引言
强化学习(Reinforcement Learning, RL)已经成为提升大语言模型(Large Language Models, LLM)推理能力的核心技术之一。现代 RL 训练流程使模型能够解决困难的数学问题、编写复杂代码和进行多模态推理。实践中,一种被广泛采用的方法是基于组的策略优化(group‑based policy optimization):对每个提示采样多个回复,并在组内进行奖励归一化。 然而,尽管该方法效果显著,稳定且高性能的策略优化仍然困难。关键挑战在于 token 级重要性比率(importance ratio)的高方差,尤其是在 MoE 模型中。该比率衡量当前策略偏离生成训练样本的行为策略的程度。当该比值波动过大时(例如由专家路由变化或长序列生成导致),策略更新会变得噪声巨大、不稳定。
现有方法如 GRPO(token-level clipping)和 GSPO(sequence-level clipping)采用硬剪切(hard clipping):当重要性比率超出范围时,梯度直接被截断。尽管能避免灾难性更新,但有两个固有缺点:
学习信号丢失:被剪切区间外的所有梯度全部丢弃。对于 GSPO,只要有少数 token 异常,可能导致整个序列的梯度都被抛弃。
难以取得较好平衡:剪切范围太窄 → 大量样本没有梯度;太宽 → off‑policy 梯度噪声破坏稳定性。这在 MoE 模型里尤为明显。
因此,GRPO 和 GSPO 常常难以兼顾稳定性、样本效率和收敛效果。为解决这些问题,我们提出Soft Adaptive Policy Optimization(SAPO),一种稳定且性能更优的大语言模型强化学习方法。SAPO 使用平滑、温度控制的门控函数替代硬剪切,在保持稳定性的同时保留更多有效梯度。其特点包括:连续信任域(无硬剪切不连续性)
序列级一致性(类似 GSPO,但不丢弃整段序列)
token 级自适应性(弱化异常 token)
非对称温度设计(正负 tokens 差异化处理)
这些设计让 SAPO 能够达到稳定且有效的学习。
Soft Adaptive Policy Optimization
SAPO 优化以下代理目标: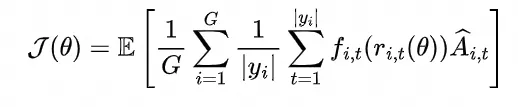


为什么 SAPO 有效 从门控函数出发



2大规模 RL:Qwen3‑VL
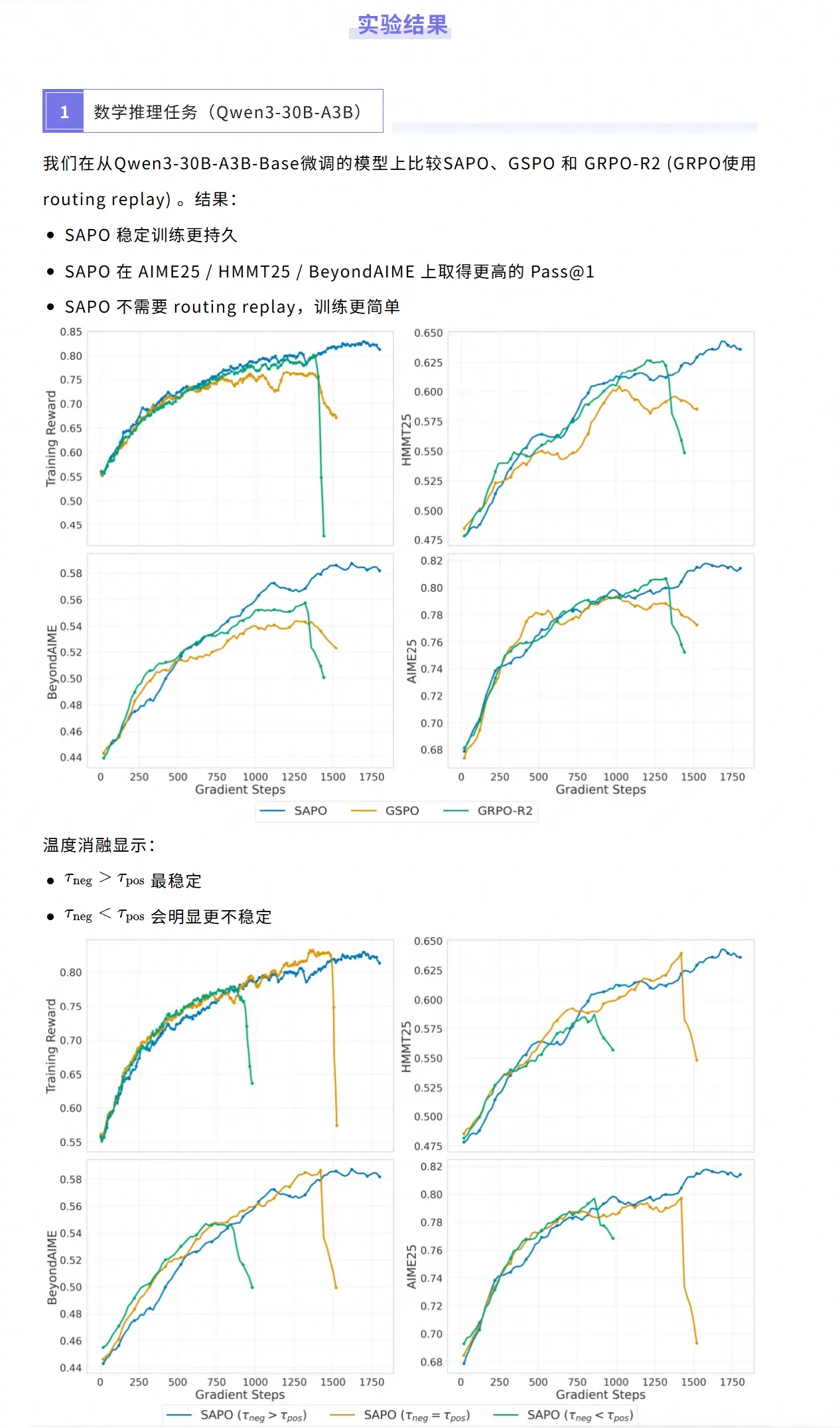
SAPO 在不同规模的 dense 和 MoE 模型上均有提升。为了进行比较,我们在数学、编码、逻辑和多模态任务的混合上训练 Qwen3-VL-30B-A3B 的一个checkpoint。评估基准包括:
AIME25(数学推理)
LiveCodeBench v6 (代码生成)
ZebraLogic(逻辑推理)
MathVision(多模态数学推理)
结果:SAPO 在相同算力预算下优于 GSPO / GRPO‑R2。

SAPO 对于强化学习的意义
SAPO 提供了一个实用的方法来稳定和增强大语言模型强化学习训练:
更稳定连续的信任域
更合理的序列级 + token 级联合建模
提升样本效率
不对称温度设计提升训练稳定性
我们期待SAPO成为未来大语言模型强化学习中的基础技术之一。
完整技术细节见论文:https://arxiv.org/abs/2511.20347