
准确性:答案可信度不足
幻觉问题
即使检索到相关文档,大模型仍可能脱离文档内容编造答案(尤其在文档信息模糊或矛盾时)。例如如:用户问“某基金近3年收益率”,模型可能捏造数据而非引用检索到的报告。
检索噪声干扰
相似度搜索返回的文档片段可能包含无关信息,导致模型生成答案时被误导。例如:检索到10篇文档,其中3篇主题相关但含错误数据,模型可能融合错误信息。
细粒度理解缺失
模型难以精准理解数字、日期、专业术语的上下文含义,导致关键信息误用。例如:将“预计2025年增长10%”误解为历史数据。
召回率:关键信息漏检
语义匹配局限
传统向量搜索依赖语义相似度,但用户问题与文档表述差异大时漏检(如术语vs口语)。例如:用户问“钱放货币基金安全吗?”可能漏检标题为“货币市场基金信用风险分析”的文档。
长尾知识覆盖不足
低频、冷门知识因嵌入表示不充分,在向量空间中难以被检索到。例如:某小众金融衍生品的风险说明文档未被召回。
多跳推理失效
需组合多个文档片段才能回答的问题(如因果链),单次检索难以关联分散的知识点。例如:“美联储加息如何影响A股消费板块?”需先检索加息机制,再关联A股消费板块。
复杂文档解析:信息提取瓶颈
非结构化数据处理
- 表格/图表:文本分块会破坏表格结构,导致行列关系丢失(如财报中的利润表)。
- 公式/代码:数学公式或程序代码被错误分段,语义完整性受损。
- 扫描件/图片:OCR识别错误率高,尤其对手写体或模糊文档。
上下文割裂问题
固定长度分块(如512字符)可能切断关键上下文:
分块1结尾:“...风险因素包括:”
分块2开头:“利率波动、信用违约...” → 模型无法关联分块1的提示语。
文档逻辑结构丢失
标准分块策略忽略章节、段落、标题的层级关系,影响知识图谱构建。例如:将“附录”中的备注误认为正文结论。
RAG的分块策略与选择
选择合适的分块策略,是解决RAG实际应用中准确性、召回率与复杂文档解析等痛点最直接有效的方式,也是我们建设RAG系统最关键的一个环节。最常见的RAG分块策略包括:固定大小分块、语义分块、递归分块、基于文档结构的分块、基于LLM的分块。
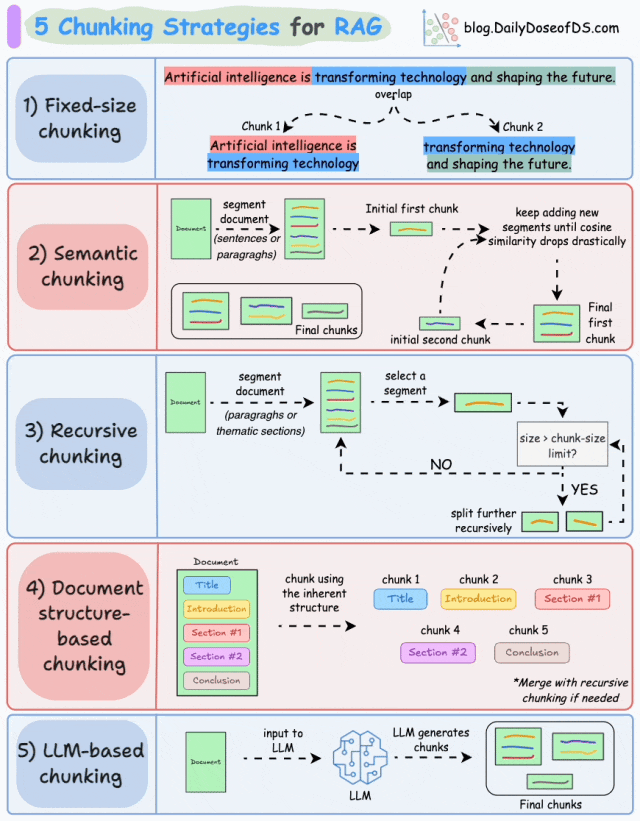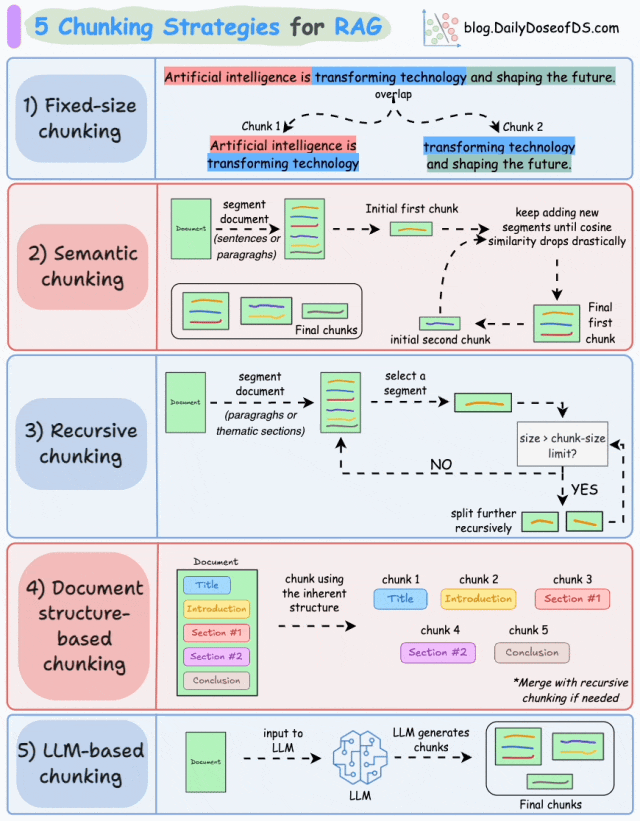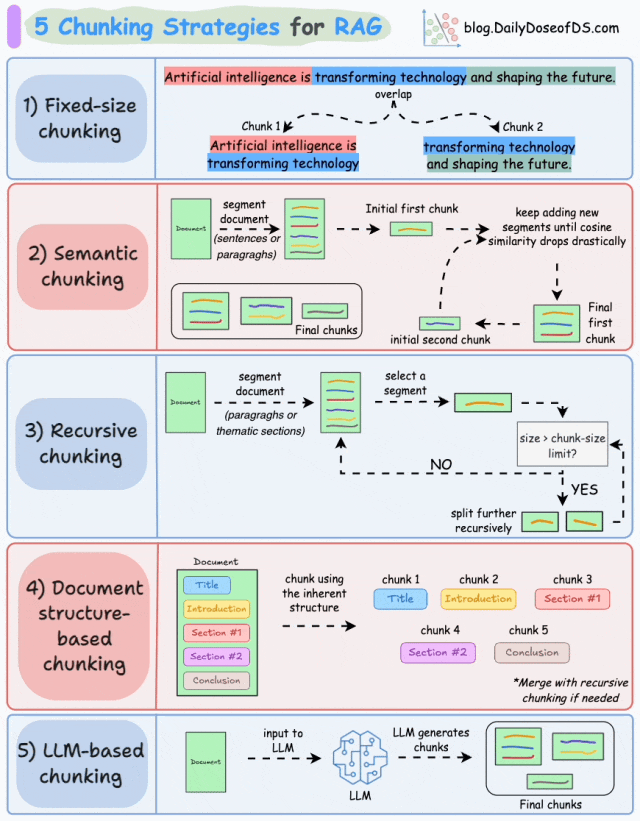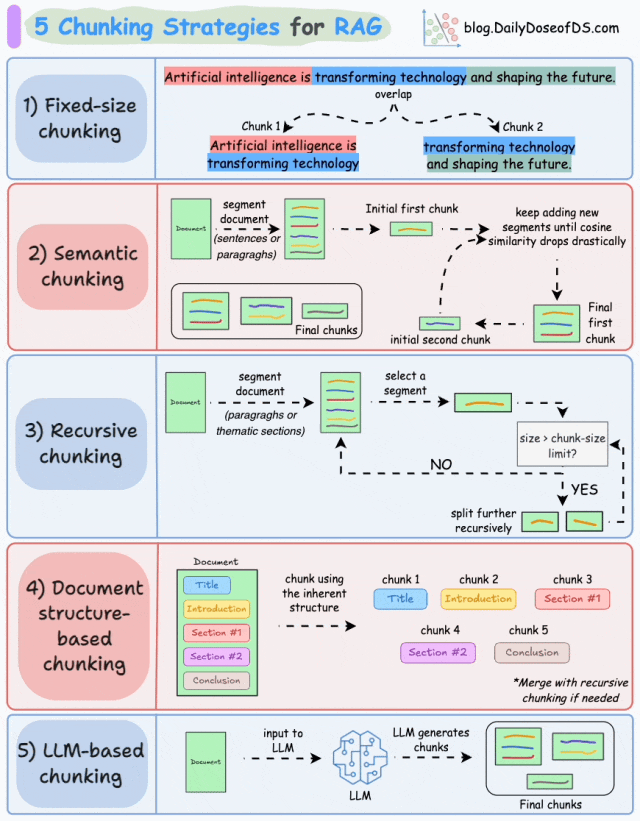
RAG五种分块策略(图片来源:DailyDoseofDS)

