
作者:隰宗正(霜键)
01 从“看”指标到“懂”指标的进化
1.1 “指标洪水”与“分析赤字”的困境
随着业务全面上云和微服务架构的普及,我们正迎来一个“大观测”的时代。系统的每一个角落都在产生海量的指标数据(Metrics),它们是衡量系统健康度的关键。然而,数据的极大丰富也带来了新的困境——“指标洪水”。运维团队和 SRE 工程师们发现自己被淹没在无穷无尽的监控大盘和告警信息中,患上了“告警&大盘疲劳症”。
传统的监控系统本质上是“数据展示平台”。它们能够准确地将数据从时序数据库中取出,绘制成曲线,然后呈现给用户。
这种模式隐含了一个关键假设:用户知道应该看什么,并且能够从纷繁复杂的曲线中自行解读出问题的根源。在系统规模尚小、维度较少时,这套方法尚能奏效。
但在今天,一个服务动辄拥有成百上千个实例,每个实例又有数十个维度的标签(地域、可用区、版本号等),这意味着一个指标背后是数万甚至数百万条独立的时间序列。当问题发生时,依赖人眼去逐一排查,无异于大海捞针。我们面临着严重的“分析赤字”:拥有海量数据,却缺乏从中高效提取有效信息的能力。
1.2 从被动展示到主动引导
要走出这一困境,监控工具必须完成一次核心范式的转变:从被动的“数据展示”进化为主动的“分析引导”。我们认为,一个现代化的指标分析平台,其价值不应仅仅是“看”指标,更核心的是帮助用户“懂”指标。它应该像一个经验丰富的 SRE 专家,能够自动在海量数据中发现异常,并主动引导用户一步步定位问题的根源。
MetricSet Explorer 正是基于这一理念设计的。它的核心思路是将成熟的机器学习算法与运维专家的排障经验相结合,将复杂的分析过程产品化、自动化。我们构建了三大智能分析引擎,它们共同构成了一个强大的分析“漏斗”,帮助用户从海量的指标数据中快速筛选、聚焦并定位问题。

异常检测引擎:作为“漏斗”的入口,它自动巡检所有指标,通过统计算法识别出那些行为模式异于常规的指标,将它们高亮呈现在用户面前,完成从“普遍”到“异常”的第一次筛选。

时序聚类引擎(智能分组):当用户需要理解一个维度下不同个体的行为模式时(例如上千个 Pod 的 CPU 使用率),该引擎能自动将成百上千条曲线按照形态相似度进行分组,帮助用户快速识别出系统中的“几类玩家”,完成从“个体”到“群体”的模式识别。

根因定位引擎(智能下钻):这是“漏斗”最窄的一环,也是技术含量最高的部分。当用户圈定一个异常时间段后,该引擎会分析所有维度组合对整体异常的贡献度,最终以“根因评分”的方式,直接告诉用户哪个维度组合是问题的“罪魁祸首”。

这三大引擎协同工作,将传统监控中高度依赖人工经验的分析过程,转变为一套自动化的、可复现的分析流程。
02 界面布局与功能区域

产品界面主要分为三个区域:顶部工具栏、指标概览区和详情分析区。这样的布局设计既保证了信息的层次性,又便于用户在不同分析场景间快速切换。

顶部工具栏是整个系统的控制中心,从左到右依次是:存储选择器、指标搜索、标签过滤器和高级功能区。存储选择器允许用户在多个数据源间切换,这在跨集群或跨环境分析时特别有用。指标搜索支持模糊匹配,无论是通过指标 ID、中文名还是英文名,都能快速定位目标指标。

标签过滤器是一个强大但易用的功能。在可观测性领域,标签(Label)是数据的核心维度,比如服务名、地域、实例 ID 等。MetricSet Explorer 的全局标签过滤器能够同时作用于所有指标,让用户可以轻松聚焦到特定范围的数据上。
高级功能区集成了三个实用功能:
功能 |
说明 |
典型场景 |
准星联动 |
多个图表的鼠标悬停位置同步 |
对比分析多个指标在同一时间点的表现 |
时间对比 |
叠加显示历史时段的数据曲线 |
环比分析,识别周期性模式 |
异常检测 |
基于检测算法智能标注异常点 |
快速发现数据中的异常波动 |
03 指标概览模式
进入系统后,首先看到的是指标概览页。产品支持两种展示方式:普通视图和异常视图。
在普通视图下,指标按照黄金指标和基础指标分类展示。黄金指标通常是对系统健康度最有代表性的几个核心指标,比如请求延迟、错误率、吞吐量等。这种分类方式源于 SRE 实践中的最佳实践,能够帮助用户快速抓住系统的关键状态。

当启用异常检测功能后,界面自动切换到异常视图。此时系统会对所有指标运行异常检测算法,并按照异常评分从高到低排序。对于每个指标,异常区域会通过特殊的颜色高亮显示,异常评分也会清晰标注。这个功能在故障排查场景下尤其有用——当告警触发时,运维人员可以快速启用异常检测,系统会自动将最可能有问题的指标排在前面。

概览页的每个指标卡片不仅展示曲线,还提供了快捷操作入口。点击卡片可以进入详情分析模式,开始更深入的探索。
04 详情分析模式
详情分析是 MetricSet Explorer 的核心能力所在。当选中一个或多个指标后,界面进入详情模式,此时可以看到更大的图表以及三个强大的分析标签页:下钻分析、智能分组和智能下钻。
4.1 下钻分析
下钻分析是最常用的探索方式。它的逻辑很直观:从整体到局部,逐层深入。
举个例子,假设我们发现请求延迟指标出现了尖峰。首先在概览页点击该指标进入详情,此时看到的是全局聚合后的曲线。接下来选择一个维度进行下钻,比如按“服务”分组。系统会立即展示每个服务的延迟曲线,很可能我们会发现某一个服务的延迟特别高。

继续深入,选中这个异常服务,再按“调用类型”下钻。

逐层分析下去,最终可以精确定位到具体的问题调用。MetricSet Explorer 支持多层级的下钻,每一层都会保留上一层的过滤条件,形成完整的分析链路。
产品还支持 ALL 模式下钻,这是一个非常实用的功能。在 ALL 模式下,系统会自动遍历所有可下钻的维度,找出数据分布差异最大的那些维度。这在维度很多、不确定从哪个角度分析时特别有帮助。

4.2 智能分组
有些时候,我们关心的不是具体某个维度值的表现,而是希望发现数据中存在的模式或群组。智能分组功能正是为此设计。

智能分组基于时序聚类算法工作。用户选择需要分析的维度(可以是多个维度的组合),系统会将所有时间序列按照形态相似度进行聚类。最终呈现的结果是若干个群组,每个群组包含形态相似的曲线。
这个功能在容量规划、资源优化场景下特别有价值。比如分析大量实例的 CPU 使用率时,通过智能分组可以快速识别出高负载、中负载和低负载三类实例,进而针对性地进行资源调整。
聚类结果以表格形式呈现,每一行代表一个群组,表格列包括:
- 群组 ID:自动分配的群组编号
- 成员:包含属于该群组的时间序列数量、该群组成员的典型维度值
- 曲线预览:该群组的代表性曲线
点击任一群组可以展开查看详细的成员列表和完整曲线对比。
4.3 智能下钻
智能下钻是 MetricSet Explorer 最具技术含量的功能,它能够自动进行根因定位。
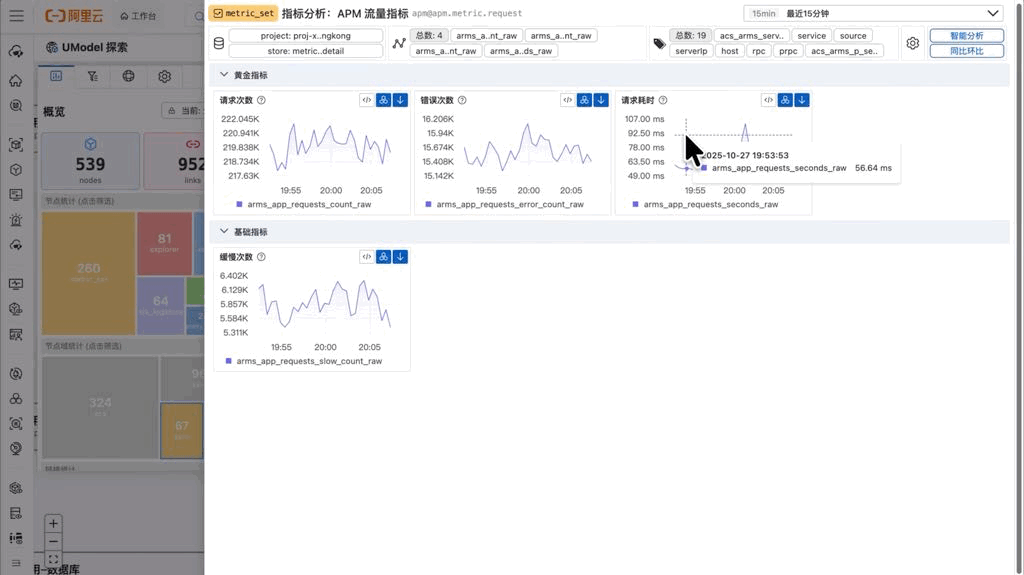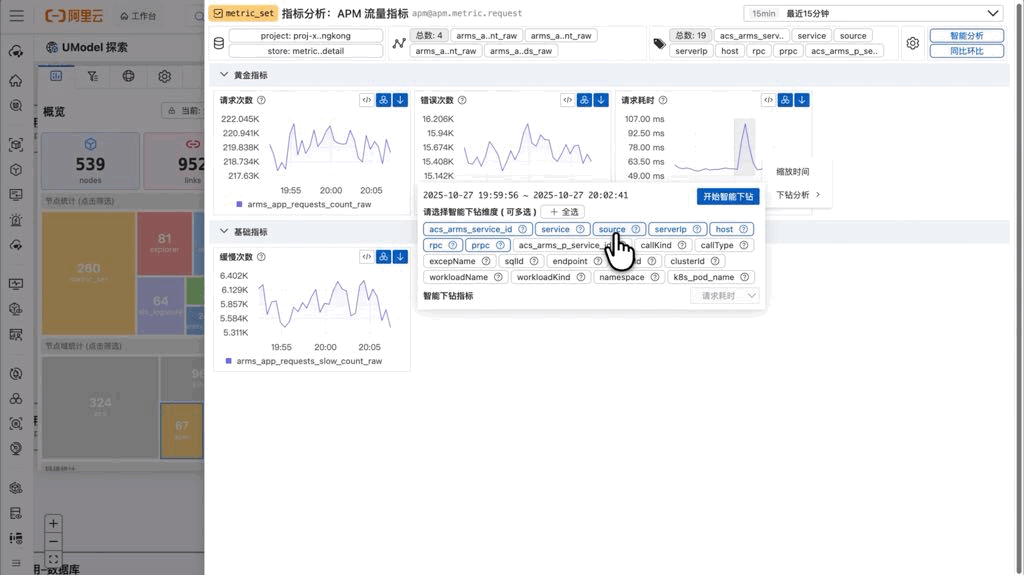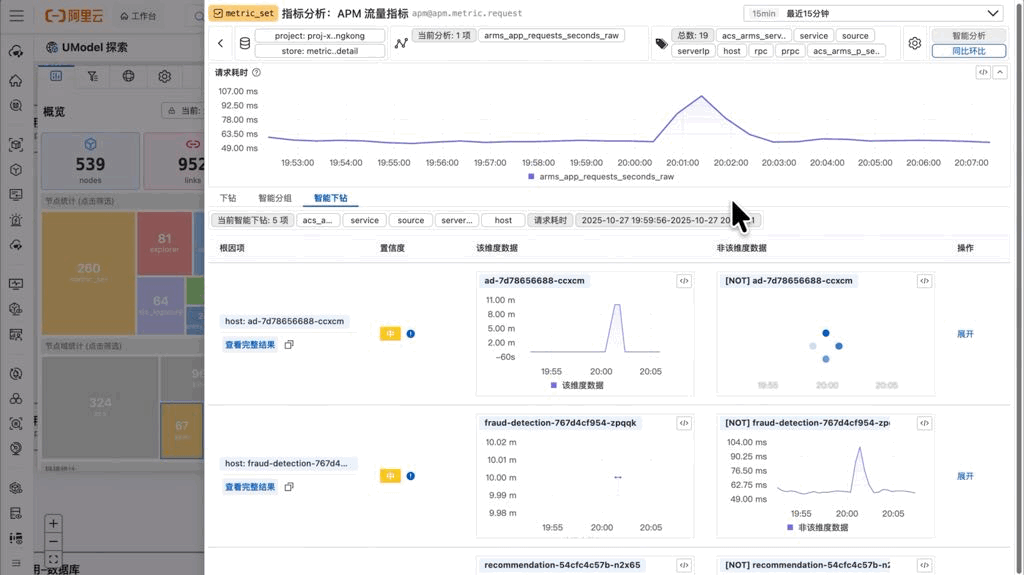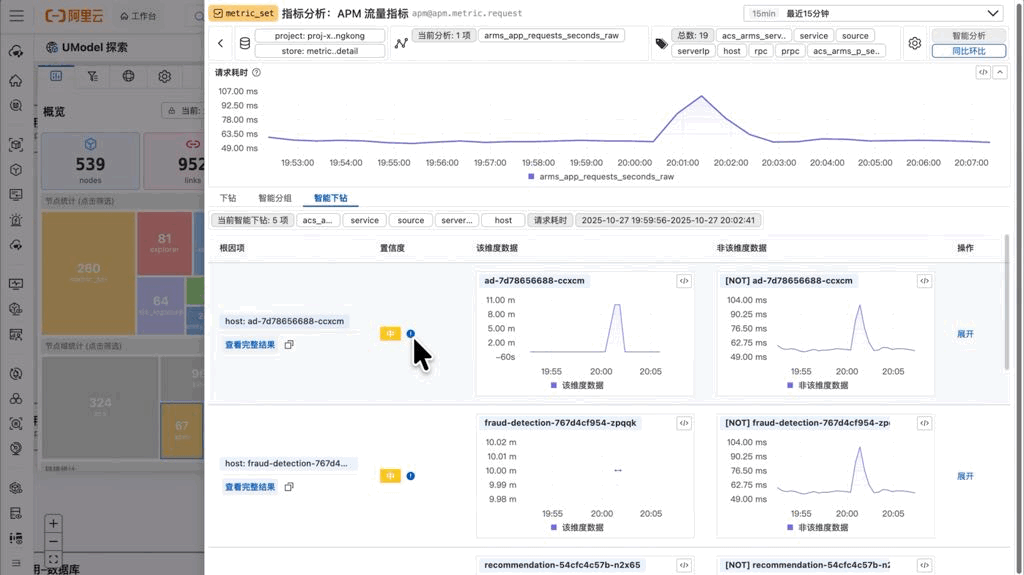
使用这个功能时,用户需要先在时间轴上框选一个异常时间段。系统会基于这个时间段,运行 series_drilldown 算法,自动分析所有维度组合,找出对异常贡献最大的那些维度取值。
最终结果以表格形式呈现,按根因评分降序排列。每一行包含:
- 根因模式:导致异常的维度组合,例如“地域=华北,可用区=可用区A”
- 置信度:该模式对整体异常的贡献程度,0-1 之间的数值
- 影响曲线:该模式下的数据曲线
- 对比基线:除去该模式下的其他曲线
这个功能大大缩短了故障定位时间。在传统方式下,运维人员可能需要尝试十几种维度组合才能找到问题根源,而智能下钻只需几秒钟就能给出答案。
05 高级功能与技巧
5.1 多指标对比分析
详情模式下支持同时添加多个指标进行对比。这在分析指标间的相关性时非常有用。比如同时查看 CPU 使用率和请求延迟,可以直观判断性能瓶颈是否与资源有关。
5.2 查询语句查看
对于技术用户,MetricSet Explorer 提供了查询语句查看功能。点击图表右上角的“查询”按钮,可以看到生成该图表的完整查询语句。这不仅有助于理解数据来源,也方便用户将分析逻辑迁移到其他平台或脚本中。
5.3 图表交互

产品的图表支持丰富的交互操作:
- 缩放:鼠标框选某个时间范围可以放大查看
- 悬停提示:鼠标悬停时显示精确的数值和时间戳
- 图例控制:点击图例可以隐藏/显示对应曲线
- 收起/展开:支持折叠图表区域以便专注于分析结果
06 典型使用场景
让我们通过几个实际场景来展示 MetricSet Explorer 的价值。
场景一:快速故障定位
某电商平台在促销活动期间收到大量告警,显示订单服务响应时间超出阈值。运维人员打开 MetricSet Explorer,进行如下操作:
- 启用异常检测,系统自动将“订单创建耗时”指标排在首位
- 进入详情,框选异常时间段,启动智能下钻
- 系统分析后指出根因:地域=华南 + 数据库实例=db-05
- 确认该实例存在磁盘 IO 瓶颈,立即进行流量切换
场景二:容量规划
SRE 团队需要评估是否需要扩容 Redis 集群。使用智能分组功能:
- 选择“Redis 内存使用率”指标,按实例维度进行智能分组
- 系统识别出三个群组:高负载(15 个实例)、中负载(40 个实例)、低负载(25 个实例)
- 团队决定将低负载实例的流量导到高负载实例,暂不扩容
- 通过时间对比功能,验证调整后的效果
场景三:变更影响评估
开发团队发布了新版本,需要评估对性能的影响。使用时间对比功能:
- 查看核心指标,启用 1 天前的时间对比
- 叠加显示发布前后的曲线
- 发现某个接口的 P99 延迟上升了 20%
- 结合下钻分析,定位到新增的某个数据库查询是瓶颈所在
点击此处查看视频演示。


