
一个让人抓狂的发现
你花了大半天时间,好不容易把一个4GB的AI模型下载到本地,满心欢喜地输入"你好"想测试一下。结果呢?
AI开始了:
❝"你好,这是一个关于人工智能的长篇大论。首先我们要了解深度学习的发展历史,从1943年的感知机开始说起..."
❞
「天哪!我只是想说个"你好",你怎么开始写论文了?」
这就像你跟朋友打招呼说"你好",结果他突然开始背诵《资治通鉴》一样离谱。
但神奇的是,当我调整了一下输入格式后,同一个模型突然变得正常了:
❝"你好!有什么可以帮助你的吗?"
❞
这到底是什么魔法?
揭秘:AI的"暗号系统"
模型训练的"条件反射"
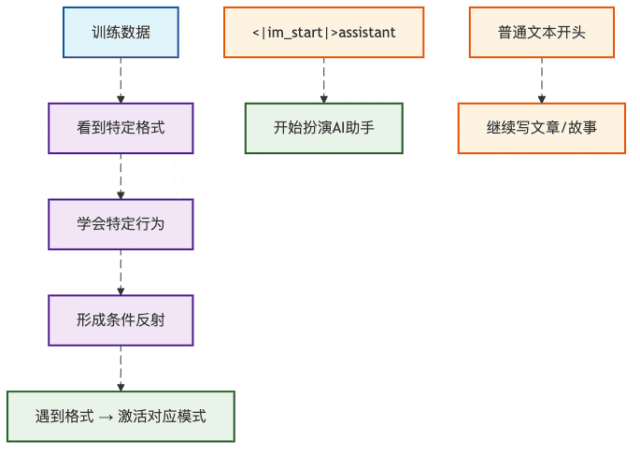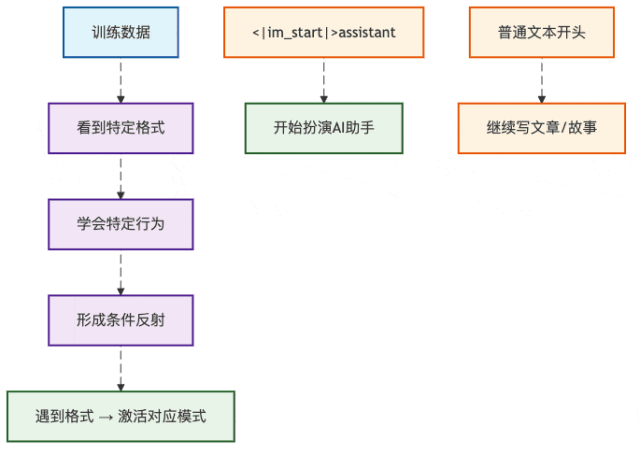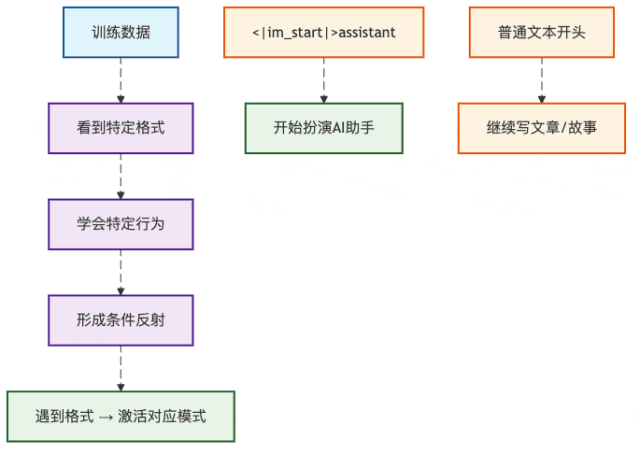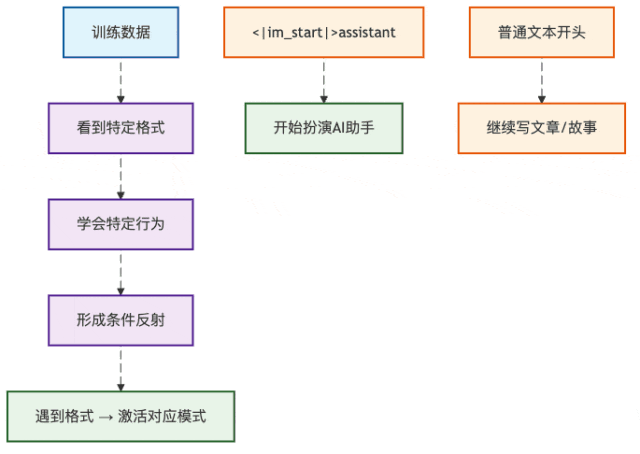 图1:AI模型的格式识别机制
图1:AI模型的格式识别机制
这就像你听到《义勇军进行曲》会自动站起来一样,AI模型在训练时也形成了"条件反射"。当它看到特定的格式标记,就知道该进入什么模式。
Base模型 vs Instruct模型:两个不同的"人格"
想象AI模型有两种人格:
「Base模型」 - 像个"话痨文青":
- 训练目标:把文章写完
- 看到任何输入都想:这肯定是某篇文章的开头
- 结果:疯狂续写,停不下来
「Instruct模型」 - 像个"贴心助手":
- 训练目标:帮用户解决问题
- 看到对话格式就想:用户在问我问题
- 结果:简洁回答,恰到好处
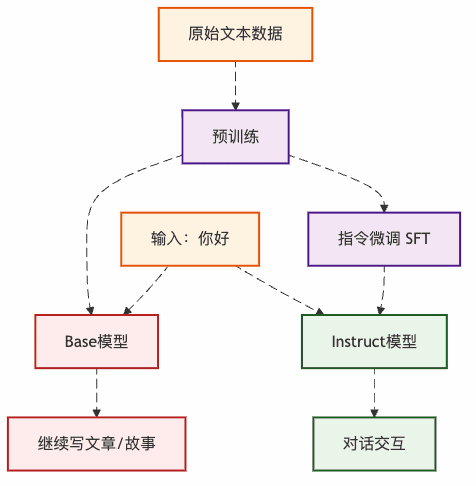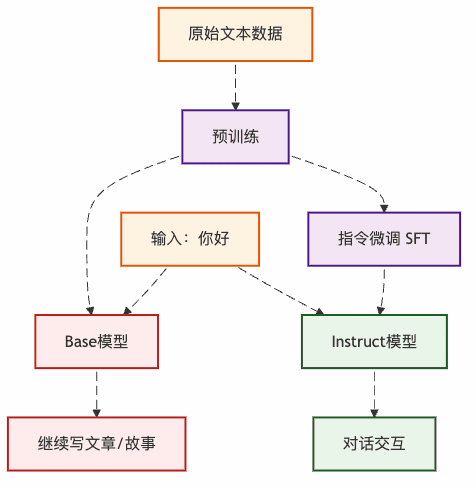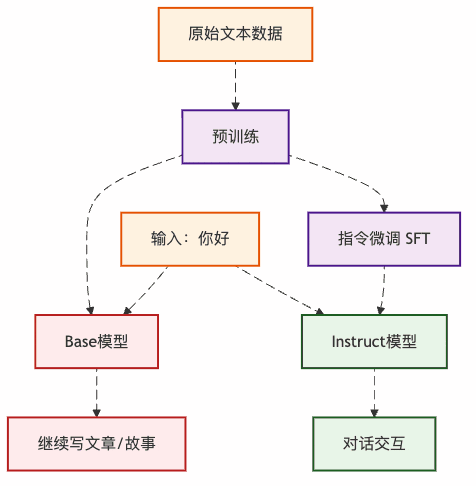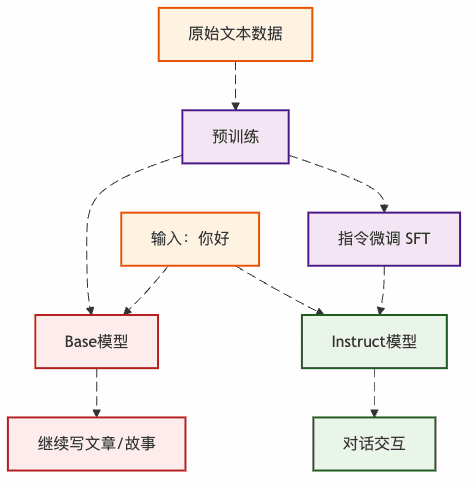 图2:两种模型的不同行为路径
图2:两种模型的不同行为路径
这就解释了为什么同样是"你好",Base模型要写论文,而Instruct模型能正常聊天。
不同AI的"方言"问题
各大厂商的"土话"
就像全国各地都说中文,但方言不同,各个AI模型也有自己的"对话方言":
「通义千问家族」:
<|im_start|>system 你是个智能助手<|im_end|> <|im_start|>user 你好<|im_end|> <|im_start|>assistant
「智谱ChatGLM家族」:
[gMASK]sop<|system|> 你是个智能助手 <|user|> 你好 <|assistant|>
「Meta的Llama家族」:
<s>[INST] <<SYS>> 你是个智能助手 <</SYS>> 你好 [/INST]
这就像:
- 北京人说"您好"
- 上海人说"侬好"
- 广东人说"雷好"
意思一样,但"发音"不同!
API服务:AI界的"翻译官"
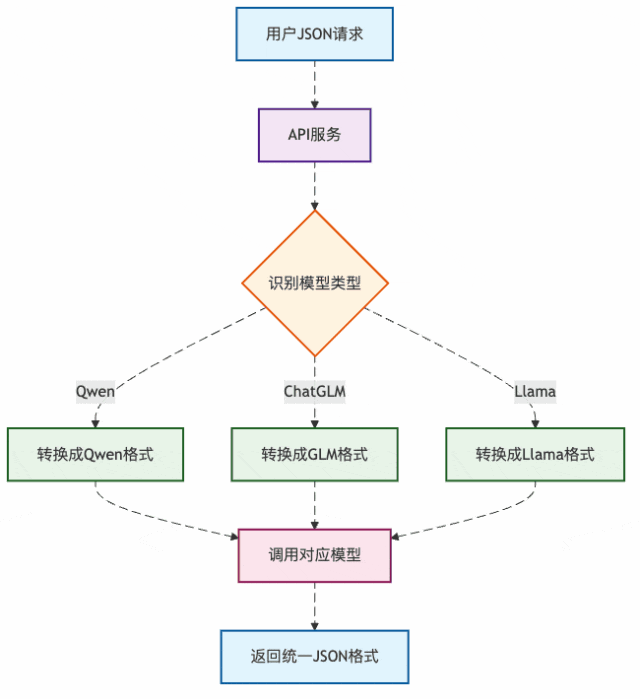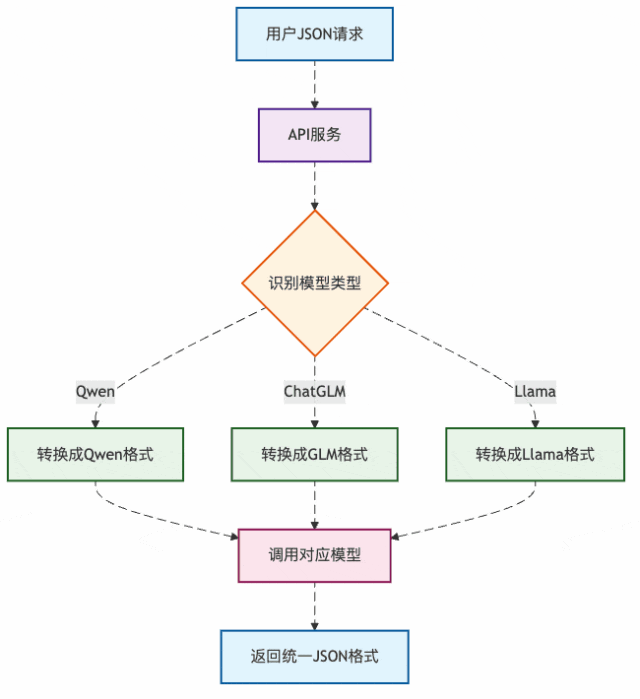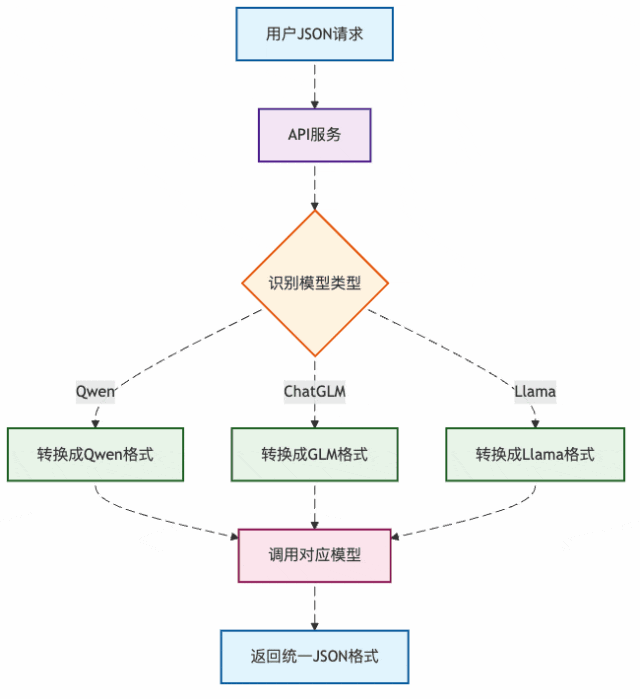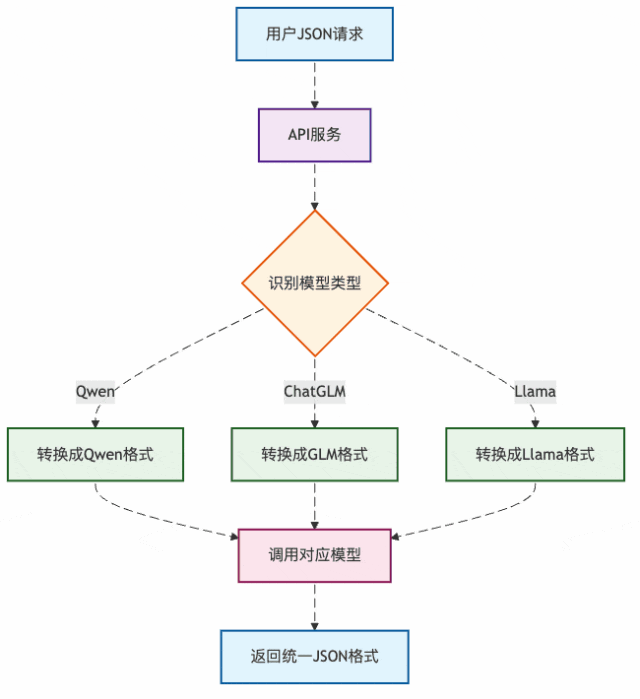 图3:API服务的格式转换流程
图3:API服务的格式转换流程
这就是为什么我们调用不同厂商的API都用同样的JSON格式,但底层模型收到的却是各自的"方言"。
API服务就像个万能翻译官:
- 收到你的"普通话"(标准JSON)
- 转换成对应模型的"方言"
- 把模型回复再翻译回"普通话"
场景化理解:打车软件的启发
想象一下滴滴打车的流程,这和AI对话格式很像:
打车流程
- 你在APP上选择"快车"
- 输入起点终点
- 司机接单,开始服务
- 按照导航路线行驶
AI对话流程
- 设定"system"角色(相当于选择服务类型)
- 用"user"标记输入问题(相当于输入起终点)
- "assistant"开始回答(相当于司机接单)
- 按照训练"路线"生成答案
「如果没有正确格式会怎样?」
- 打车:司机不知道你要去哪,可能把你拉到天津
- AI:模型不知道该做什么,可能开始写小说
实战:让你的本地AI听话
问题诊断
如果你的本地AI表现异常,先检查这几点:
# ❌ 错误做法:直接扔给模型 prompt = "你好" # ✅ 正确做法:使用对话格式 messages = [ {"role": "system", "content": "你是一个有用的AI助手。"}, {"role": "user", "content": "你好"} ] prompt = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True )
实用技巧
「1. 调试大法」
print(f"发送给模型的完整内容:\n{prompt}")
就像调试网络请求一样,先看看你发了什么。
「2. 生成参数调优」
# 控制话痨程度 max_new_tokens=150, # 最多说150个词,别写论文 # 增加回答多样性 temperature=0.7, # 不要太死板 do_sample=True, # 允许一定随机性 # 避免重复 repetition_penalty=1.1 # 别像复读机
常见坑点避坑指南
「坑点1:用Base模型聊天」
- 现象:怎么调格式都不对劲
- 解决:换成Instruct版本
「坑点2:格式写错了」
- 现象:AI回答牛头不对马嘴
- 解决:检查
<|im_start|>标签是否正确
「坑点3:忘记设置结束标记」
- 现象:AI说话没完没了
- 解决:正确设置
eos_token_id
背后的深层原理
为什么格式这么重要?
AI模型本质上是在做「模式匹配」:
- 看到熟悉的模式 → 激活对应行为
- 看到陌生的输入 → 胡乱猜测
这就像:
- 看到红绿灯,你知道该停车或通行
- 看到奇怪的信号,你就懵了
AI在数百万个标准对话上训练,形成了"肌肉记忆"。正确的格式就是激活这种记忆的钥匙。
训练数据的威力
想象AI的训练过程就像学习背课文:
老师示范了100万次: <|im_start|>user 问题<|im_end|> <|im_start|>assistant 答案<|im_end|> 结果:看到这个格式 = 立刻进入答题模式
但如果你突然给它一个从没见过的格式,它就像学生突然被问了课外题,只能瞎蒙。
总结:掌握AI的"说话之道"
通过这次探索,我们发现了几个重要事实:
- 「对话格式不是装饰,是协议」
- 就像HTTP协议一样,必须遵守规范
- 格式错了,功能就废了
- 「不同模型有不同"口音"」
- Qwen说"qwen话",ChatGLM说"glm话"
- API服务帮我们做翻译
- 「Base模型不适合聊天」
- 就像让写小说的作家当客服,不对路
- 聊天务必用Instruct版本
- 「理解训练过程很重要」
- 训练什么数据,就会什么技能
- 格式是模型的"暗号系统"
实用建议
「给本地部署用户的建议:」
- 务必使用正确的对话格式
- 选对模型类型(Instruct vs Base)
- 调试时打印完整prompt检查
「给API用户的建议:」
- 用标准JSON格式就行,别操心转换
- 但了解底层原理有助于理解模型行为
「给技术爱好者的建议:」
- 动手试试不同格式的效果
- 体验一下Base模型和Instruct模型的差异
- 这样能更深入理解AI的工作原理
现在你知道了AI为什么这么"挑剔",下次本地部署模型时,记得给它正确的"暗号",让它乖乖听话!就像你需要用正确的APP叫外卖一样,和AI交流也需要用对"接头暗号"。
