
一、DNAscope Hybrid介绍
短读长测序技术在解析基因组“盲区”(如难以比对区域)及结构变异方面存在着局限性。尽管长读长测序凭借超过15kb的读段显著改善了SV检测,但仍面临高错误率(尤其是同聚物区域的插入/缺失,Indel)和高成本的挑战。
Sentieon开发了创新的混合分析流程DNAscope Hybrid,有效地整合了短读长和长读长测序技术的优势,能生成比单独使用一种技术更准确的变异检测结果,从而实现更全面和准确的基因组分析。
该流程通过组合分析可将典型的长读长覆盖度需求降低2-3倍,同时提高样本结果的准确性和全面性。DNAscope Hybrid不仅能够全面检测SNP、Indel、SV和CNV,还能在保持高准确度的同时降低成本。
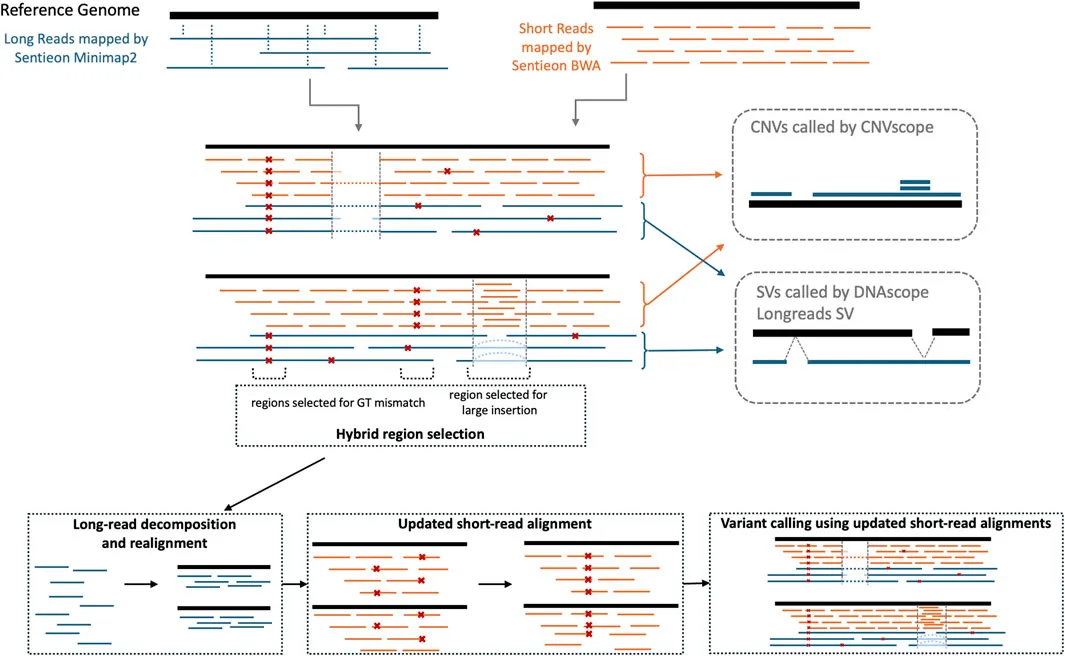
图1 DNAscope Hybrid变异检测流程的处理步骤概述
相比于HELLO、blend-seq和Variantyx等现有的混合分析流程,DNAscope Hybrid的独特优势在于:利用长读长单体型指导短读段重新比对,实现深度融合分析;通过单体型解析和并行化处理优化计算效率,完美适配临床应用场景;
本篇将重点介绍DNAscope Hybrid的基本操作流程,下篇将深入解析DNAscope Hybrid具体的性能评测指标。
二、系统要求
1. 软件许可说明
DNAscope Hybrid流程使用Sentieon软件包实现,需要有效的许可证。请联系info@sentieon.com获取Sentieon软件和评估许可。
2. 使用DNAscope Hybrid的前提
- 需要Sentieon软件包202503.01或更高版本
- 需要Python 3.8或更高版本
- 需要bcftools 1.10或更高版本
- 需要bedtools工具包
- 需要MultiQC 1.18或更高版本,用于生成指标报告
- 需要samtools 1.16或更高版本
- 需要mosdepth 0.2.6或更高版本,用于长读段数据的覆盖度指标收集
Sentieon、python、bcftools、bedtools、samtools、multiqc和mosdepth这些可执行文件将通过用户的PATH环境变量进行访问。
三、输入数据要求
1. 参考基因组
DNAscope LongRead将相对于FASTA格式的高质量参考基因组检测样本中存在的变异。除了参考基因组文件外,还需要samtools fasta索引文件(.fai)。短读段比对还需要bwa索引文件。
我们建议比对到不含替代片段的参考基因组。如果基因组中存在替代片段且流程正在执行短读段比对,请同时提供".alt"文件以激活bwa中的alt感知比对。
2. 支持输入数据格式(需要同时提供短读段和长读段数据)
- 未比对的短读段数据(gzipped FASTQ格式)
- 已比对的短读段数据(BAM或CRAM格式)
- 未比对的长读段数据(uBAM或uCRAM格式)
- 已比对的长读段数据(BAM或CRAM格式)
四、使用方法
运行两个独立的命令来进行CNV检测和应用机器学习模型。输入的BAM文件应该来自已经完成比对和去重复的流程。
1. 从已比对的短读长和长读长数据进行胚系变异检测
运行单个命令从已比对的短读段和长读段数据中调用SNP、Indel、SV和CNV:
sentieon-cli dnascope-hybrid \
-r REFERENCE \
--sr_aln SR_ALN [SR_ALN ...] \
--lr_aln LR_ALN [LR_ALN ...] \
-m MODEL_BUNDLE \
[-b DIPLOID_BED] \
[-d DBSNP] \
[--dry_run] \
[--gvcf] \
[--sr_duplicate_marking MARKDUP] \
[-t NUMBER_THREADS] \
sample.vcf.gz
DNAscope Hybrid流程需要以下必备参数:
-r REFERENCE:参考FASTA文件的路径。还需要对应的fasta索引".fai"文件。--sr_aln:BAM或CRAM格式的输入短读段比对文件,支持在参数后输入多个文件。--lr_aln:BAM或CRAM格式的输入长读段比对文件,支持在参数后输入多个文件。-m MODEL_BUNDLE:模型包的路径,可以在sentieon-models仓库中找到(https://github.com/Sentieon/sentieon-models )sample.vcf.gz:SNV和indel输出VCF文件的路径,要求输出文件以".vcf.gz"后缀结尾。
DNAscope Hybrid流程接受以下可选参数:
-b DIPLOID_BED:BED文件格式的参考中限制二倍体变异调用的区间,提供此文件将限制二倍体变异调用在BED文件内的区间。-d DBSNP:用于标记已知变异的单核苷酸多态性数据库(dbSNP)的位置,VCF(.vcf)或bgzip压缩的VCF(.vcf.gz)格式。仅支持一个文件,提供此文件将用dbSNP refSNP ID号注释变异,需要VCF索引文件。--dry_run:打印流程命令,而不实际执行。--gvcf:在生成VCF的同时生成一个 gVCF格式的输出文件。--sr_duplicate_marking:设置重复序列标记模式。使用 markdup将标记重复读段。使用 rmdup 将直接移除重复读段。使用 none 将跳过重复序列标记步骤。默认设置为 markdup。-t NUMBER_THREADS:软件运行并行进程所使用的计算线程数。若省略,流程将使用服务器拥有的所有线程。-h:打印命令行帮助并退出。
2. 从未比对的短读长和长读长数据进行胚系变异检测
运行单个命令从未比对的短读段和长读段数据中调用SNP、Indel、SV和CNV:
sentieon-cli dnascope-hybrid \
-r REFERENCE \
--sr_r1_fastq SR_R1_FQ [SR_R1_FQ ...] \
--sr_r2_fastq SR_R2_FQ [SR_R2_FQ ...] \
--sr_readgroups SR_READGROUP [SR_READGROUP ...] \
--lr_aln LR_ALN [LR_ALN ...] \
--lr_align_input \
-m MODEL_BUNDLE \
[-b DIPLOID_BED] \
[--bam_format] \
[-d DBSNP] \
[--dry_run] \
[--gvcf] \
[--sr_duplicate_marking MARKDUP] \
[-t NUMBER_THREADS] \
sample.vcf.gz
DNAscope Hybrid流程需要以下必备参数:
--sr_r1_fastq:gzipped FASTQ格式的R1短读段输入数据。可以在参数后输入多个文件。--sr_r2_fastq:gzipped FASTQ格式的R2短读段输入数据。可以在参数后输入多个文件。--sr_readgroups:对应每个FASTQ的读组信息。流程将期望--sr_r1_fastq和--sr_readgroups有相同数量的参数。- 示例参数为"
@RG\tID:HG002-1\tSM:HG002\tLB:HG002-LB-1\tPL:ILLUMINA"
- 示例参数为"
--lr_aln:uBAM或uCRAM格式的长读段输入数据。可以在参数后输入多个文件。--lr_align_input:指示流程对输入的长读段进行比对。
DNAscope Hybrid流程接受以下可选参数:
--bam_format:对输出的比对文件使用BAM格式而不是默认的CRAM格式。--lr_input_ref:用于解码输入长读段文件的参考fasta。长读段uCRAM或CRAM输入时需要,可以与-r参数使用的fasta不同。
五、输出结果
1. 默认输出文件类型
- VCF格式的小变异(SNP和Indel)
- VCF格式的结构变异(SV)
- VCF格式的拷贝数变异(CNV)
- 如果输入未比对的reads,还会输出BAM或CRAM格式的比对结果。
2. 输出文件列表
DNAscope Hybrid流程输出以下文件:
sample.vcf.gz:-b DIPLOID_BED文件中定义的基因组区域的SNV和indel变异检测。sample.sv.vcf.gz:Sentieon LongReadSV工具的结构变异检测。sample.cnv.vcf.gz:Sentieon CNVscope工具的拷贝数变异检测。sample_deduped.cram:来自输入FASTQ文件的已比对、坐标排序和重复标记的短读段数据。sample_mm2_sorted_*.cram:来自输入uBAM、uCRAM、BAM或CRAM文件的已比对和坐标排序的长读段。sample_metrics:包含已分析样本的质控指标的目录。
六、故障排除
错误提示:"输入...具有不同的RG-SM标签"
当流程检测到输入文件具有(或将具有)不同的读组标签时,会出现此错误。要修复此错误,请使用--rgsm参数在变异检测过程中调整输入文件的SM标签。请注意,使用此参数时,输入文件中的所有读数都将在变异检测过程中被使用。
七、总结
DNAscope Hybrid不仅适用于全基因组测序数据分析,还支持靶向测序分析(如Twist Alliance Dark Genes Panel),展现出了高鲁棒性和多功能性,使其成为对准确性和全面性要求极严苛的临床诊断场景的理想选择。下一篇将展示与现有方法相比,DNAscope Hybrid在基准测试中所拥有的卓越性能,进一步印证Sentieon在混合数据分析领域的创新。
当前,长读长-短读长混合测序分析领域正处于高速迭代期,Sentieon团队将持续对DNAscope Hybrid进行优化,朝着更高的准确性、更强的通量和更低的成本三个维度实现突破。将与行业伙伴共同推动精准医疗的发展,助力基因组学研究和应用迈向新的高度。
Sentieon软件介绍
Sentieon为完整的纯软件基因变异检测二级分析方案,其分析流程完全忠于BWA、GATK、MuTect2、STAR、Minimap2、Fgbio、picard等金标准的数学模型。在匹配开源流程分析结果的前提下,大幅提升WGS、WES、Panel、UMI、ctDNA、RNA等测序数据的分析效率和检出精度,并匹配目前全部第二代、三代测序平台。
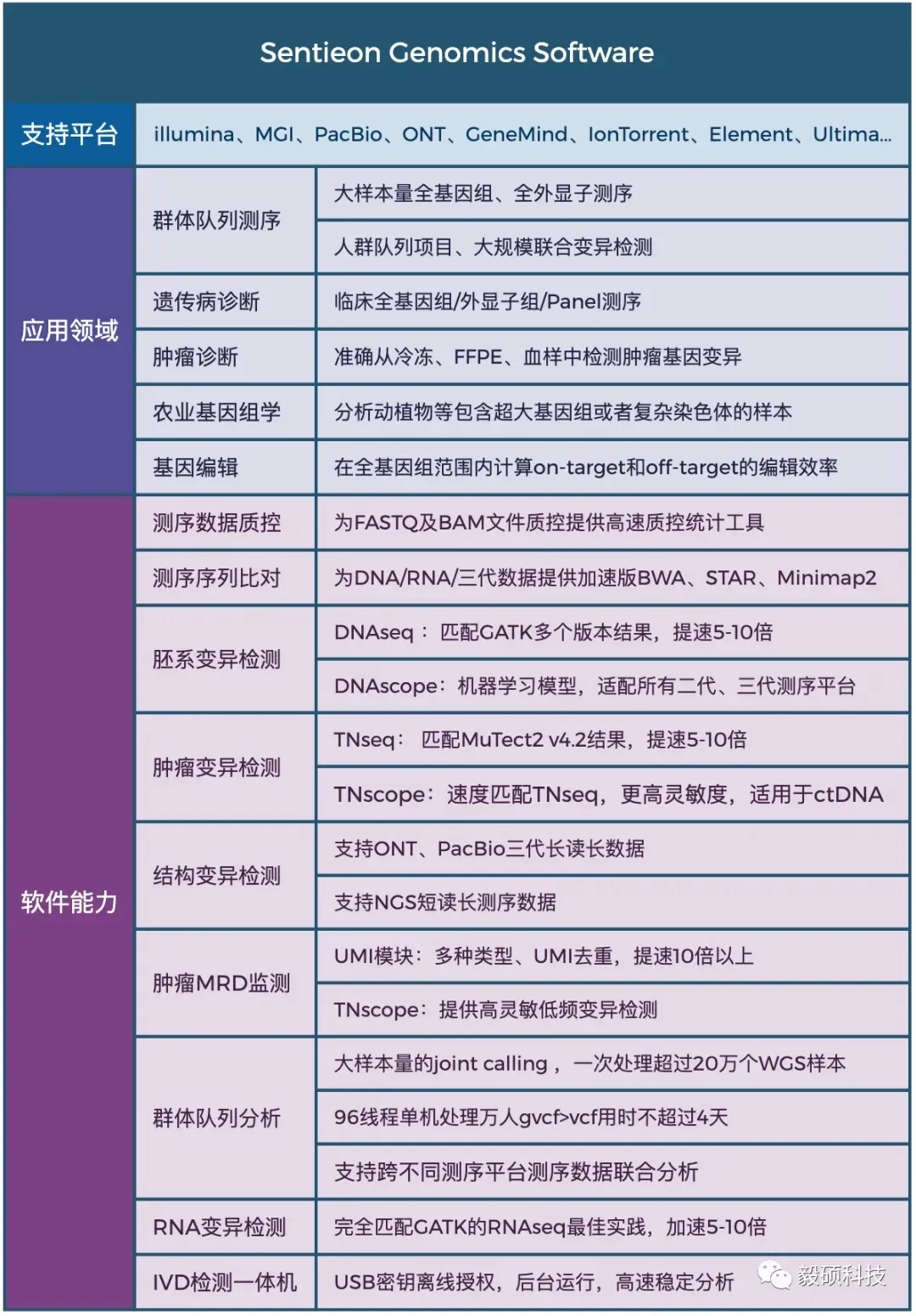
Sentieon软件团队拥有丰富的软件开发及算法优化工程经验,致力于解决生物数据分析中的速度与准确度瓶颈,为来自于分子诊断、药物研发、临床医疗、人群队列、动植物等多个领域的合作伙伴提供高效精准的软件解决方案,共同推动基因技术的发展。
截至2025年7月份,Sentieon已经在全球范围内为1860+用户提供服务,用户处理超过4980+PB数据量,被世界一级影响因子刊物如NEJM、Cell、Nature等广泛引用,引用次数超过1500篇。此外,Sentieon连续数年摘得了Precision FDA、Dream Challenges等多个权威评比的桂冠,在业内获得广泛认可。

