
引言:当大模型需要“外接硬盘”
想象一下,你有一位天赋异禀、博览群书的朋友(比如大模型GPT)。他聊天文地理头头是道,但当你问他:“我们公司上季度某产品的具体销量是多少?”或者“根据我司最新的员工手册,年假应该如何申请?”时,他很可能就懵了,甚至开始自由发挥。
为什么呢?因为大模型在训练时,学到的知识是“冻结”在参数里的,它无法实时获取训练数据之外的新信息(比如你公司的内部文档、最新的市场报告)。这种在缺乏事实依据时凭空生成内容的现象,就是我们常说的“幻觉”。
RAG(检索增强生成) 就是为了解决这个问题而生的。它的核心思想很简单:给大模型配一个“外接硬盘”(知识库)和一个“智能秘书”(检索器) 。当用户提问时,先让“秘书”去“硬盘”里查找最相关的资料,然后把资料和问题一起交给大模型,让它“基于资料”来生成答案。
这样一来,大模型的回答就不再仅依赖于它的“记忆”,而是有了可靠的事实依据。RAG已成为构建企业知识助手、智能客服、研报分析等知识密集型应用的首选架构。接下来,我们深入浅出地看看几种主流的RAG技术方案。
技术原理:三大流派,各有千秋
RAG的核心流程可以概括为:“检索 -> 增强 -> 生成”。但在这个框架下,不同的技术方案在“如何增强”上玩出了不同的花样。
1. T5-RAG:全能型“学者”
核心比喻:先备课,再讲课。
技术核心:它以Google的T5模型为生成核心。T5的特点是“万物皆可文本”,所有任务(问答、总结、翻译)都被转化成“输入文本 -> 输出文本”的形式,非常灵活。
工作流程:
- 检索:从你的知识库(如公司文档集)中找出与问题相关的文档片段。
- 拼接:把问题和检索到的文档拼接成一段新的文本,作为T5的输入。例如:“问题:我们产品的优势是什么?文档:我们的产品A采用了XX技术,具有功耗低、响应快的特点...”
- 生成:T5模型读取这段拼接后的长文本,理解上下文,然后直接生成最终的答案。
优点:通用性强,得益于T5本身强大的预训练能力,它在各种任务上都能有不错的表现,就像一个全科学霸。
缺点:计算开销大。T5模型本身参数多,处理长文本(拼接了检索文档)时更耗资源。有时对专业领域知识深度不够。
2. Fusion-in-Decoder (FiD):高效的“信息整合师”
核心比喻:边查资料边写报告。
技术核心:它创新地改变了信息融合的时机。传统RAG(如T5-RAG)是先把检索到的所有文档编码、压缩成一个整体,再生成。FiD则不然。
工作流程:
- 并行编码:将问题和每一份检索到的文档分别进行编码,得到多组向量表示,而不是混在一起。
- 解码时融合:在生成答案的每一个步骤中,生成器(解码器)会同时“查看”问题向量和所有文档向量,动态决定从哪份文档里汲取哪些信息来写下当前的词。相当于写报告时,面前同时摊开多份参考资料,眼睛快速扫视,随时取用。
优点:效率更高,信息保留更完整。因为避免了提前混合信息可能造成的损失,并能并行处理文档,所以通常速度更快,对检索信息的利用率更高。
缺点:强依赖检索质量。如果“秘书”检索的文档都不靠谱,那生成的结果也容易出问题。在完全陌生的领域,泛化能力可能稍弱。
3. 相关性感知检索增强 (RAR):精益求精的“质检员”
核心比喻:先给资料打分,再用高分资料写答案。
技术核心:它在“检索”和“增强”之间加入了一个相关性评分模块。不再是检索到多少就用多少,而是先评估一下每份资料到底跟问题有多相关。
工作流程:
- 粗检索:先检索出一批可能相关的文档。
- 精评分:用一个训练好的小型评分模型(或规则),对这批文档与问题的相关性进行精细打分、排序。
- 加权增强:只选取Top-K高分文档,或者根据分数赋予文档不同的权重,再送给生成模型。这样,生成模型就能把注意力集中在最可信的资料上。
优点:答案准确性更高。通过过滤掉无关或弱相关信息,极大减少了噪声干扰,尤其适合法律、医疗等要求精确匹配的场景。
缺点:系统更复杂。需要额外训练或设计评分模块,且对标注数据(哪些文档与哪些问题高度相关)有一定要求。
简单总结:
- T5-RAG:我全都要(通用),但吃得慢。
- FiD:多线程工作,吃得快,但食材要好。
- RAR:美食家,精心挑选最好的食材再做菜。
了解了原理,你可能摩拳擦掌想试试了。但搭建一套RAG系统,从数据准备、向量化、检索到微调生成模型,每一步都需要代码和工程经验,门槛不低。别急,现在有了更便捷的路径。
实践步骤:四步搭建你的首个RAG系统
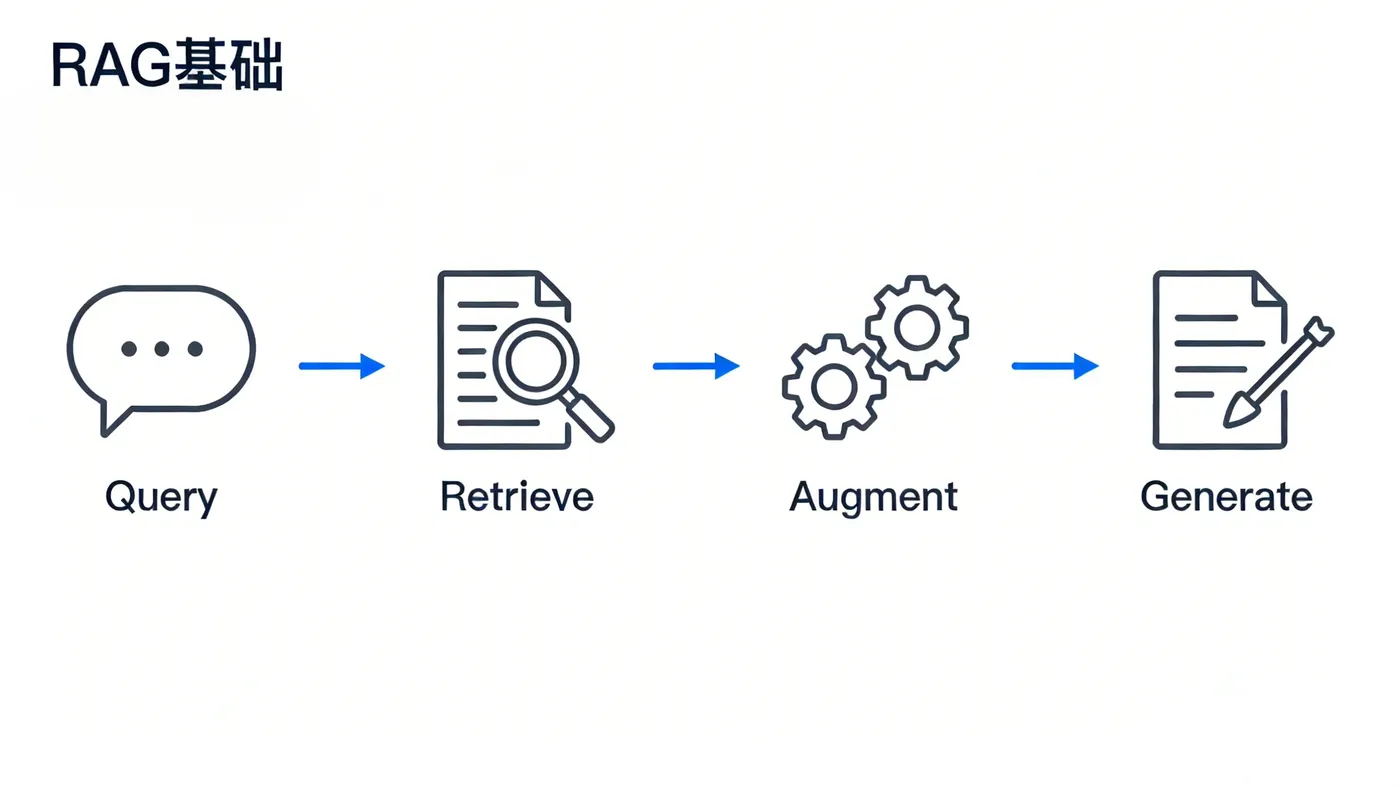
假设我们要为一个科技公司搭建一个“产品知识问答助手”。
第一步:知识库准备与处理
- 收集数据:将产品手册、技术白皮书、FAQ文档、会议纪要等整理成文本(如.txt, .pdf, .docx格式)。
- 切分文档:大文档不能直接处理。使用文本分割器,按段落或固定长度(如500字)将文档切分成一个个小的“文本块”(Chunk)。这是检索效率的关键。
- 向量化:使用嵌入模型(如OpenAI的text-embedding-ada-002,或开源的BGE、Sentence-Transformer)将每个“文本块”转化为一个向量(一组数字) 。这个向量代表了文本的语义。语义相近的文本,向量也相似。
第二步:构建检索系统
- 存储向量:将所有文本块对应的向量存入专门的向量数据库(如Pinecone, Chroma, Milvus, Qdrant)。它支持高效的相似度搜索。
- 用户查询:当用户提问“产品A的续航时间多久?”,用同样的嵌入模型将这个问题也转化为一个查询向量。
- 相似度检索:在向量数据库中,快速查找与“查询向量”最相似的几个“文本块向量”(即计算余弦相似度)。这一步就是“智能秘书”在“外接硬盘”里找资料。
第三步:提示构建与生成
组装提示:这是“增强”的关键。设计一个清晰的提示模板,例如:
text
请严格根据以下资料回答问题。如果资料中没有相关信息,请回答“根据现有资料无法回答”。 资料: {检索到的文本块1} {检索到的文本块2} ... 问题:{用户的问题} 答案:调用大模型:将组装好的提示,发送给大语言模型(如GPT-4, Claude,或你自行微调的模型)。模型会根据你提供的资料生成最终答案。
第四步:部署与优化
- 搭建应用:将以上流程串联成一个Web应用或API服务。
- 持续迭代:根据效果,你可能需要调整:文本切分策略、嵌入模型、检索返回的数量、提示词模板等。
效果评估:如何判断你的RAG好不好用?
不能光说不练,我们需要量化评估:
- 检索相关率:人工抽查,判断系统检索出的文档块是否真正与问题相关。这是基础。
- 答案忠实度:生成的答案是否严格基于提供的资料,有没有“夹带私货”(幻觉)?
- 答案准确性:基于资料,答案本身是否正确?
- 人工评分:邀请真实用户或领域专家,从“有用性”、“流畅性”、“专业性”等维度进行打分。
- A/B测试:在生产环境中,对比使用RAG和不用RAG(或不同RAG方案)时,用户满意度、问题解决率等业务指标的变化。
总结与展望
RAG通过巧妙地结合检索与生成,为大模型装上了“事实的锚”,是当前落地价值最高的AI技术之一。T5-RAG、FiD、RAR代表了不同方向上的优化思路:追求通用、追求效率、追求精准。
未来,RAG技术将向着更智能(如能自主判断何时需要检索)、更端到端(检索与生成联合优化)、更多模态(同时检索图片、表格、文本)的方向演进。
选择建议:
- 刚入门/快速验证:从经典的T5-RAG范式开始,理解整个流程。
- 追求响应速度:考虑FiD架构。
- 要求极高准确性:在关键场景中,引入RAR的相关性过滤思想。
- 没有开发团队:积极寻求像 LLaMA-Factory Online 这类低代码平台,它们能帮你跨越工程鸿沟,快速将想法转化为可用的专属AI应用。
技术不在于多炫酷,而在于能否真正解决问题。希望这篇文章能帮助你推开RAG的大门,开始构建真正“懂行”的智能助手。
