
你好,我是maoku。一名和你一样,在AI浪潮中持续学习与探索的技术博主。
在我们之前几期关于大模型结构的讨论后,今天,我们开启一个新篇章——大模型的后训练。如果说预训练让模型学会了“语言”,有监督微调(SFT)教会了它“答题格式”,那么今天要讲的强化学习,尤其是PPO算法,则是为了赋予模型更接近人类的“价值观”和“创造力”。
试想,你教一个孩子知识(预训练),然后给他例题让他模仿(SFT)。但总有一天,你需要让他面对没有标准答案的开放式问题,这时你无法再给出“步骤一、二、三”,只能在他给出回答后说:“这个想法很有爱心”或“这个方案可能不安全”。这就是强化学习在大模型中的作用:在模糊地带,用奖励(Reward)来引导模型向更优、更符合我们期望的方向进化。
本文,我将带你由浅入深,彻底搞懂如何用PPO(近端策略优化)算法来微调大模型。我们会绕过复杂的数学推导,用最直观的比喻和逻辑,把核心原理、实践步骤讲清楚。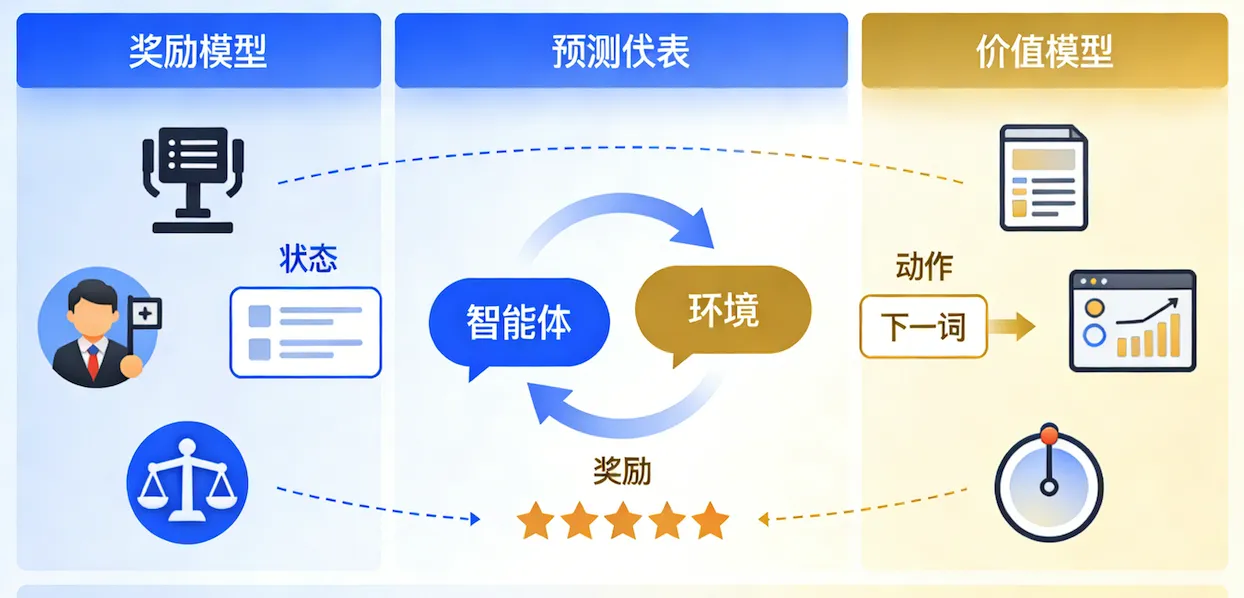
一、引言:为什么大模型需要“强化学习”?
大模型的训练通常分为三个阶段:
- 预训练:在海量文本上学习,获得语言知识和世界知识。目标:预测下一个词。
- 有监督微调(SFT):在指令-答案对数据上学习,学会遵循指令、回答问题。目标:模仿标准答案。
- 基于人类反馈的强化学习(RLHF):这是今天的主角。让模型在开放生成中,学会符合人类复杂偏好(如有益、诚实、无害)的回应。
SFT的局限:它本质上是“模仿学习”。模型学得再好,也只能达到数据集中“老师”的水平。对于“哪个回答更有帮助?”“哪个回复更富有同情心?”这类涉及主观偏好和复杂权衡的问题,SFT无能为力。因为它的损失函数只关心“和标准答案像不像”。
RLHF/PPO的优势:它引入了“奖励”信号。这个奖励可以来自一个训练好的奖励模型(学习人类偏好),也可以来自一套规则。模型通过尝试不同的回答,获得奖励反馈,从而学会最大化期望奖励。这就好比从“死记硬背”变成了“理解评分标准并发挥”。
应用场景:
- 对齐(Alignment):让模型输出更安全、更有用、更诚实的文本。
- 提升复杂能力:将生成一个长答案视为一连串的“决策”,用强化学习优化其逐步推理和规划能力。
- 个性化定制:为不同场景(客服、创作、编程)定制不同的奖励标准,训练出专属的模型。
二、技术原理:深入浅出看懂PPO
PPO并非最古老的RL算法,但它是将RL成功应用于大模型训练的关键算法之一(例如ChatGPT的训练中就使用了PPO)。理解PPO,我们需要先搭建几个核心概念。
核心概念1:智能体与环境的互动
让我们把一个正在训练的大模型想象成一个智能体(Actor)。
- 环境(Environment):就是用户输入的提示词(Prompt)以及模型已生成的上下文。
- 状态(State):当前已生成的所有文本,即上下文。
- 动作(Action):模型从词表中选择下一个词(Token)。
- 奖励(Reward):生成完整个回答后,根据答案质量获得的分数。
这个过程就是:模型看到当前状态(对话历史),采取一个动作(生成下一个词),改变状态(文本变长了),最终在回合结束时获得一个总奖励。其目标是通过调整自身参数,使得在应对各种提示时,能获得最高的长期累积奖励。
核心概念2:奖励——训练的指挥棒
在PPO训练前,我们需要一个“评分老师”——奖励模型(Reward Model, RM)。它通常是一个经过特殊训练的小型模型。
- 如何训练?收集人类对模型多个回答的排序数据(例如,回答A比回答B更好)。然后训练RM去拟合这种判断偏好,让它能给一个完整回答打出一个分数。
- 作用:在PPO训练中,这个分数就是模型生成质量的“指挥棒”。
核心概念3:价值与优势——判断动作的好坏
生成每个词时,模型怎么知道这个选择是好是坏?这需要两个评判员:
- 价值模型(Value Model, VM/Critic):它评估当前状态(已生成的文本)的“潜在价值”。可以理解为一个“期望分数预测器”。
- 优势函数(Advantage):这是关键!它衡量的是执行某个特定动作(选某个词),相比于在这个状态下“平均表现”而言,额外带来了多少好处。
- 公式(直观理解):
优势 = 实际收益 - 平均预期收益 - 如果优势为正,说明这个词选得好;为负,则说明选得差。
- 公式(直观理解):
那么“实际收益”怎么算?这里就引出了PPO的核心模块:广义优势估计(GAE)。
核心概念4:GAE——权衡当下与未来
GAE用来计算每一步的“优势”值。它聪明地融合了两种信息:
- 奖励模型给出的即时反馈(更直接,但可能波动大)。
- 价值模型对未来的预测(更平滑,但初期可能不准)。
你可以把GAE想象成一个天平:
- 天平一端是奖励模型(代表“眼前的真实得分”)。
- 另一端是价值模型(代表“长远的潜力预期”)。
- GAE中的两个参数(
γ和λ)就是调节这个天平的砝码。通过调节它们,我们可以决定是更信任眼前的奖励,还是更相信模型自己对未来的判断。
核心概念5:PPO的核心——带着“锁链”跳舞
这是PPO最精妙、最“工程化”的部分。它的目标是在利用已有数据高效学习的同时,防止一次更新“步子迈得太大”导致模型崩溃(例如突然开始输出乱码)。
它通过两个关键技术实现:
1. 重要性采样(Importance Sampling)
- 问题:强化学习需要模型与环境(生成文本)实时交互获取新数据,这非常昂贵。
- 解决:PPO允许用“旧策略”生成的一批数据,来多次更新“新策略”。这就需要一個比率(
新策略采取该动作的概率 / 旧策略采取该动作的概率)来修正数据的重要性。如果新策略更倾向于某个好动作,这个动作的数据权重就加大。
2. 裁剪(Clipping)—— “锁链”所在
- 风险:如果上述比率变得极大或极小,一次更新可能导致策略剧变,训练失控。
- 解决:PPO的损失函数中,对这个比率进行了“裁剪”,强制它落在一个小小的区间内(比如[0.8, 1.2])。
- 比喻:就像教练指导运动员。教练不会让运动员一下子把动作改成100%的新样子,而是会说:“你原来的动作在这里,这次试着调整10%看看效果。” PPO的“近端”就是这个意思,确保每次更新都只在旧策略的“附近”小步探索。
为什么需要参考模型(Reference Model)?
在PPO的训练框架中,你还会看到一个一直冻结不动的参考模型(通常是SFT后的模型)。它的作用是充当“初心守护者”。
- 防止奖励作弊(Reward Hacking):如果没有约束,模型可能会发现奖励模型的漏洞。例如,奖励模型可能偏爱长文本,模型就可能生成一堆无意义的废话来刷高分。参考模型通过计算当前模型与它的KL散度来施加约束。
- 比喻:参考模型就像模型的“原始人格”或“基础知识”。PPO训练鼓励模型在奖励引导下“发挥”,但KL散度惩罚会拉住它说:“别飘得太远,别忘了你原本是谁,别说那些完全不符合你基础认知的胡话。” 这有效地保持了模型的语言能力和训练稳定性。
三、实践步骤:动手进行PPO微调
理论说得再多,不如动手一试。下面我们梳理一个典型的PPO微调流程。
步骤一:数据准备
- 提示词(Prompt)数据集:准备一个多样化的指令或提示词集合,无需配对答案。这是PPO训练的“考题集”。
- 人类偏好数据(用于训练奖励模型):收集三元组数据
(提示词, 获胜回答, 失败回答)。这部分数据需要人工标注或利用AI反馈。
步骤二:训练奖励模型(RM)
- 模型选择:通常使用一个经过SFT的模型,在其顶部添加一个回归输出层(用于输出一个标量分数)。
- 训练:将
(提示词, 回答)输入RM,获取最终隐藏状态,通过回归层得到分数。使用配对排序损失,让获胜回答的分数高于失败回答的分数。- 常见损失函数:
loss = -log(sigmoid(chosen_score - rejected_score)) - 这个步骤相对独立,训练好的RM将在PPO主流程中作为“裁判”被调用。
- 常见损失函数:
步骤三:PPO主训练流程
这是核心循环,涉及四个模型协同工作:
- 策略模型(Actor):我们要训练的主角,负责生成文本。
- 参考模型(Reference Model):冻结的SFT模型,用于计算KL惩罚。
- 价值模型(Critic):需要训练的“评价者”,评估状态价值。
- 奖励模型(Reward Model):上一步训练好的冻结模型。
循环流程如下:
- 采样:从Prompt数据集中采样一批提示词。
- 生成:用当前的策略模型为每个提示词生成完整回答(即一个“轨迹”)。
- 评估:
- 将生成的
(提示词, 回答)输入奖励模型,得到整体奖励分数。 - 用价值模型估算生成过程中每个步骤的状态价值。
- 计算参考模型与策略模型在每一步的KL散度。
- 结合以上三者,通过GAE公式计算出每一步动作(生成每个词)的“优势值”A_t。
- 将生成的
- 优化:
- 更新策略模型(Actor):使用包含裁剪机制的PPO损失函数,其核心是最大化
(比率 * 优势值),但同时用clip限制比率变化范围,并加入与参考模型的KL散度作为惩罚项。 - 更新价值模型(Critic):让价值模型的预测(V值)尽可能接近“目标价值”(通常用
奖励 + γ * 下一步的V值计算)。这是一个回归问题。
- 更新策略模型(Actor):使用包含裁剪机制的PPO损失函数,其核心是最大化
- 重复:清空当前批次数据,回到步骤1,用更新后的模型进行新一轮采样、生成、评估和优化。
对于想要快速上手、避免复杂工程搭建的研究者和开发者,可以尝试使用一些高度集成的微调工具。例如,【LLaMA-Factory Online】提供了可视化的Web界面,能够将PPO等复杂训练流程进行封装,大大降低了实操门槛。
四、效果评估:如何验证微调成果?
PPO训练完成后,如何判断模型是否真的变好了?不能只看损失曲线下降,需要多维度评估:
人工评估(黄金标准):
- 收集一批新的、未见过的提示词。
- 让SFT基线模型和PPO微调后的模型分别生成回答。
- 请评估人员(最好是领域专家)从有用性、安全性、流畅性、符合指令程度等多个维度进行盲评打分或偏好选择。这是最可靠的评估方式。
自动指标评估:
- 奖励模型得分:在单独的测试集上,计算PPO模型输出的平均奖励分数,应显著高于SFT基线。但要注意防范过拟合奖励模型。
- 多样性指标:计算生成文本的n-gram重复率、词汇多样性等,确保模型没有退化到只输出单一、保守的答案。
- 安全性/毒性检测:使用现有的内容安全API或分类器,测试模型在敏感提示下的输出安全性是否提升。
对比测试:
- 进行A/B测试,将两个模型部署在简化环境中,让真实用户使用并收集反馈。
五、总结与展望
总结一下,PPO算法为大模型的后训练提供了一套强大的框架:
- 它是什么:一种稳定、高效的强化学习算法,通过“小步快跑”(近端优化)和“不忘初心”(KL约束)的策略,引导模型优化其生成行为。
- 它解决了什么:让大模型能够超越简单的模仿,学会在复杂、开放式的任务中,按照人类定义的抽象偏好(通过奖励模型体现)进行创造和决策。
- 关键点:PPO的成功依赖于奖励模型的质量、GAE对优势的合理估计,以及裁剪机制和参考模型带来的训练稳定性。
展望未来,PPO只是一个开始。后续出现了如DPO(直接偏好优化)等更简洁的算法,以及面向搜索、推理等特定任务的强化学习变体。强化学习与大模型的结合,正让我们从“教会模型说话”走向“教会模型思考与权衡”,这无疑是通向更通用、更可靠人工智能的关键路径之一。
希望这篇深入浅出的解读,能帮你拨开PPO的迷雾。如果你在实践过程中有任何心得或疑问,欢迎留言与我交流。我是maoku,我们下期再见!
思考题:如果你要训练一个专用于“编写温暖人心故事”的模型,你会如何设计你的奖励模型训练数据?PPO训练中的参考模型又该如何选择?欢迎在评论区分享你的构想。
