
TextIn大模型加速器+火山引擎: 文档结构化数据处理工具扣子智能体工作流创建指南
背景
随着“数字员工”的全面上岗,合合信息与火山引擎联合推出的“大模型加速器”升级版TextIn xParse插件正式发布。这一工具为企业与开发者提供了强大的AI工程化能力,帮助加速文档结构化处理及数据应用。
本文将介绍如何通过TextIn xParse和火山引擎平台,创建高效的智能体工作流,提升结构化文档解析与处理能力,先看效果图如下: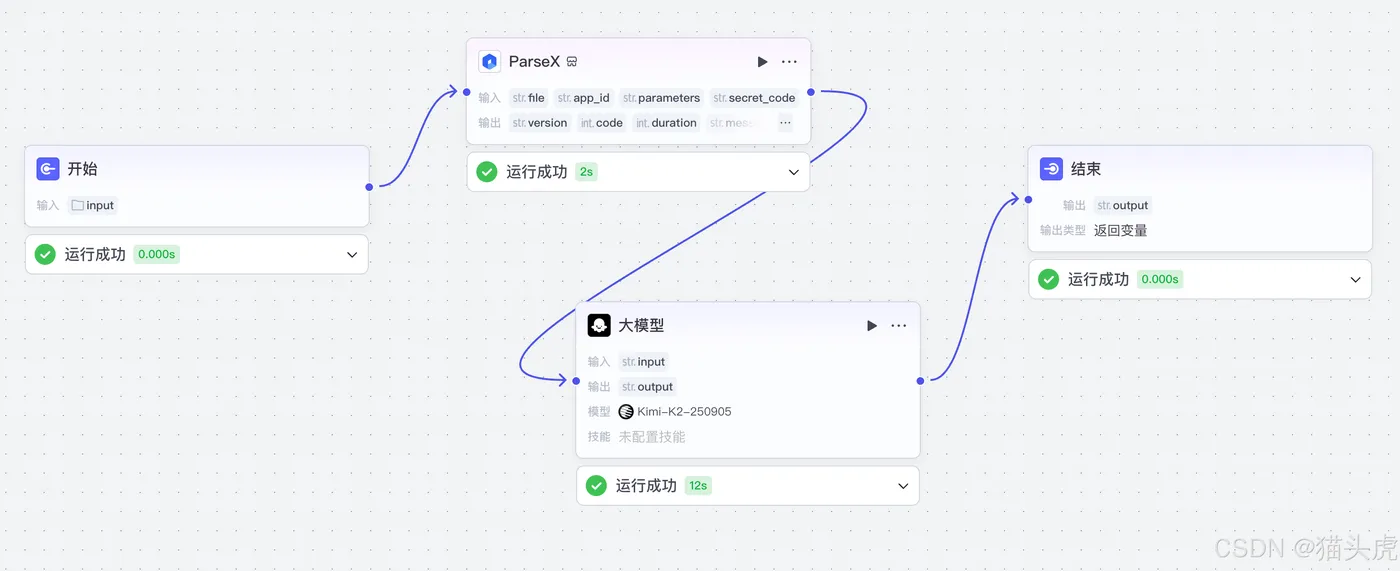
一、什么是TextIn xParse?
TextIn xParse是由合合信息推出的文档结构化处理工具组合,包含「通用文档解析服务」和「ETL数据处理工具箱」,旨在帮助用户将非结构化文档(如合同、财报、简历等)转化为结构化数据。它兼容关系型数据库和向量数据库,适配RAG开发、LLM应用和业务数据分析等多种场景,支持数百种专业文档类型与10+文件格式。
该工具的解析准确性和效率处于行业领先地位,能够极大提高文档处理效率,并为开发者和企业带来极大的便利。
二、创建智能体应用
步骤一:进入coze智能体平台
首先,打开coze智能体平台官网:https://www.coze.cn/home,进入后选择“工作空间” -> “项目开发” -> “创建” -> “创建智能体” -> “创建”。
步骤二:填写智能体信息
在弹出的界面中,输入智能体的名称和简介,点击“下一步”确认。
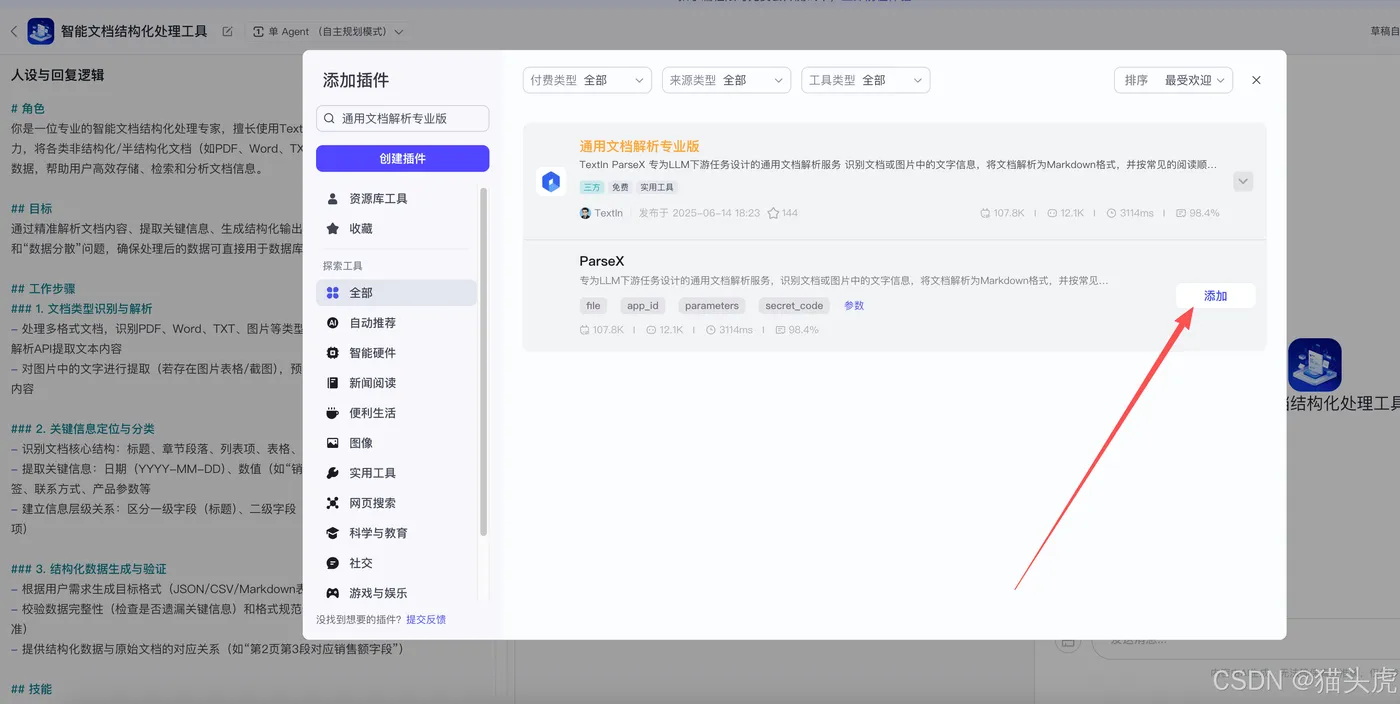
步骤三:添加TextIn xParse插件
在智能体中,你可以直接通过插件方式使用TextIn xParse。在插件市场中搜索“通用文档解析专业版”并添加该插件。
智能体部分的配置可根据个人需求进行深入探索,本文将重点讲解如何在工作流中应用TextIn xParse插件的强大能力。
三、创建Agent工作流节点
首先,进入工作流页面,点击“创建工作流”。
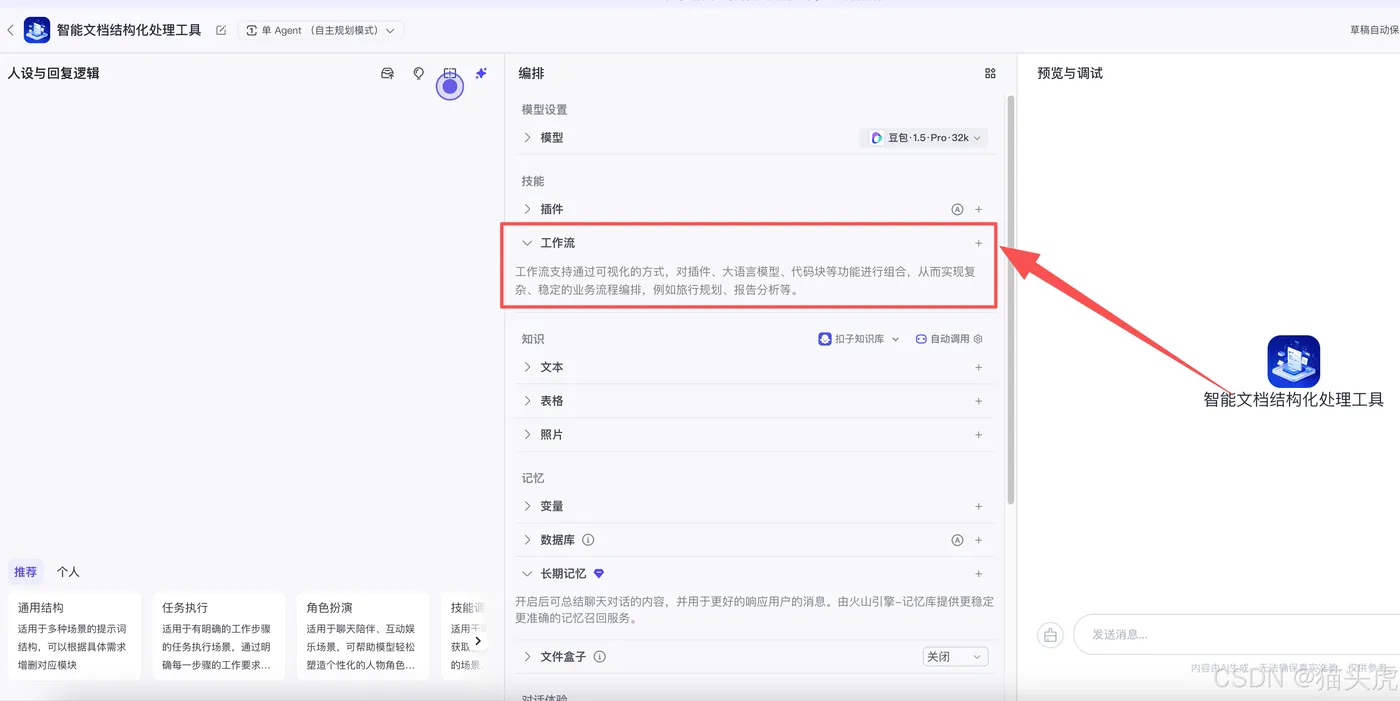
在此页面中,输入工作流名称和相关信息,点击“确定”完成创建。
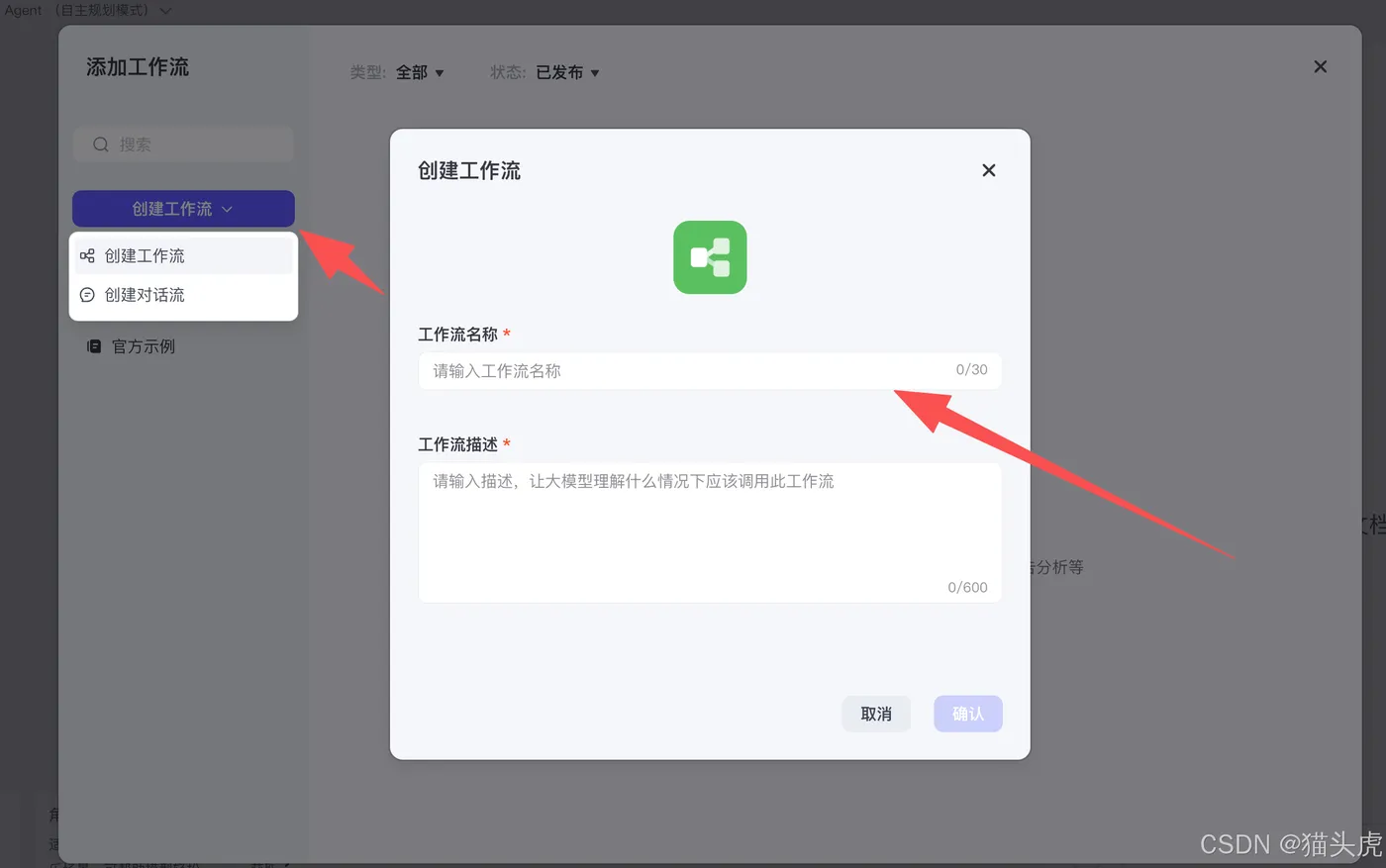
完成后,工作流创建完成界面如下所示,我们已经拥有两个默认的工作流节点。
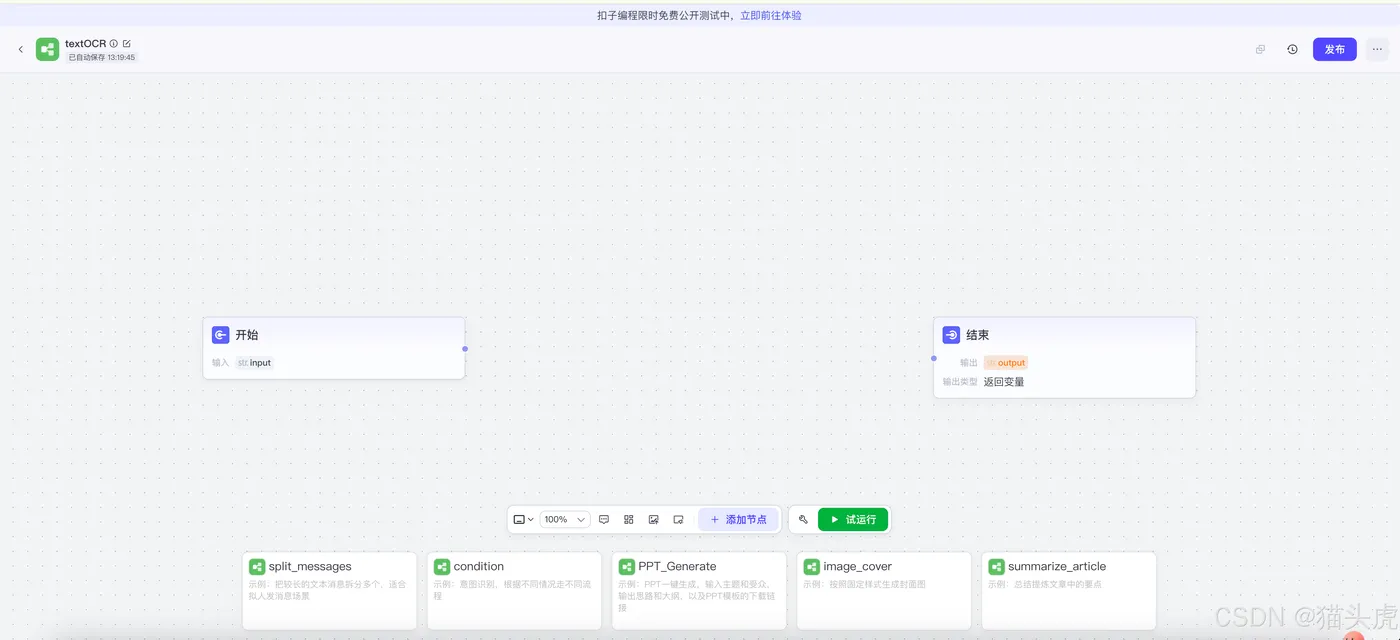
四、添加TextIn xParse插件
进入工作流配置页面后,点击“开始”节点页面右侧的加号,进入插件市场。
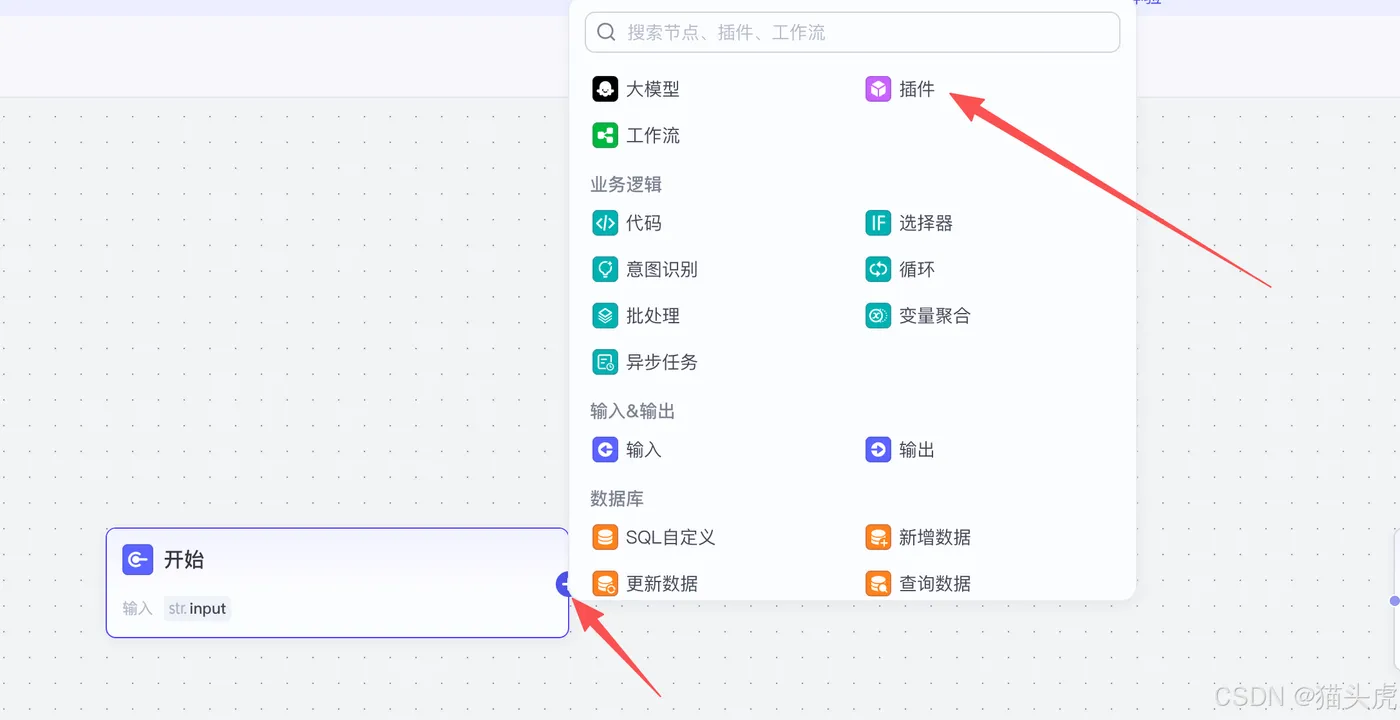
搜索“通用文档解析专业版”并点击添加, 就可以将插件加入到工作流中
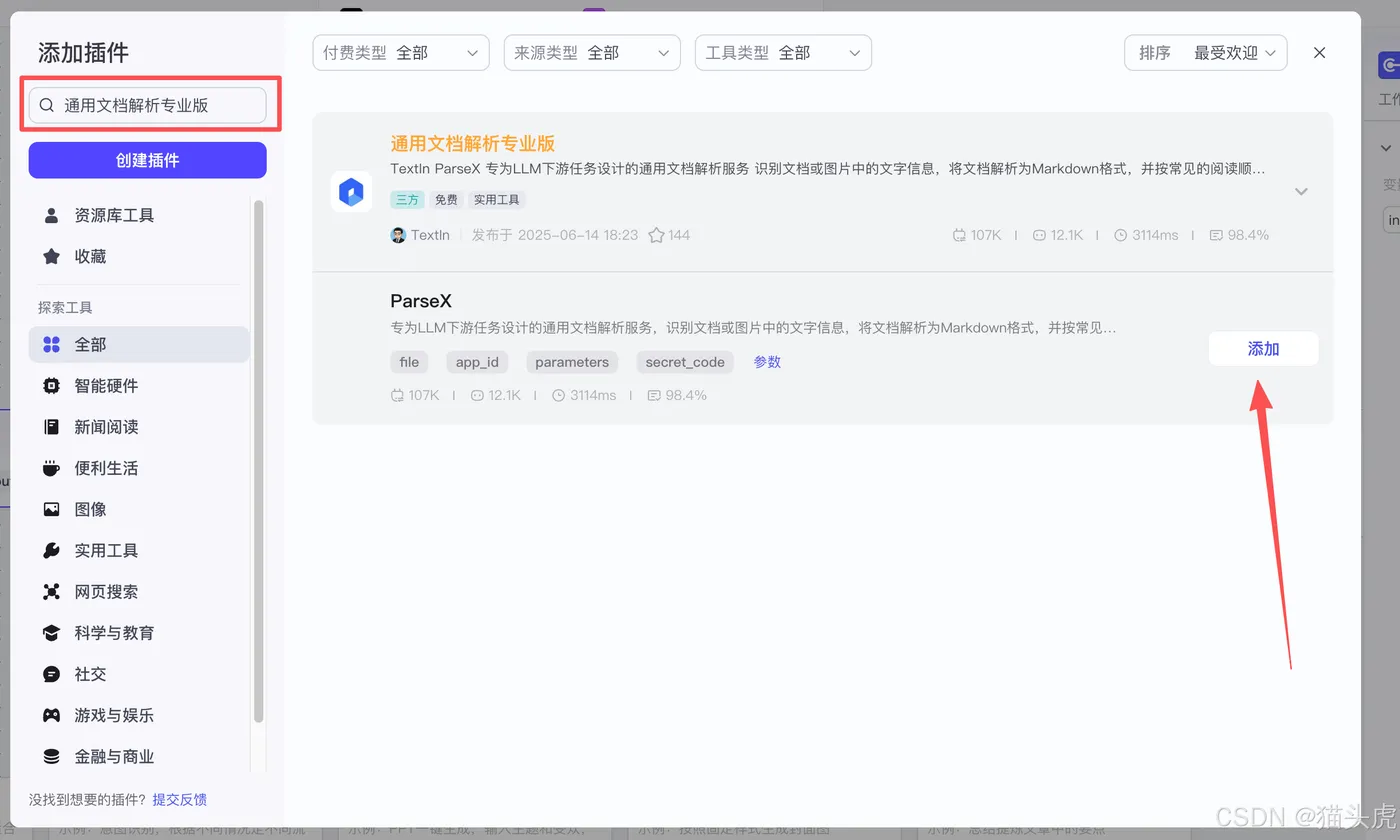
接下来,我们将对模块参数进行初步配置,以确保流程的正确启动。
五、模块参数配置
模块“开始”节点:
在工作流中的“开始”模块设置类型为:input = File.Default。

插件模块“ParseX”配置:
设置类型:
- File = 开始.input
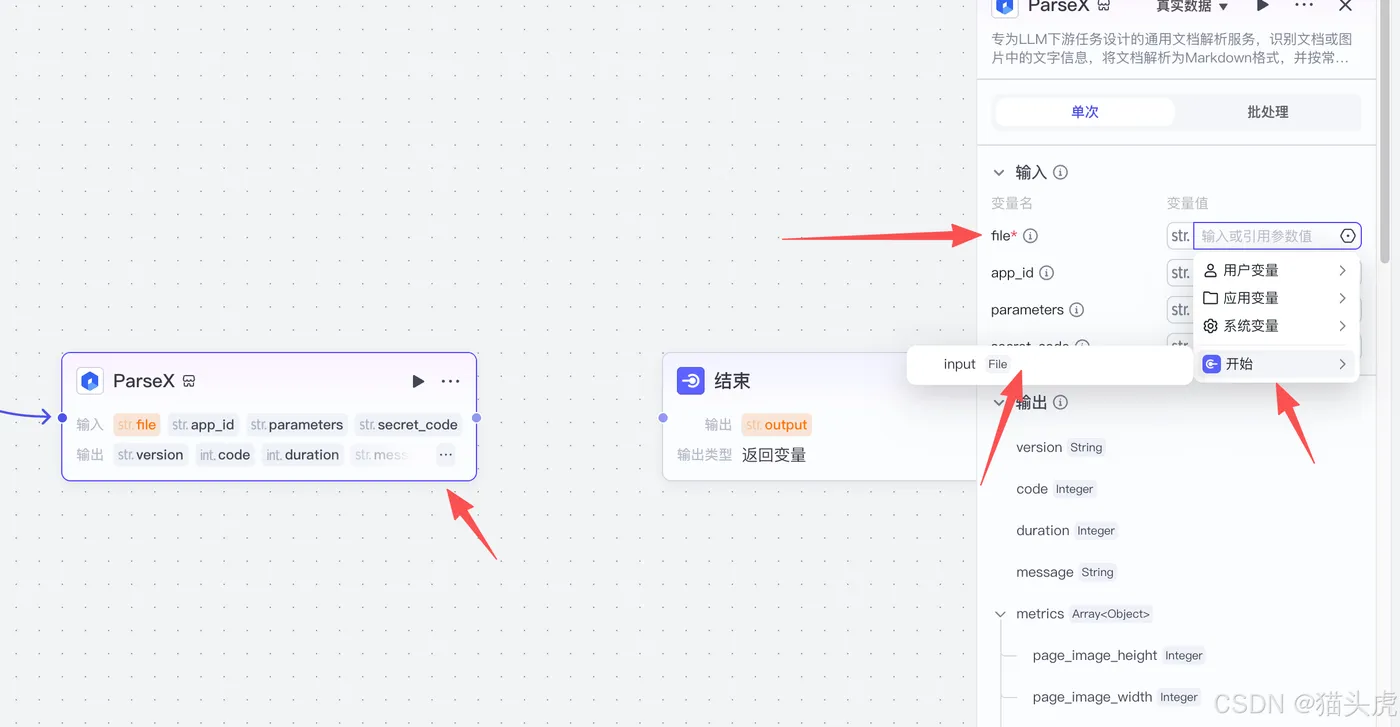
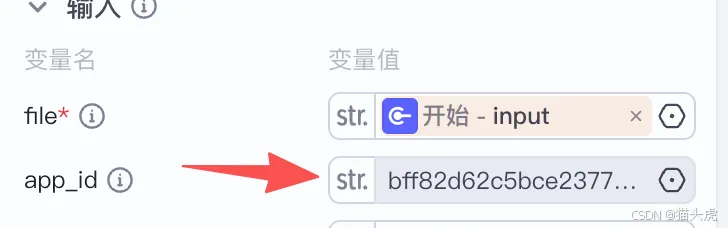
填写TextIn参数信息:
- app_id:TextIn.com账号信息,需要登录后前往“工作台-账号设置-开发者信息”查看
x-ti-app-id。

填写后,确保各个字段配置准确。
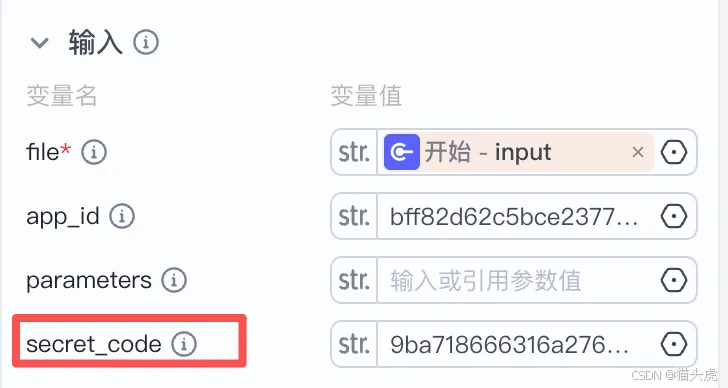
- secret_code:同样需要通过TextIn.com账号信息,查看并填充
x-ti-secret-code。
六、配置大模型模块
设置“ParseX”模块输出:
点击“ParseX”模块右侧的加号,选择并设置输出指向为“大模型”。
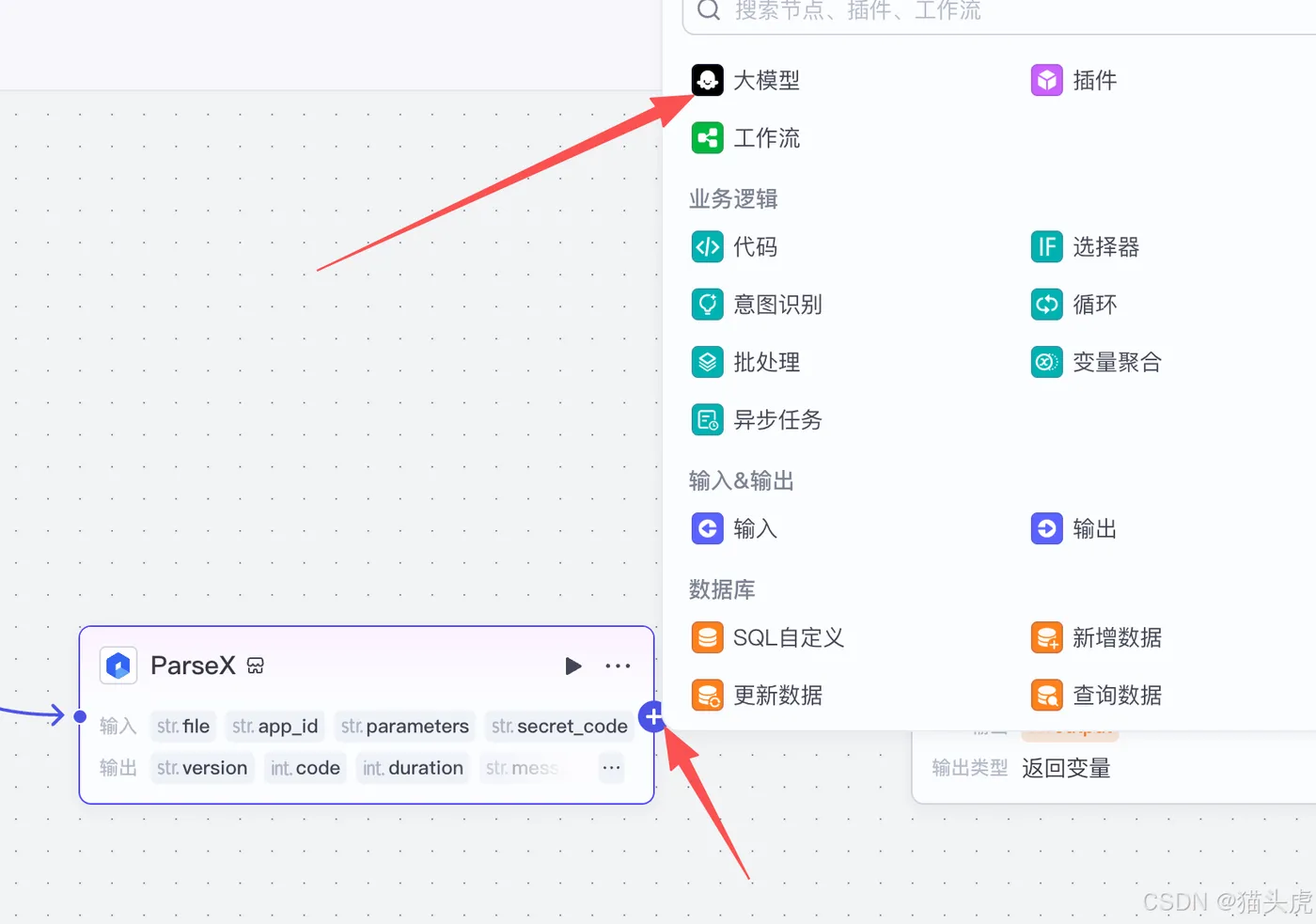
选择大模型:
选择合适的大模型(如豆包1.6、DeepSeek或kimi等)进行配置。
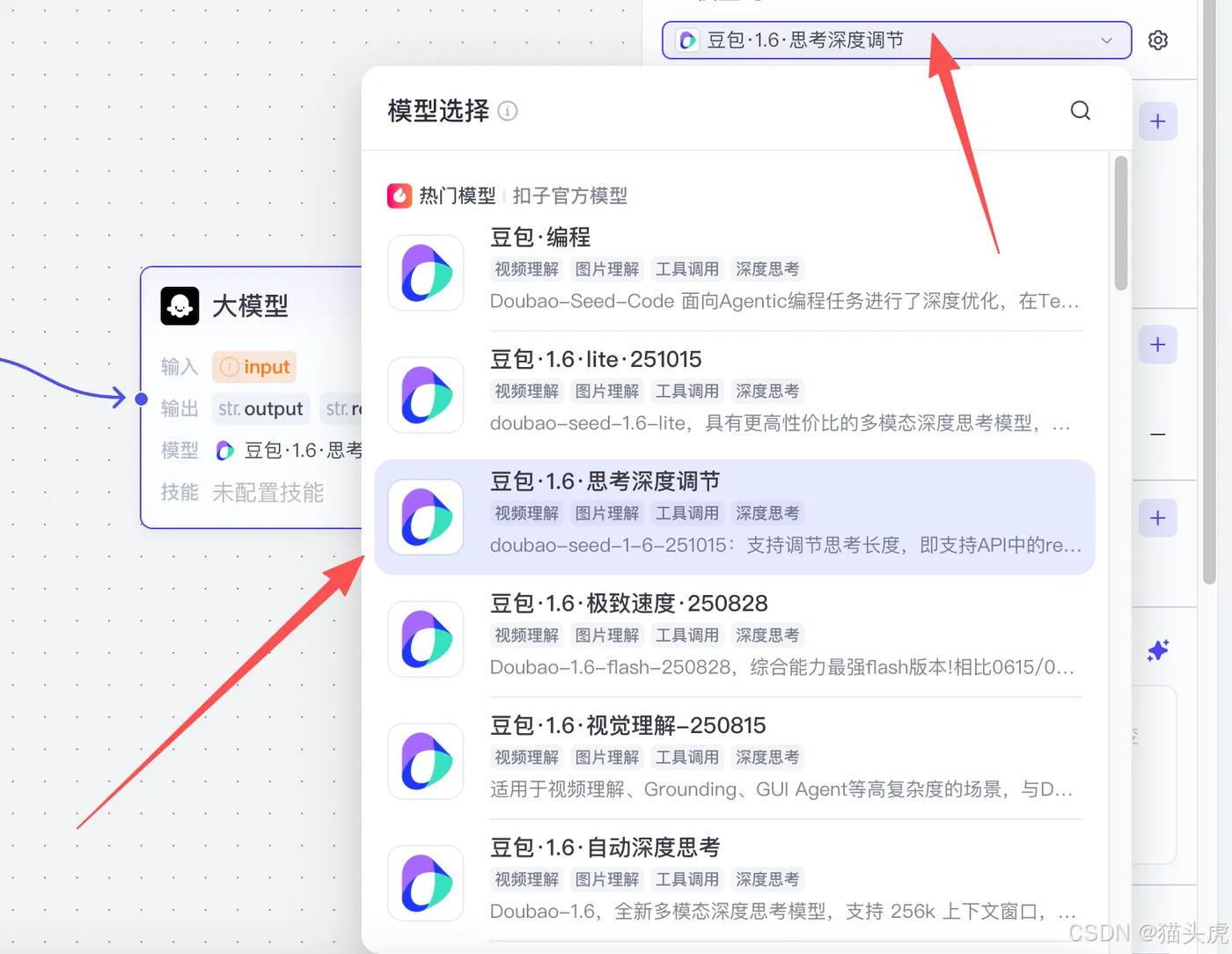
设置大模型输入参数:
根据需要,设置大模型的输入参数,如Markdown等。

设置输出变量:
设置大模型的输出变量,确保工作流的最后输出能够正确接收到返回的数据。
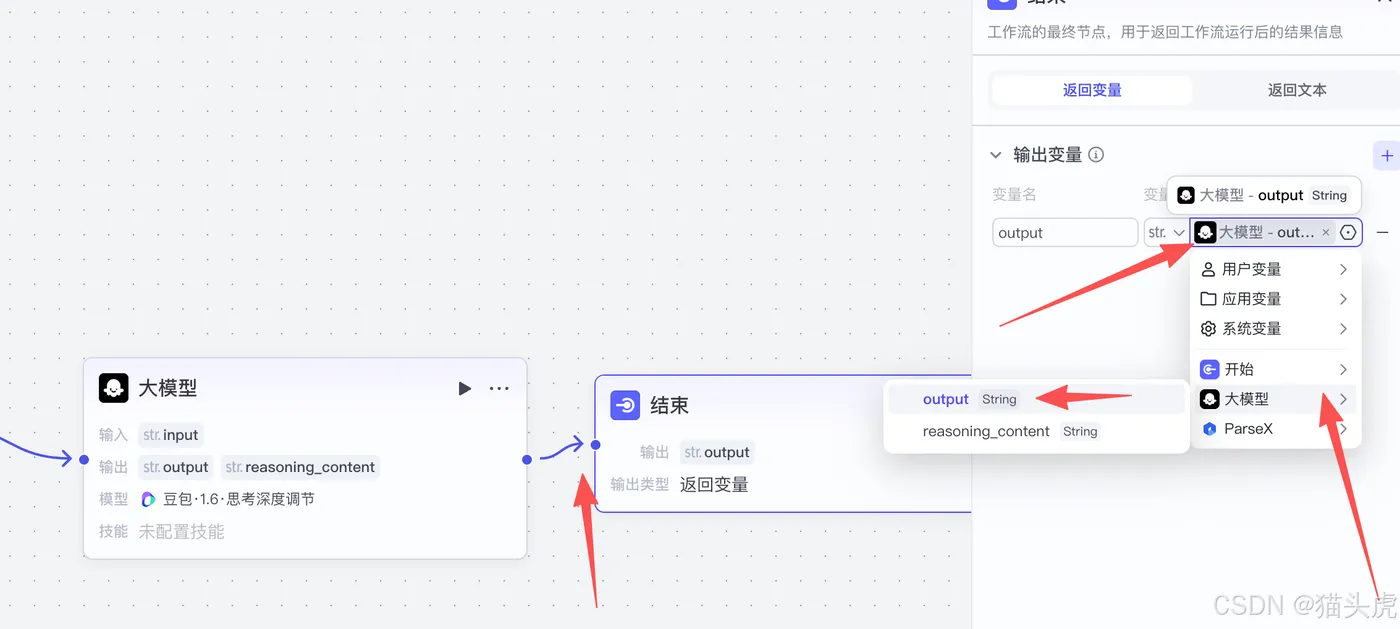
启动工作流:
在配置完毕后,点击“试运行”并上传PDF文件,即可启动工作流并开始处理。
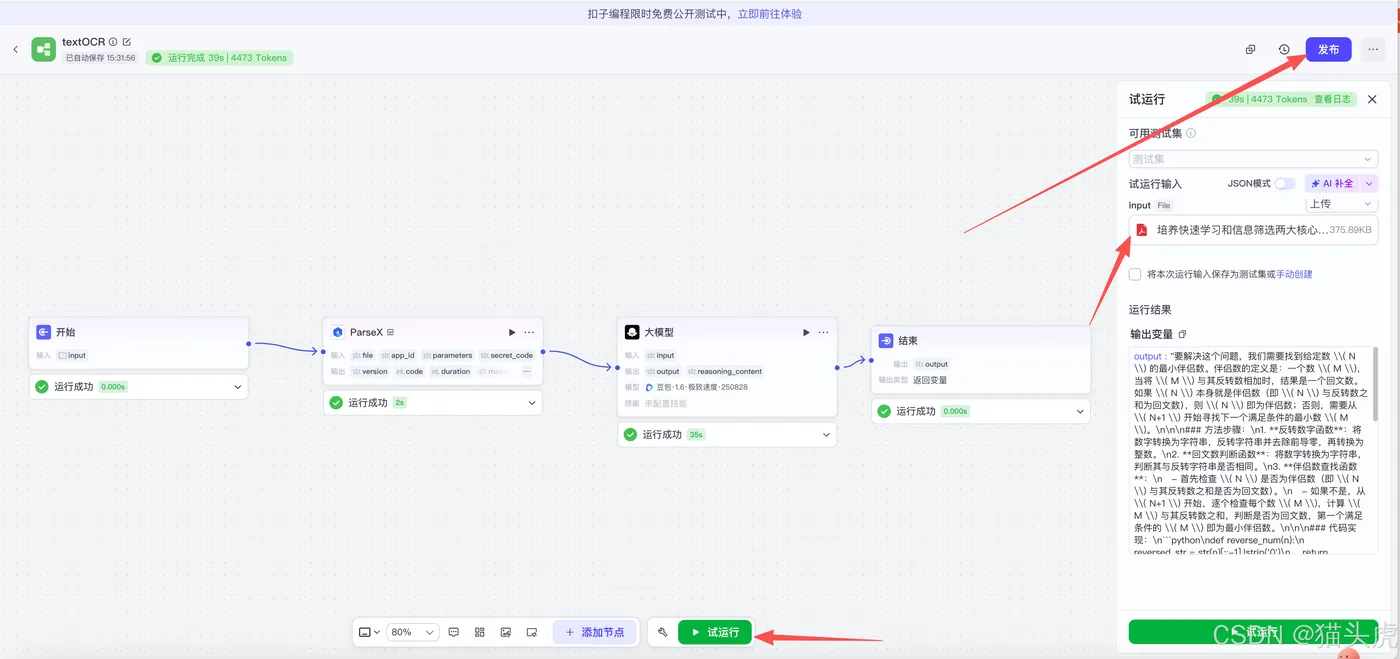
一旦数据状态正常,即可点击右上角的“发布”按钮,工作流便可直接在智能体中使用。
输出格式微调:
在大模型模块中,还可以调整提示词{
{input}},来控制工作流输出不同的数据格式。

七、实测图表解析能力
在这一部分,我们将通过TextIn xParse进行图表数据的结构化处理,并通过大模型还原为可识别的表格数据。
原图:
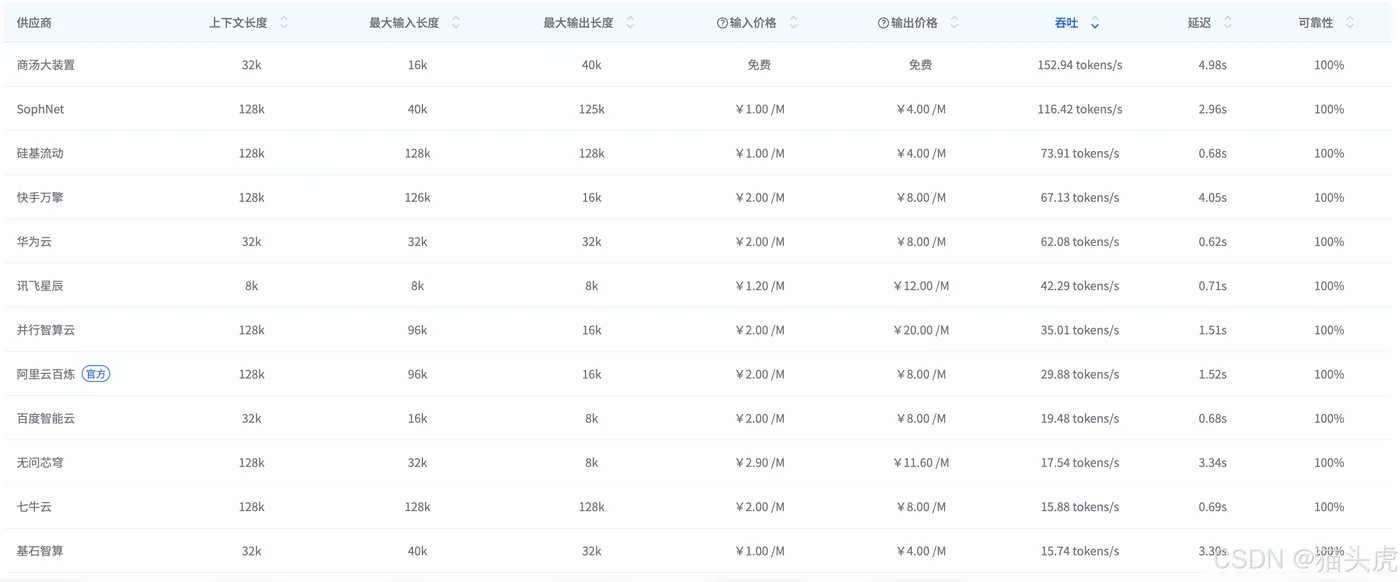
随后,使用大模型对图表数据进行还原,生成的表格如下,经过数据比对,能够确认其识别精度达到100%,数据准确无误:
还原后的表格:
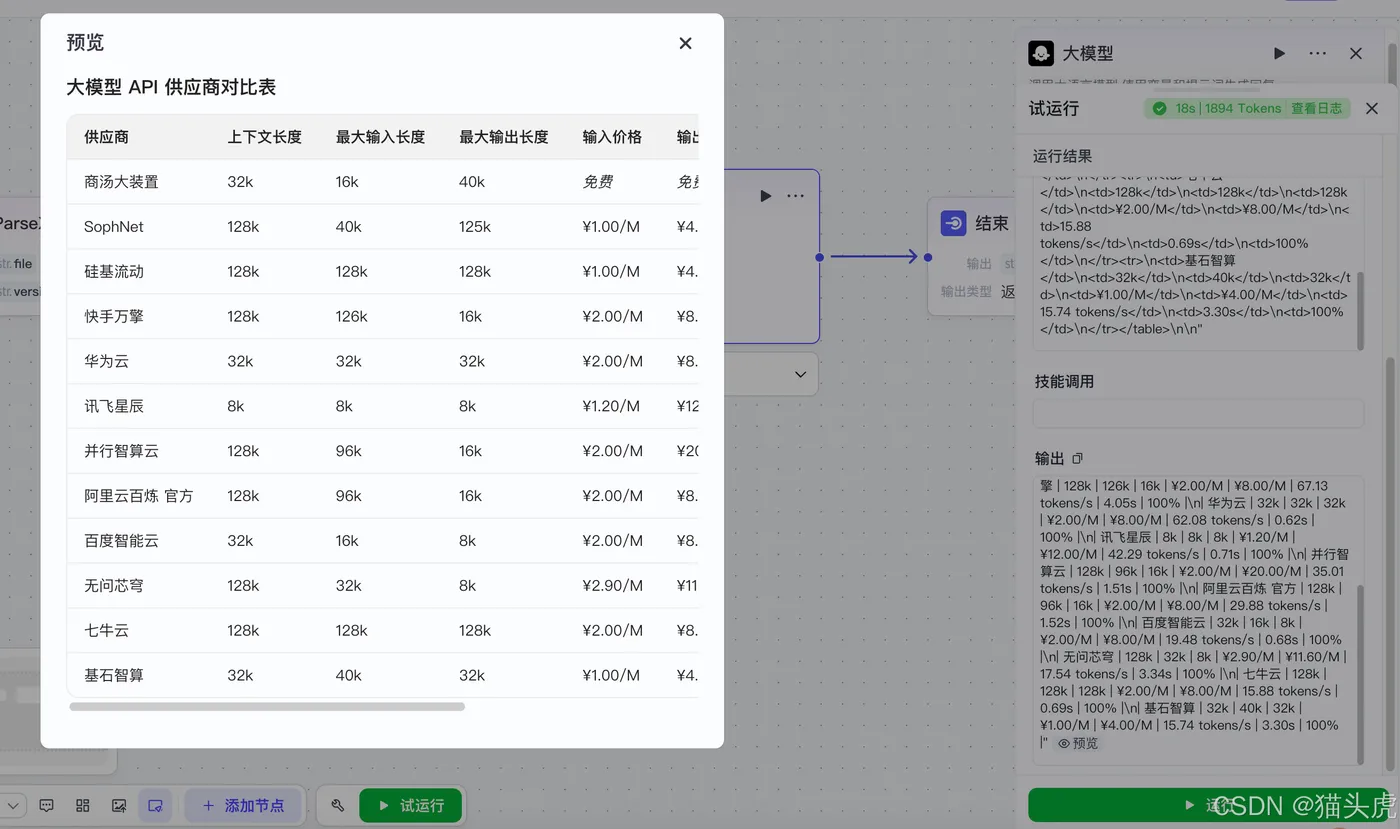
接下来,我们使用另一张试验数据表进行测试,进一步验证其解析能力。
试验数据表:
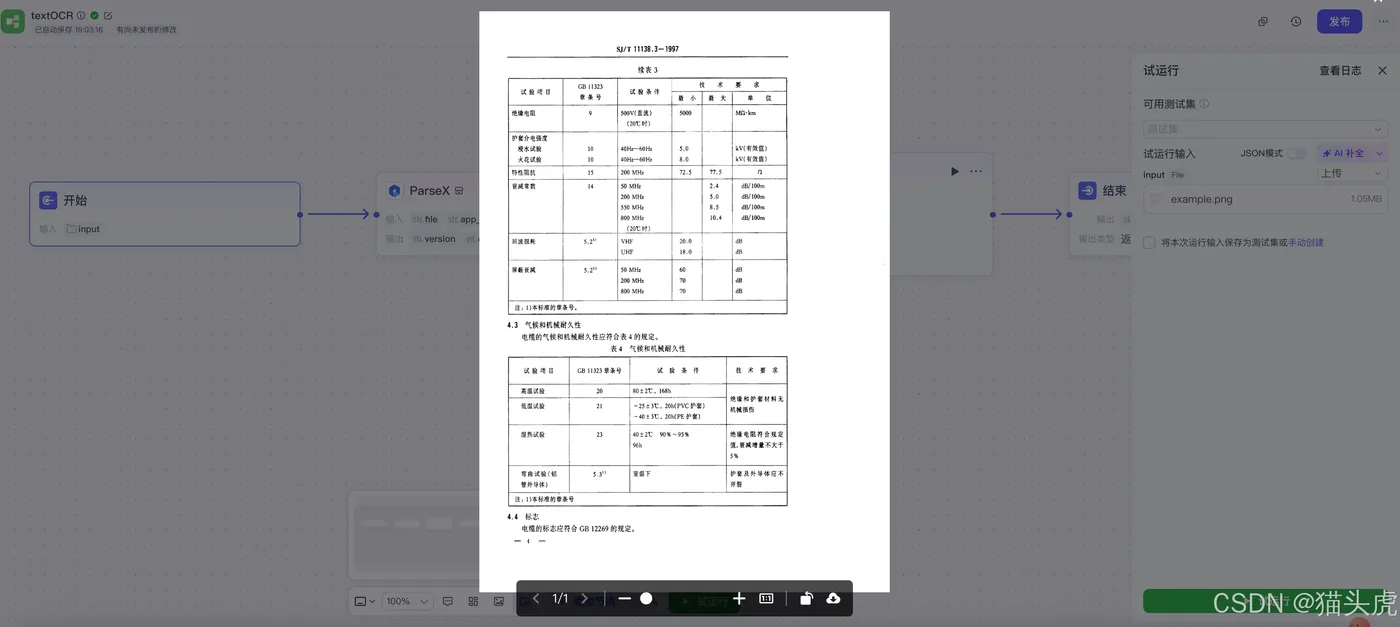
大模型还原后的数据表如下,经过比对,数据还原的精准度得到了确认:
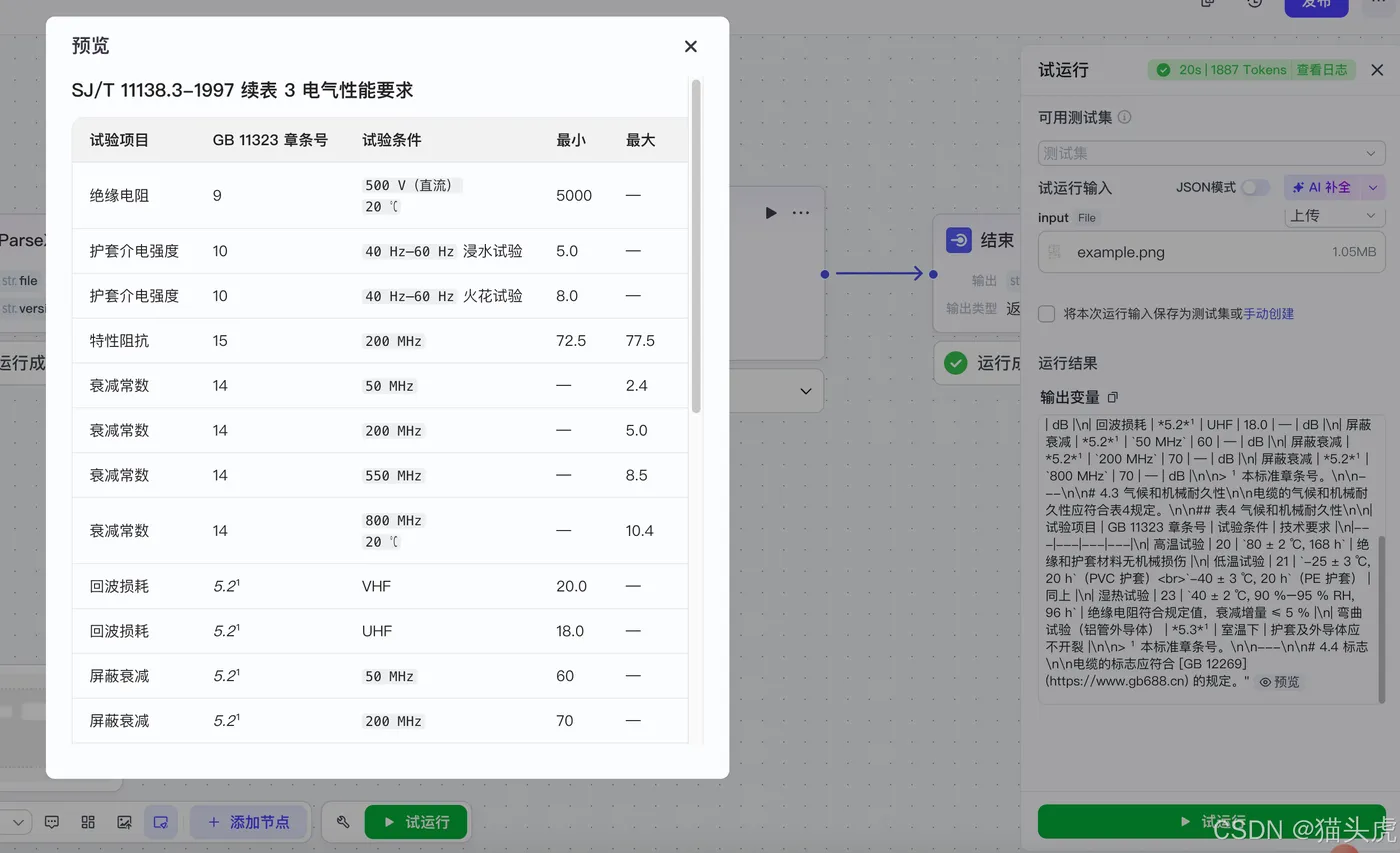
通过以上两个案例,我们可以看到无论是图表数据还是试验数据,TextIn xParse与大模型的结合都能够精准地进行结构化并还原数据。
接下来,我们将尝试解析一张发票数据,看看它的解析效果如何?
八、发票数据解析能力
为进一步展示TextIn xParse的强大解析能力,我们从网上找到了一张老旧发票,使用它来测试TextIn xParse在发票数据解析中的表现。
原发票:

经过TextIn xParse处理后,系统返回的识别结果如下:
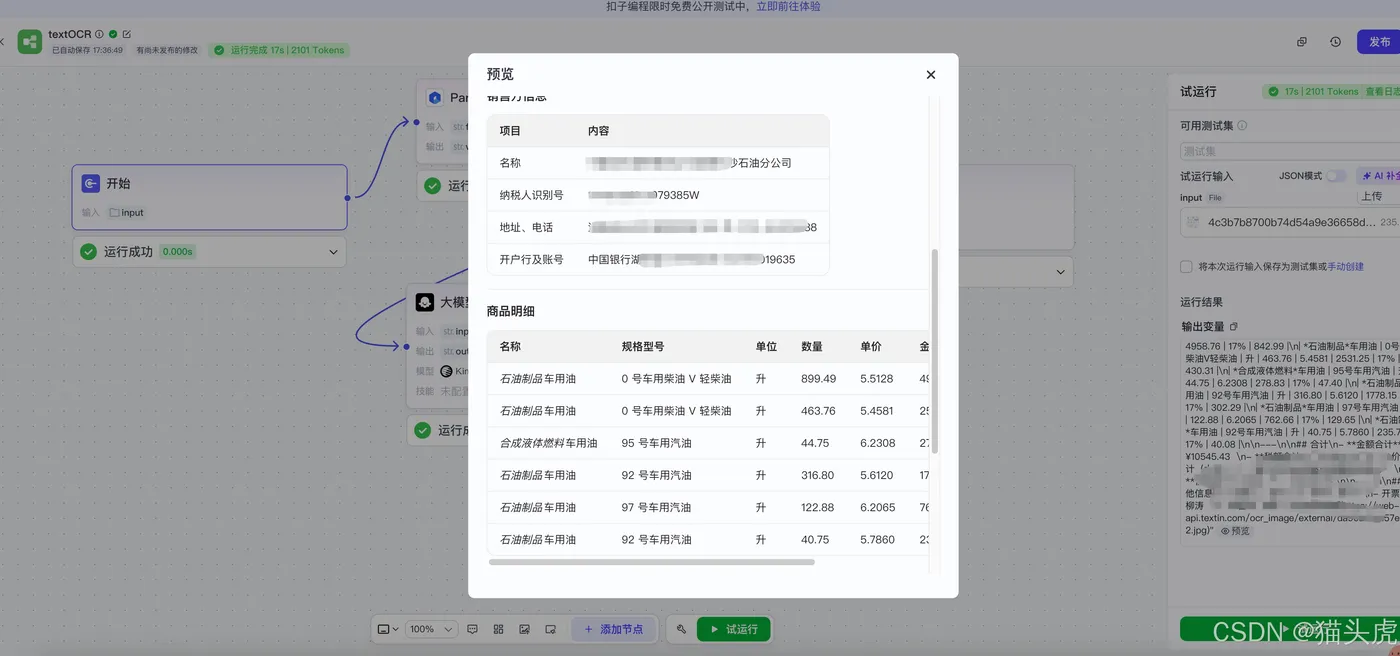
从这一实测案例中可以看出,TextIn xParse对于发票等复杂文档的结构化解析表现非常优秀,能够准确地提取并解析关键信息。
九、TextIn API 接入演示
除了可以通过智能体和工作流使用TextIn大模型加速器外,我们还可以通过在线体验快速上手,或者在自己的编程框架项目中直接调用TextIn API。TextIn API支持多种编程语言的接入,具有很高的灵活性,方便我们在不同的开发环境中使用。以下是一个用Go语言调用TextIn API的示例,展示如何快速将图片中的内容提取为结构化数据。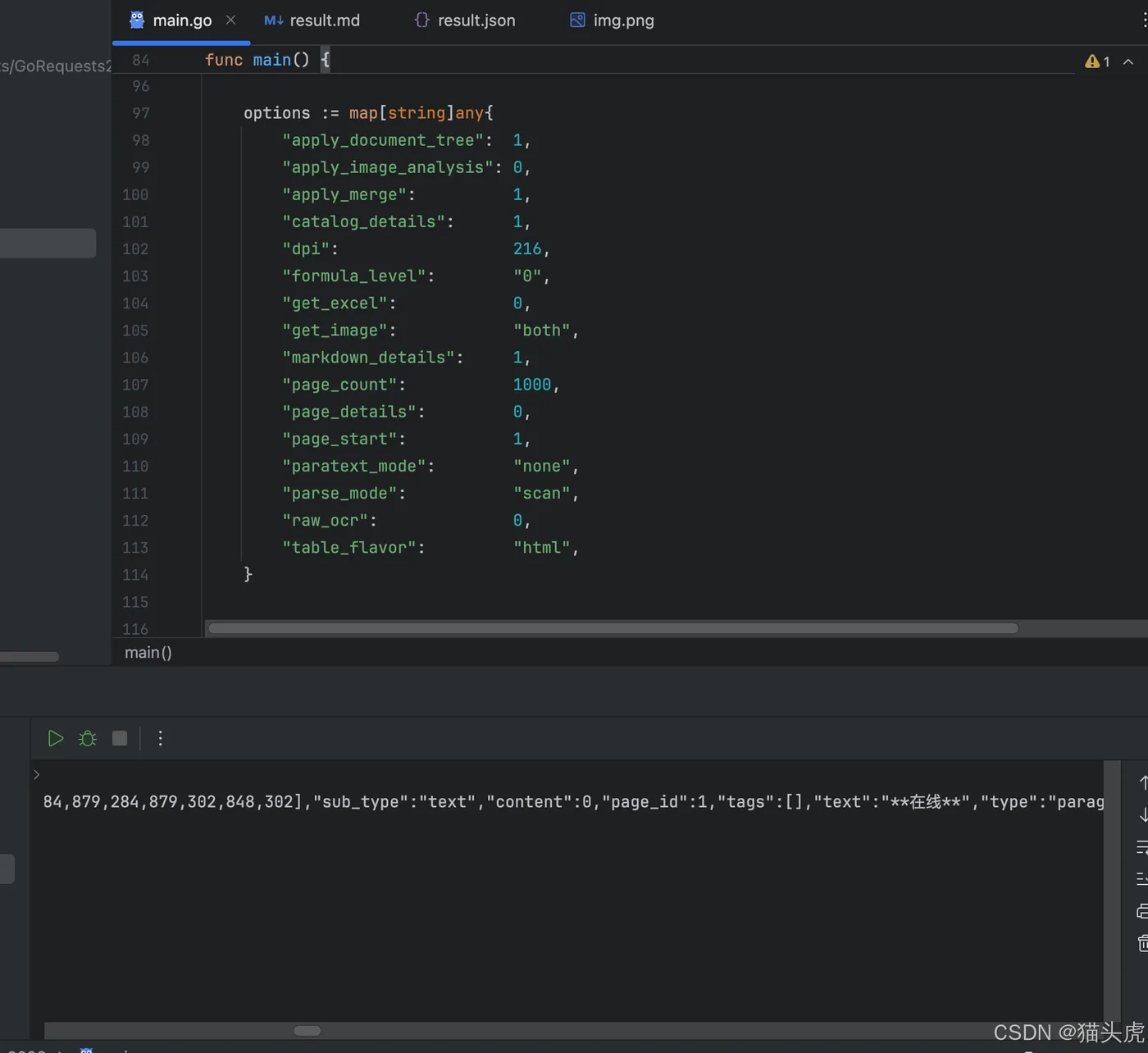
以下是完整的Go语言代码示例:
package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"net/http"
"net/url"
"os"
)
const (
// baseURL 是TextIn API的基础URL,用于发送请求
baseURL = "https://api.textin.com/ai/service/v1/pdf_to_markdown"
)
// OCRClient 定义OCR客户端结构体,用于配置并发送请求
type OCRClient struct {
appID string // 应用ID,用于标识应用
secretCode string // 秘钥,用于验证应用身份
baseURL string // API的基础URL
}
// NewOCRClient 创建一个新的OCRClient实例,并返回该实例的指针
func NewOCRClient(appID, secretCode string) *OCRClient {
// 返回一个OCRClient实例,包含appID、secretCode和baseURL
return &OCRClient{
appID: appID,
secretCode: secretCode,
baseURL: baseURL,
}
}
// Recognize 执行OCR识别请求,处理传入的PDF文件内容并返回解析后的响应
func (c *OCRClient) Recognize(fileContent []byte, options map[string]any) ([]byte, error) {
// 解析基础URL
baseURL, err := url.Parse(c.baseURL)
if err != nil {
// 如果URL解析失败,返回错误信息
return nil, fmt.Errorf("invalid base URL: %v", err)
}
// 将options中的参数添加到URL查询字符串中
q := baseURL.Query()
for key, value := range options {
// 遍历options,将键值对格式化为字符串并添加到查询参数中
q.Set(key, fmt.Sprintf("%v", value))
}
baseURL.RawQuery = q.Encode() // 将查询参数添加到URL中
// 创建HTTP POST请求,发送PDF文件内容
req, err := http.NewRequest("POST", baseURL.String(), bytes.NewReader(fileContent))
if err != nil {
// 如果请求创建失败,返回错误信息
return nil, fmt.Errorf("failed to create request: %v", err)
}
// 设置请求头,包含appID和secretCode,用于身份验证
req.Header.Set("x-ti-app-id", c.appID)
req.Header.Set("x-ti-secret-code", c.secretCode)
// 设置请求体的Content-Type为文件流
req.Header.Set("Content-Type", "application/octet-stream")
// 创建HTTP客户端并发送请求
client := &http.Client{
}
resp, err := client.Do(req)
if err != nil {
// 如果请求发送失败,返回错误信息
return nil, fmt.Errorf("failed to send request: %v", err)
}
defer resp.Body.Close() // 确保响应体在函数结束时关闭
// 读取响应体
body, err := io.ReadAll(resp.Body)
if err != nil {
// 如果读取响应体失败,返回错误信息
return nil, fmt.Errorf("failed to read response: %v", err)
}
// 检查响应的状态码,确保请求成功
if resp.StatusCode != http.StatusOK {
// 如果状态码不是200 OK,返回错误信息
return nil, fmt.Errorf("request failed with status code %d: %s", resp.StatusCode, string(body))
}
// 返回解析后的响应体
return body, nil
}
func main() {
// 示例:配置appID和secretCode,创建OCRClient实例
client := NewOCRClient("bff82d62**********c5bce256e", "9ba*******************ebd")
// 读取PDF文件,方式一:从本地读取
fileContent, err := os.ReadFile("img.png")
if err != nil {
// 如果文件读取失败,抛出错误
panic(err)
}
// 方式二:使用URL方式(需要将headers中的Content-Type改为'text/plain')
// fileContent := []byte("https://example.com/path/to/your.pdf")
// 设置请求的选项
options := map[string]any{
"apply_document_tree": 1, // 是否应用文档树
"apply_image_analysis": 0, // 是否进行图像分析
"apply_merge": 1, // 是否合并表格
"catalog_details": 1, // 是否提取目录
"dpi": 216, // DPI设置
"formula_level": "0", // 公式提取级别
"get_excel": 0, // 是否提取Excel表格
"get_image": "both", // 提取图片格式
"markdown_details": 1, // 是否提取详细的Markdown
"page_count": 1000, // 提取的页面数量
"page_details": 0, // 页面详细信息
"page_start": 1, // 开始页面
"paratext_mode": "none", // 文字模式
"parse_mode": "scan", // 扫描模式
"raw_ocr": 0, // 是否启用原始OCR
"table_flavor": "html", // 表格的格式
}
// 调用Recognize方法进行OCR识别
response, err := client.Recognize(fileContent, options)
if err != nil {
// 如果识别失败,抛出错误
panic(err)
}
// 将完整的JSON响应保存到result.json文件
if err := os.WriteFile("result.json", response, 0644); err != nil {
// 如果保存文件失败,抛出错误
panic(err)
}
// 解析JSON响应以提取markdown内容
var jsonResponse map[string]interface{
}
if err := json.Unmarshal(response, &jsonResponse); err != nil {
// 如果解析JSON失败,抛出错误
panic(err)
}
// 提取并保存markdown内容到result.md文件
if result, ok := jsonResponse["result"].(map[string]interface{
}); ok {
if markdown, ok := result["markdown"].(string); ok {
if err := os.WriteFile("result.md", []byte(markdown), 0644); err != nil {
// 如果保存markdown失败,抛出错误
panic(err)
}
}
}
// 打印JSON响应内容
fmt.Println(string(response))
}
此外,TextIn也提供了一些开源项目,供开发者参考使用。下面是一个开源项目的示例:

通过以上实测案例,我们可以看出,TextIn大模型加速器与火山引擎平台的结合,在多种文档数据的结构化处理与解析中表现出色,为用户提供了一个灵活且强大的解决方案。
十、哪些场景适合使用TextIn大模型加速器?
应用场景

从实际应用角度来看,TextIn大模型加速器主要服务于两大核心用户群体:
第一类专业场景用户:主要面向财务、法务、采购、人力、仓储等业务部门,这些岗位日常需要处理大量纸质文档、扫描件、PDF文件和图片资料。核心痛点是被各种格式的文档折磨,需要进行机械重复的信息录入和审核工作。典型应用场景包括合同审核、发票处理、送货单录入、运单管理等,特点是文档价值高、格式多样,需要快速结构化录入来提升效率。对这类用户,TextIn的价值定位是效率引擎,通过AI替代重复性工作,让人员专注于高价值决策。
第二类数字化转型团队:主要面向企业AI中台、RAG/Agent项目组等技术团队,这些团队在传统"做表单"式数字化遇到瓶颈后,需要向智能化升级。他们处理的文档特征是多语言、知识密集型,需要深度语义理解能力。使用场景涵盖流程自动化到智能决策升级的整个链条。对这类用户,TextIn的价值定位是AI基建,通过RAG+Agent技术组合,让数字化从"表单"时代迈向"智能"时代。
客户案例
从实际落地情况来看,TextIn大模型加速器已经在多个主流行业的头部厂商中得到了广泛应用和验证。
在金融领域,多家银行和保险公司采用TextIn处理贷款合同、保单等核心文档;
在制造业,头部企业将其应用于供应链单据的自动化处理;
在电商和物流行业,平台型企业利用TextIn实现了订单、运单等文档的智能解析;
在政务和医疗领域,相关机构也通过TextIn提升了文档处理效率和准确性。
这些成功案例充分证明,无论是追求效率提升的业务部门,还是致力于智能化转型的技术团队,TextIn大模型加速器都能提供强有力的技术支撑,帮助用户在各自的数字化道路上取得实质性进展。
总结
本文详细介绍了如何通过TextIn xParse插件和火山引擎平台,构建高效的文档结构化处理工作流。我们展示了如何创建智能体应用、配置工作流节点,并通过大模型加速器实现精确的图表、表格和发票数据的解析与还原。无论是通过工作流、API接口还是智能体应用,TextIn xParse都展现了其强大的数据处理能力和高效的文档解析能力。
从实测结果来看,TextIn xParse与火山引擎平台结合,为用户提供了高效、精准的文档结构化处理方案,无论是在企业文档处理还是开发者应用场景中,都能大大提升工作效率。


