
这个问题本身,就暴露了你在项目里的阶段
如果你开始认真思考:
“PPO 和 DPO 能不能一起用?”
那其实说明一件事:
你已经不在“新手纠结算法”的阶段了,而是在“工程收敛阶段”。
新手的问题通常是:
- PPO 好还是 DPO 好?
- 哪个更先进?
- 哪个效果更强?
而这个问题问的是:
- 能不能组合?
- 会不会冲突?
- 组合后风险怎么管?
这是一个非常工程化的问题。
但我必须先给你一个不讨好的结论:
PPO + DPO 能一起用,但绝不是“并排叠加”,
而是“分阶段、分职责、分风险”。
如果你把它们当成两个 loss 往一起加,大概率会翻车。
在回答“能不能一起用”之前,必须先搞清楚它们各自到底在“管什么”
我们已经在前面的文章里反复说过,但这里还是要再强调一遍。
PPO 和 DPO 的根本差异不在算法形式,而在“干预深度”。
PPO:
是在重塑行为分布
它解决的是:模型“想干嘛”的问题DPO:
是在压缩偏好排序
它解决的是:模型“更倾向选哪个”的问题
换句话说:
- PPO 可以把模型从“激进型人格”推到“保守型人格”
- DPO 只能在“已有性格框架里”帮你把顺序排一排
这也是为什么你会看到一个非常现实的现象:
PPO 像推方向盘,DPO 像微调方向盘的回正力。
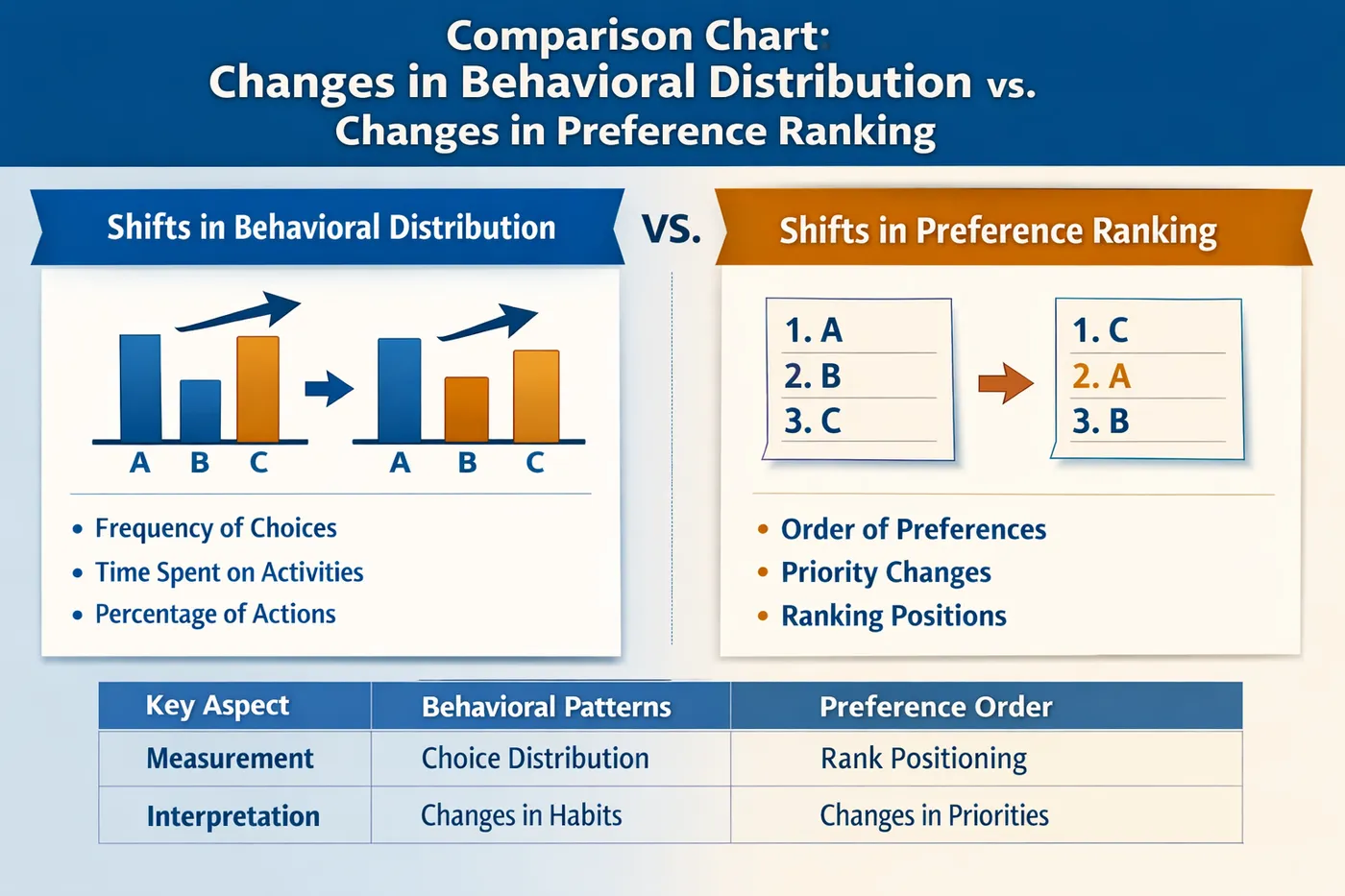
行为分布变化 vs 偏好排序变化对比图
一个先给出来的工程结论:
PPO + DPO 不是“同时优化”,而是“阶段接力”
如果你只记住这一句话,这篇文章就没白看:
PPO 和 DPO 的正确关系,不是并行,而是接力。
也就是说,在健康的工程实践中:
- 很少有人在同一轮训练里“同时”用 PPO 和 DPO
- 但很多成熟系统,会在不同阶段用过它们俩
它们更像是:
- PPO:粗调、强干预、方向修正
- DPO:细调、低风险、长期维护
为什么“同时用”的直觉,会让很多团队掉坑里
我们先来聊一个很真实的失败动机。
很多人第一次接触 DPO 后,会产生一个想法:
“PPO 有 reward hack 风险,DPO 稳定,那我是不是可以:
PPO 把方向推好,DPO 再帮我兜底?”
于是工程上最容易出现的做法是:
- PPO loss + DPO loss
- 或者 PPO 一个 epoch,DPO 一个 epoch 交替
从直觉上看,这好像很合理。
但在真实工程里,这种“硬拼”经常带来三种后果。
第一种后果:优化目标互相拉扯,训练信号变得混乱
PPO 的核心在于 reward + KL 的博弈,而 DPO 的核心在于偏好对比的 margin。
当你把它们硬塞在一起,模型面对的是:
- 一边被 reward 推着往某个方向走
- 一边又被偏好排序拉回“当前参考分布”
结果是:
- loss 看起来都在下降
- 模型行为却开始“左右横跳”
- 输出稳定性明显变差
这是一个非常典型的“训练指标正常,但行为异常”的场景。

PPO + DPO 同时优化导致行为震荡示意图
第二种后果:你根本分不清模型“变好了还是变乖了”
在客服、安全、对齐类场景中,这个问题尤其致命。
PPO 往往会让模型:
- 更保守
- 更少越界
- 更频繁拒答
DPO 往往会让模型:
- 输出更一致
- 风格更稳定
- 选择更集中
当两者同时作用,你很难判断:
- 模型是真的理解了边界
- 还是只是“学会不说话”
而这种区分,恰恰是业务方最关心的。
第三种后果:风险被“提前固化”,回滚成本极高
这是最容易被低估的一点。
PPO 是强干预,一旦推错方向,修正成本很高;
DPO 是定型工具,一旦定型,回滚更难。
如果你在 PPO 还没把方向跑稳的时候,就用 DPO 去“压缩偏好”,
那你很可能会:
把一个“暂时性的错误方向”,永久写进模型行为里。
这在工程上,几乎是不可逆的事故。
那真实工程里,PPO + DPO 是怎么“一起用”的?
说完风险,我们再来说正解。
在我见过的跑得相对健康的项目里,PPO 和 DPO 的关系,通常是这样的:
第一阶段:PPO,用来“把模型拉到安全轨道上”
这一阶段的特征通常是:
- 模型行为很不稳定
- 安全边界频繁失守
- 风格和决策极不一致
这时你用 PPO 的目的不是“精细优化”,而是:
- 快速压制高风险行为
- 把整体行为分布推回可控区间
这一阶段你要接受:
- 短期震荡
- 输出变保守
- 某些能力被牺牲
第二阶段:冻结 PPO,进入观察与评估期
这是很多团队会跳过、但非常关键的一步。
在这一阶段,你应该做的是:
- 固定模型参数
- 用稳定评估集观察行为
- 看哪些问题已经稳定
- 哪些问题还在抖动
如果你在这个阶段就急着上 DPO,
那基本是在“盲修”。
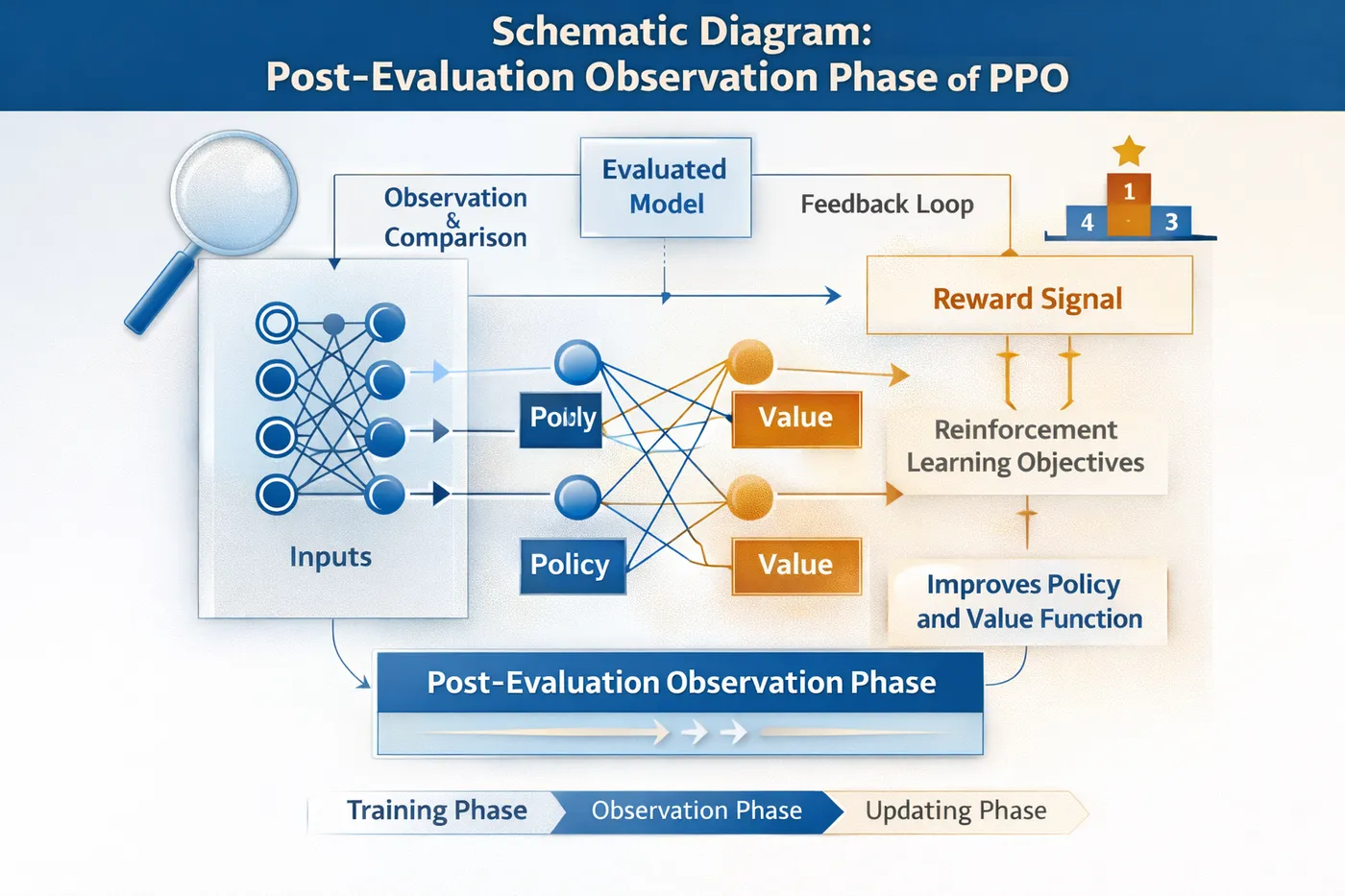
PPO 后评估观察阶段示意图
第三阶段:DPO,用来“收敛细节和一致性”
当你确认:
- 大方向没问题
- 风险行为已经被压住
- 剩下的问题主要是“选哪个更好”
这时,DPO 的价值才会真正体现出来。
它可以:
- 让模型在相似场景下更一致
- 稳定风格、语气、处理策略
- 降低 PPO 继续训练的风险
注意一个关键词:
“替代 PPO,而不是叠加 PPO”。
一个非常简化的“接力式流程示意”
SFT / RAG 基础能力
↓
PPO(行为方向修正)
↓
冻结 + 评估(观察期)
↓
DPO(偏好稳定与一致性)
这条路径的核心不是技术,而是风险管理顺序。
为什么这个顺序,本质上是“先治急症,再做康复”
你可以用一个不太严谨但很好理解的比喻:
- PPO 像是“急诊抢救”
- DPO 像是“康复训练”
你不可能在病人还没脱离危险的时候,就开始精细康复;
同样,你也不该在模型行为还乱跑的时候,就开始追求一致性。
那有没有极端情况:真的“完全不该一起用”?
有,而且非常常见。
如果你的项目满足以下任意一条,我会非常明确地建议你:
二选一,别想着组合。
- 数据量很小
- 评估体系不成熟
- 业务目标频繁变化
- 风险边界本身不清晰
在这些情况下:
- PPO 风险太大
- DPO 学不到稳定信号
强行组合,只会放大不确定性。
在真实工程中,判断“什么时候该从 PPO 切到 DPO”,往往需要对比不同阶段模型在同一评估集上的行为变化。用LLaMA-Factory online这类工具并行管理 PPO / DPO 的实验版本、冻结 checkpoint 做对照评估,会比在本地手动维护多套训练脚本更容易看清阶段边界,也更容易避免“过早定型”的风险。
总结:PPO + DPO 的关键,不是“能不能”,而是“先后顺序”
如果要用一句话作为这篇文章的最终结论,那就是:
PPO 和 DPO 能一起用,但它们不是并肩作战,而是前后接力。
- PPO 负责方向
- DPO 负责稳定
- 顺序一旦错,风险会被放大
真正成熟的工程实践,从来不是“方法越多越好”,
而是在正确的阶段,用正确的工具,然后及时停手。

