领域专业化:让法律大模型懂《民法典》,医疗大模型会看化验单
- 风格对齐:让AI写出你公司的行文风格,或模仿某位作家的笔调
- 任务定制:专精于客服对话、代码生成、报告分析等具体任务
- 知识更新:注入最新的行业动态或公司内部知识库
但为什么很多人尝试微调后,得到的却是“胡说八道”的模型?接下来,我们就从最常见的失败案例说起。
技术原理:拆解大模型如何“学习”
核心概念一:模型微调在做什么?
把大模型想象成一个已经读了万亿字书籍的“超级大脑”。微调不是清空它的大脑重新学习(那代价太大),而是有侧重地强化训练。
关键比喻:通用大模型 = 医学院毕业生,你的数据 = 专科培训,微调后模型 = 专科医生
核心概念二:参数更新——模型的“记忆调整”
大模型由数百亿个“参数”(可以理解为神经元的连接强度)组成。预训练阶段,这些参数已经学会了通用的语言规律。
微调时,我们只有选择地更新一部分参数,让模型在特定任务上表现更好,同时不破坏原有的通用知识。
两种主流微调方式:
- 全量微调:更新所有参数(效果好但成本高,适合资源充足时)
- 高效微调(如LoRA) :只更新额外添加的小型适配器(成本低、效率高,当前主流)
核心概念三:损失函数——模型的“错题本”
训练过程中,模型会不断预测、对比标准答案、计算“损失值”(预测错误的程度),然后反向调整参数以减少错误。
你的任务就是:准备高质量的“考题”(数据) 和 设置合理的“评分标准”(训练参数) 。
实践步骤:手把手完成第一次微调
第一步:数据准备——七分靠数据,三分靠调参
1.1 定义清晰的任务格式(Schema)
常见错误:指令模糊,让模型猜你想要什么。
json
// ❌ 模糊指令(模型可能回答任何关于苹果的内容)
{
"instruction": "介绍一下苹果",
"output": "苹果是一种常见的水果..."
}
// ✅ 结构化指令(明确告诉模型格式和内容)
{
"instruction": "请以JSON格式返回以下水果的营养成分,包含卡路里、维生素和适用人群",
"input": "苹果",
"output": {
"calories": "52千卡/100克",
"vitamins": ["维生素C", "维生素K", "维生素B6"],
"suitable_for": ["减肥人群", "一般健康人群"]
}
}
实操建议:先人工标注20-50条样例,确保格式统一,再批量处理。
1.2 数据清洗与去重
脏数据是微调失败的头号杀手。一份包含10%噪声的数据,足以让模型性能下降30%以上。
基础清洗代码示例:
python
import re
def clean_text(text):
"""基础文本清洗函数"""
# 移除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 移除URL链接
text = re.sub(r'https?://\S+|www.\S+', '', text)
# 移除过多空白字符
text = re.sub(r'\s+', ' ', text)
# 移除特殊字符(根据任务保留必要符号)
text = re.sub(r'[^\w\s.,!?;:()-'"]', '', text)
return text.strip()
# 应用到你的数据集
cleaned_data = [clean_text(item) for item in raw_data]
语义去重进阶:如果数据量较大,需进行语义相似度去重,避免模型过拟合到重复内容。
1.3 划分训练集与验证集
黄金法则:永远不要用测试集参与训练!
python
from sklearn.model_selection import train_test_split
# 简单随机划分(数据分布均匀时使用)
train_data, val_data = train_test_split(
cleaned_data,
test_size=0.1, # 通常10%作为验证集
random_state=42 # 固定随机种子,确保可复现
)
# 分层抽样(当数据类别不平衡时使用)
train_data, val_data = train_test_split(
cleaned_data,
test_size=0.1,
stratify=labels, # 按标签分层,保持分布一致
random_state=42
)
数据量参考:
- 简单任务(风格模仿):500-1000条优质数据
- 中等任务(领域适配):2000-5000条
- 复杂任务(推理能力):10000条以上
在实际操作中,数据准备往往是最耗时的一环。如果你刚开始接触大模型微调,我强烈建议先使用可视化工具快速验证想法。比如LLaMA-Factory Online这样的在线微调平台,它提供了:
- 拖拽式数据上传和预处理
- 自动化的数据质量检查
- 零代码的微调配置界面
特别适合初学者快速完成“数据准备→微调训练→效果评估”的全流程验证,让你在几小时内就看到自己数据的效果,而不是在本地环境折腾几天。
第二步:参数设置——找到“刚刚好”的训练节奏
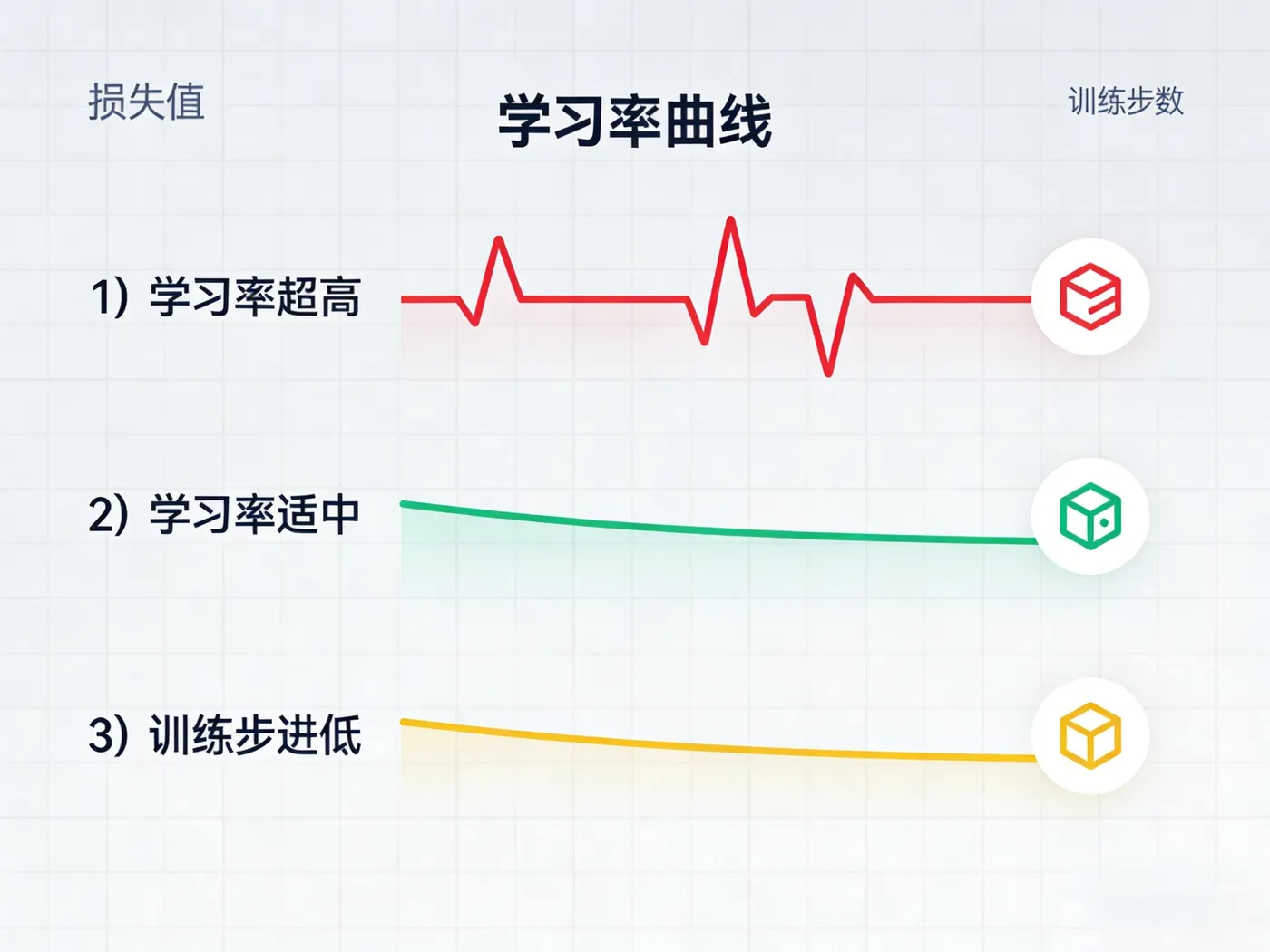
2.1 学习率(Learning Rate):最关键的超参数
学习率决定了模型“调整记忆”的幅度。太大容易“学偏”,太小学习效率低下。
不同规模模型的推荐初始学习率:
| 模型规模 | 推荐初始学习率 | 说明 |
|---|---|---|
| 7B参数模型 | 1e-5 到 3e-5 | 中小模型相对稳定 |
| 13B参数模型 | 5e-6 到 2e-5 | 需要更谨慎的调整 |
| 70B+大模型 | 1e-6 到 5e-6 | 非常敏感,小步调整 |
学习率调度策略:
python
from transformers import TrainingArguments
training_args = TrainingArguments(
learning_rate=2e-5, # 初始学习率
lr_scheduler_type="cosine", # 余弦退火:先快后慢
warmup_ratio=0.1, # 前10%的训练步数作为预热期
# 预热期学习率从0线性增长到初始值,避免初期震荡
)
2.2 批处理大小(Batch Size)与梯度累积
核心公式:有效批大小 = 单卡批大小 × GPU数量 × 梯度累积步数
python
training_args = TrainingArguments(
per_device_train_batch_size=4, # 单张GPU一次处理的样本数
gradient_accumulation_steps=8, # 累积8步再更新参数
# 有效批大小 = 4 × 1 × 8 = 32
)
显存不足时的解决方案:
- 优先增加
gradient_accumulation_steps(虚拟增大批大小) - 启用梯度检查点(用时间换空间)
- 使用LoRA等高效微调方法
2.3 LoRA微调配置(推荐初学者使用)
LoRA(Low-Rank Adaptation)是目前最高效的微调方法之一,只需训练原模型0.1%-1%的参数。
python
from peft import LoraConfig, get_peft_model
# LoRA配置
lora_config = LoraConfig(
r=8, # 秩(Rank),4-16之间,越大能力越强但参数越多
lora_alpha=16, # 缩放因子,通常设为2*r
target_modules=["q_proj", "v_proj"], # 针对注意力层的查询和值投影
lora_dropout=0.05, # 防止过拟合的dropout
bias="none", # 不训练偏置项
task_type="CAUSAL_LM" # 因果语言模型任务
)
# 应用LoRA到原模型
model = get_peft_model(original_model, lora_config)
print(f"可训练参数比例: {model.print_trainable_parameters()}")
LoRA的优势:
- 显存消耗降低60-80%
- 训练速度提升2-3倍
- 多个任务可共享基础模型,只需保存小型的适配器
第三步:开始训练与监控
3.1 使用Hugging Face Transformers训练
python
from transformers import Trainer
# 初始化训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
# 开始训练
trainer.train()
# 保存模型
model.save_pretrained("./my_finetuned_model")
3.2 实时监控训练过程
训练不是“设置好就等结果”,需要实时监控关键指标:
必须监控的指标:
- 训练损失(Train Loss) :应平稳下降,最终趋于平缓
- 验证损失(Val Loss) :应同步下降,若开始上升说明过拟合
- 学习率:按预定调度变化
- GPU利用率:应保持在70%以上
使用Weights & Biases可视化监控:
python
import wandb
# 初始化wandb
wandb.init(project="my-llm-finetune")
# 在训练循环中记录
for step, batch in enumerate(train_dataloader):
# 训练步骤...
loss = outputs.loss
# 记录指标
wandb.log({
"train_loss": loss.item(),
"learning_rate": scheduler.get_last_lr()[0],
"step": step
})
效果评估:如何判断微调是否成功?
定量评估(客观指标)
任务特定指标:
- 分类任务:准确率、F1分数
- 生成任务:BLEU、ROUGE、BERTScore
- 代码生成:执行通过率、CodeBLEU
通用语言模型指标:
- 困惑度(Perplexity):越低越好
- 生成多样性:避免重复模板化输出
定性评估(人工检查)
创建一个小型测试集(50-100条),人工评估:
- 相关性:回答是否切题?
- 准确性:信息是否正确?
- 连贯性:逻辑是否通顺?
- 风格符合度:是否符合预期风格?
A/B测试(生产环境)
将微调模型与原始模型对比:
python
def ab_test(original_model, finetuned_model, test_questions):
results = []
for question in test_questions:
orig_answer = original_model.generate(question)
fine_answer = finetuned_model.generate(question)
# 人工或自动评分
score = evaluate_relevance(fine_answer, orig_answer)
results.append(score)
return np.mean(results) # 平均改善程度
总结与展望
微调的核心原则回顾
- 数据质量 > 数据数量:1000条干净数据胜过10000条脏数据
- 先简单后复杂:先用LoRA小规模试错,再考虑全量微调
- 监控胜过猜测:实时监控损失曲线,及时调整策略
- 迭代优于完美:接受第一版不完美,建立持续改进流程
常见问题快速排查表
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 训练损失震荡不降 | 学习率太大 | 降低学习率50% |
| 验证损失上升 | 过拟合 | 早停、增加dropout、增加数据 |
| 输出胡言乱语 | 数据噪声大 | 重新清洗数据,检查格式 |
| GPU内存不足 | 批大小太大 | 减小批大小,启用梯度累积 |
| 训练速度慢 | 序列过长 | 截断到必要长度,启用FlashAttention |
未来趋势展望
- 更高效的微调技术:QLoRA、DoRA等新技术将进一步降低微调门槛
- 自动化微调流程:AutoML for LLM将让超参数搜索自动化
- 多模态微调:统一框架处理文本、图像、音频的联合微调
- 联邦学习微调:在保护隐私的前提下,利用多方数据微调模型
最后的建议
大模型微调不是一门“玄学”,而是一项可重复、可优化、可工程化的技术。最重要的不是一次就调出完美模型,而是建立一个可以持续迭代的流程。记住:每一个今天看似“不完美”的微调尝试,都是在为你未来构建强大AI应用积累经验。



