

【AI大模型面试宝典系列】从面试高频考点到核心原理拆解,从实战代码到避坑指南,帮你吃透大模型面试的每一个得分点!后续会逐个攻破面试核心模块:基础概念、架构细节、项目实操、行业题套路…… 每篇聚焦一个必考点,既能快速补短板,也能精准练重点 —— 想搞定大模型面试、无痛拿下offer?这系列直接码住!
您的认可将会鼓励我更高频、更高质量的完成图文输出,您的批评也将会让我的博文更精准。
所以,不要吝啬您的评价、点赞
🎯 注意力机制详解
🎯 概述
注意力机制是Transformer架构的核心,允许模型在处理序列时动态地关注重要信息。
🏗️ 注意力机制类型
1️⃣ 自注意力机制 (Self-Attention, SA)
原理:序列中的每个元素关注序列中的其他所有元素
代码示例:
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, d_model, d_k, d_v):
super().__init__()
self.w_q = nn.Linear(d_model, d_k)
self.w_k = nn.Linear(d_model, d_k)
self.w_v = nn.Linear(d_model, d_v)
self.scale = torch.sqrt(torch.FloatTensor([d_k]))
def forward(self, x, mask=None):
Q = self.w_q(x)
K = self.w_k(x)
V = self.w_v(x)
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention = torch.softmax(scores, dim=-1)
return torch.matmul(attention, V)
2️⃣ 交叉注意力机制 (Cross-Attention, CA)
原理:一个序列关注另一个序列的信息
应用场景:
编码器-解码器架构
多模态融合
知识蒸馏
3️⃣ 多头注意力机制 (Multi-Head Attention, MHA)
原理:并行运行多个注意力头,捕获不同类型的关系
架构:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 线性变换并分头
Q = self.w_q(query).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
K = self.w_k(key).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
V = self.w_v(value).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
# 注意力计算
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.FloatTensor([self.d_k]))
if mask is not None:
mask = mask.unsqueeze(1).unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
attention = torch.softmax(scores, dim=-1)
context = torch.matmul(attention, V)
# 合并多头
context = context.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model
)
return self.w_o(context)
4️⃣ 分组注意力机制 (Grouped Query Attention, GQA)
原理:将查询头分组,每组共享键值头,平衡MHA和MQA
优势:
减少内存带宽需求
保持模型质量
推理加速
5️⃣ 多查询注意力机制 (Multi-Query Attention, MQA)
原理:所有查询头共享相同的键值头
特点:
显著减少内存带宽
推理速度提升
可能轻微影响质量
6️⃣ 多头潜在注意力 (Multi-Head Latent Attention, MLA)
原理:通过低秩投影减少键值缓存
DeepSeek创新:
低秩键值联合压缩
减少推理时KV缓存
保持表达能力
📊 注意力机制对比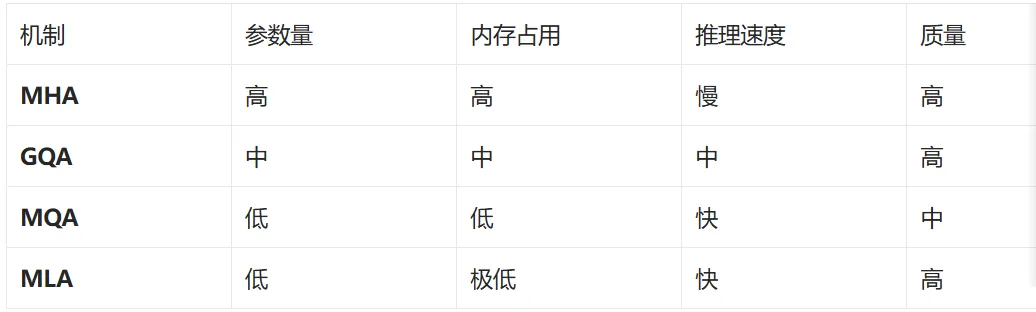
🎯 面试重点
高频问题
自注意力和交叉注意力的区别?
为什么需要多头注意力?
GQA和MQA的权衡?
如何计算注意力权重?
注意力机制的时间和空间复杂度?
实战分析
# 计算注意力复杂度
def attention_complexity(seq_len, d_model, n_heads):
# 计算注意力矩阵: O(n²d)
# 存储KV缓存: O(nhd)
time_complexity = seq_len * seq_len * d_model
space_complexity = seq_len * n_heads * (d_model // n_heads)
return time_complexity, space_complexity
📚 深入阅读
Transformer基础结构
位置编码详解
[主流大模型结构]
