
近日,实时分析领域知名 Benchmark —— RTABench(Real-Time Analytics Benchmark) 最新榜单公布,Apache Doris 以绝对领先的成绩登顶,结果表明,Apache Doris 在实时分析场景下性能是 ClickHouse 的 6 倍,PostgresSQL 的 30 倍,MongoDB 的 100 倍。
什么是 RTABench?
RTABench 是一套专为实时分析(Real-Time Analytics)场景设计的开源数据库性能基准测试工具(Benchmark)。它基于 Clickbench 框架开发,通过引入更贴合真实业务的数据模型与查询集,有效弥补了传统基准测试工具在 “实时性测试” 维度的不足,为实时分析类数据库的性能评估提供了更具参考价值的标准。
01 归一化多表数据库模型
不同于传统基准工具的 “单表设计”,RTABench 模拟电子商务场景中的订单追踪系统,构建了更贴近实际应用的多表关联结构,具体包含 5 张核心表:
customers(用户表)products(商品表)orders(订单主表)order_items(订单明细表)order_events(订单状态事件表)
这种结构能更真实地复现业务系统中 “跨表关联查询” 的高频场景,避免单表设计对实时数据库性能评估的偏差。
02 规模适中的真实数据集
RTABench 提供的数据集兼顾 “真实性” 与 “可执行性”,具体规模如下:
- 订单状态事件记录:约 1.71 亿条(核心高频数据)
- 用户数:1102 位
- 商品数:9255 件
- 订单数:约 1001 万个
该规模既能支撑对数据库 “实时处理能力” 的有效测试,又不会因数据量过大导致测试成本过高或扩展困难。
03 查询类型与场景模拟
RTABench 提供 31 条代表性查询,全面覆盖实时分析场景中的典型查询模式,具体可分为四类:
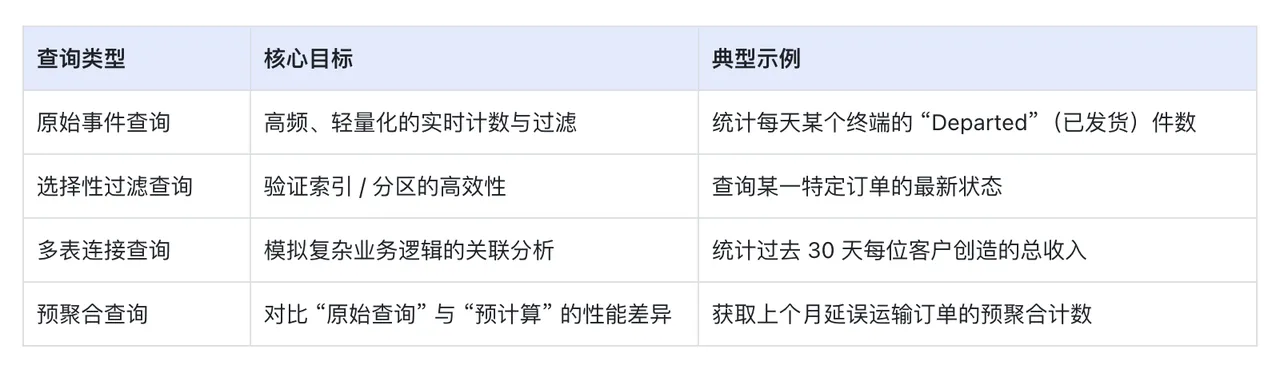
通过这些查询,能够清晰对比出不同数据库在“灵活性”(如原始查询适配度)与 “性能”(如预聚合响应速度)上的表现,更精准地匹配实时业务需求。
04 数据库系统分类
RTABench 针对不同类型的数据库进行分类测试,覆盖实时分析场景的主流技术选型,具体包括三大类:
- 通用型数据库(General-Purpose):如 PostgreSQL、MySQL(用于对比实时场景下的通用数据库表现);
- 实时分析型数据库(Real-Time Analytics):如 TimescaleDB、ClickHouse、Apache Doris(核心测试对象,聚焦实时性能评估);
- 批处理分析型数据库(Batch Analytics):如 DuckDB(仅作为对照组,非实时场景的核心关注对象)。
Apache Doris 领跑全场,性能优势明显
01 性能对比
在最新榜单中,Apache Doris 表现惊艳:
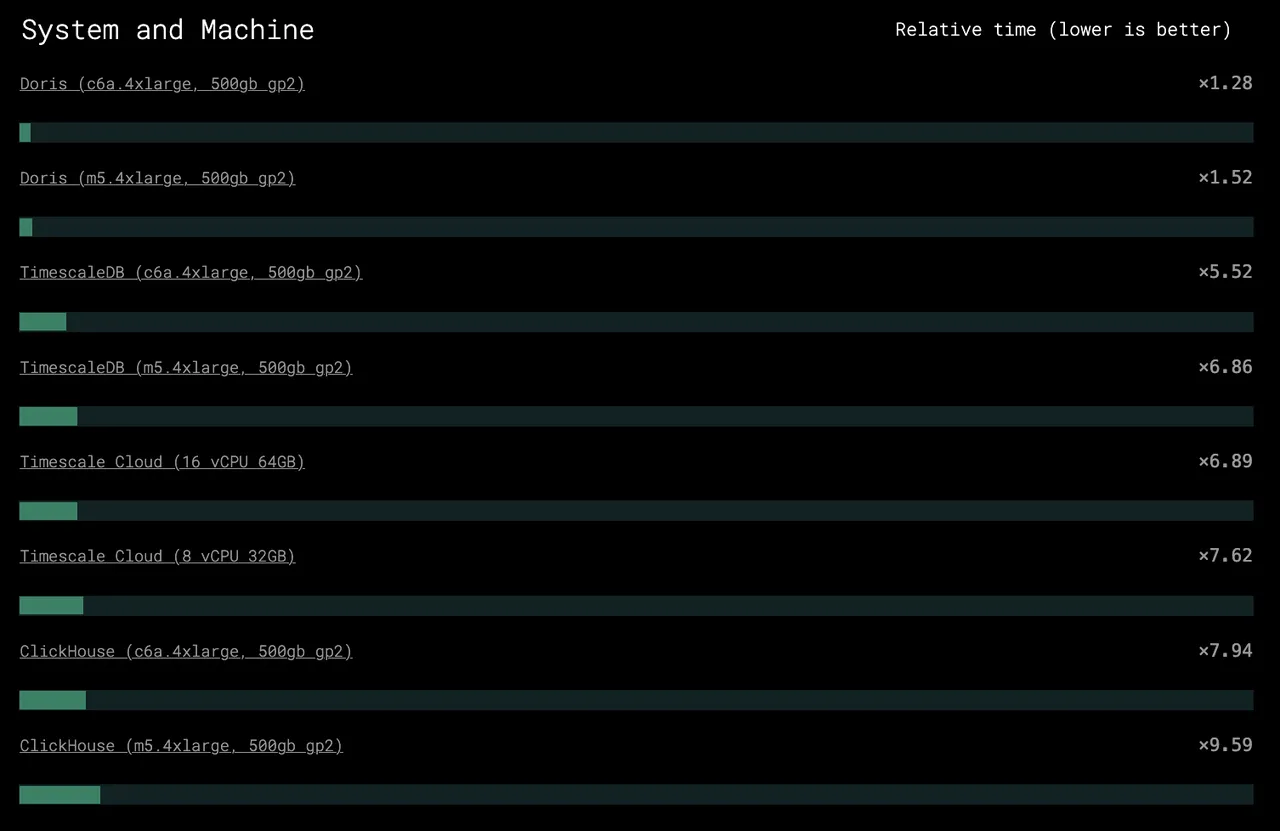
Doris(c6a.4xlarge,500GB gp2)查询性能得分仅为 ×1.28,在此项指标上位列第一,其性能接近排名第二的 TimescaleDB 的 4 倍,ClickHouse 的 6 倍,PostgresSQL 的 30 倍,MongoDB 的 100 倍。
02 固定机型下的竞争
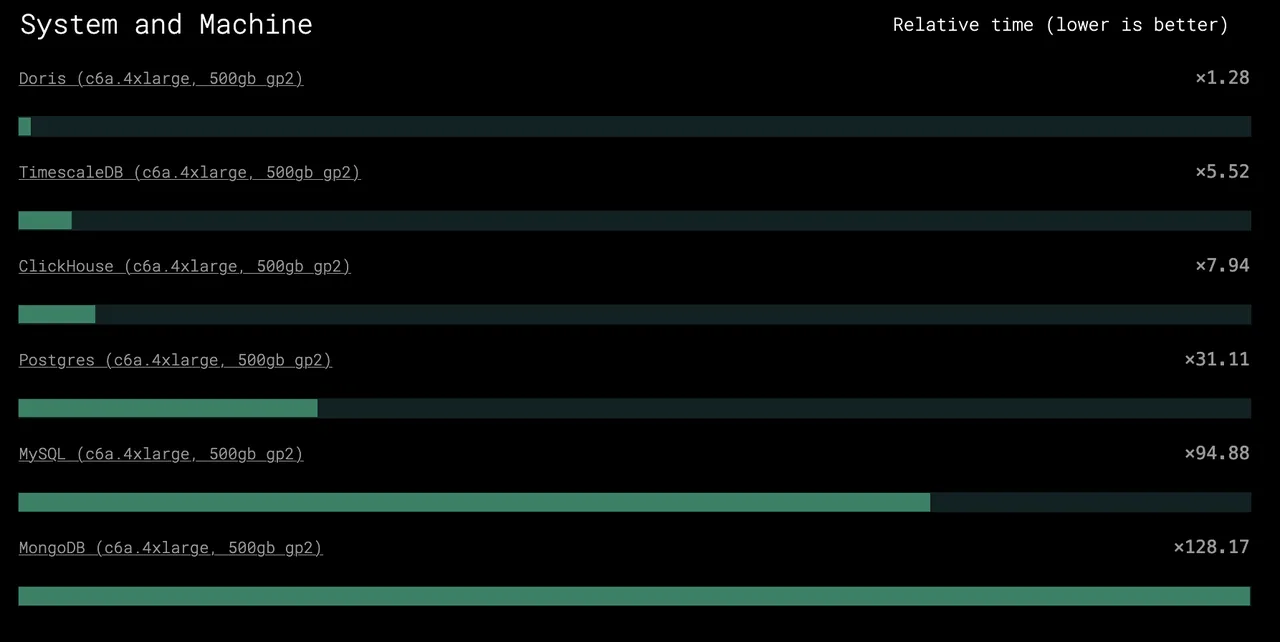
在 c6a.4xlarge 的同机型条件下,与部分传统数据库相比,Apache Doris 展现出数十倍的性能优势。即使与近年来在实时分析数据库领域大热的 ClickHouse 相比,Doris 同样拥有数倍的性能领先。
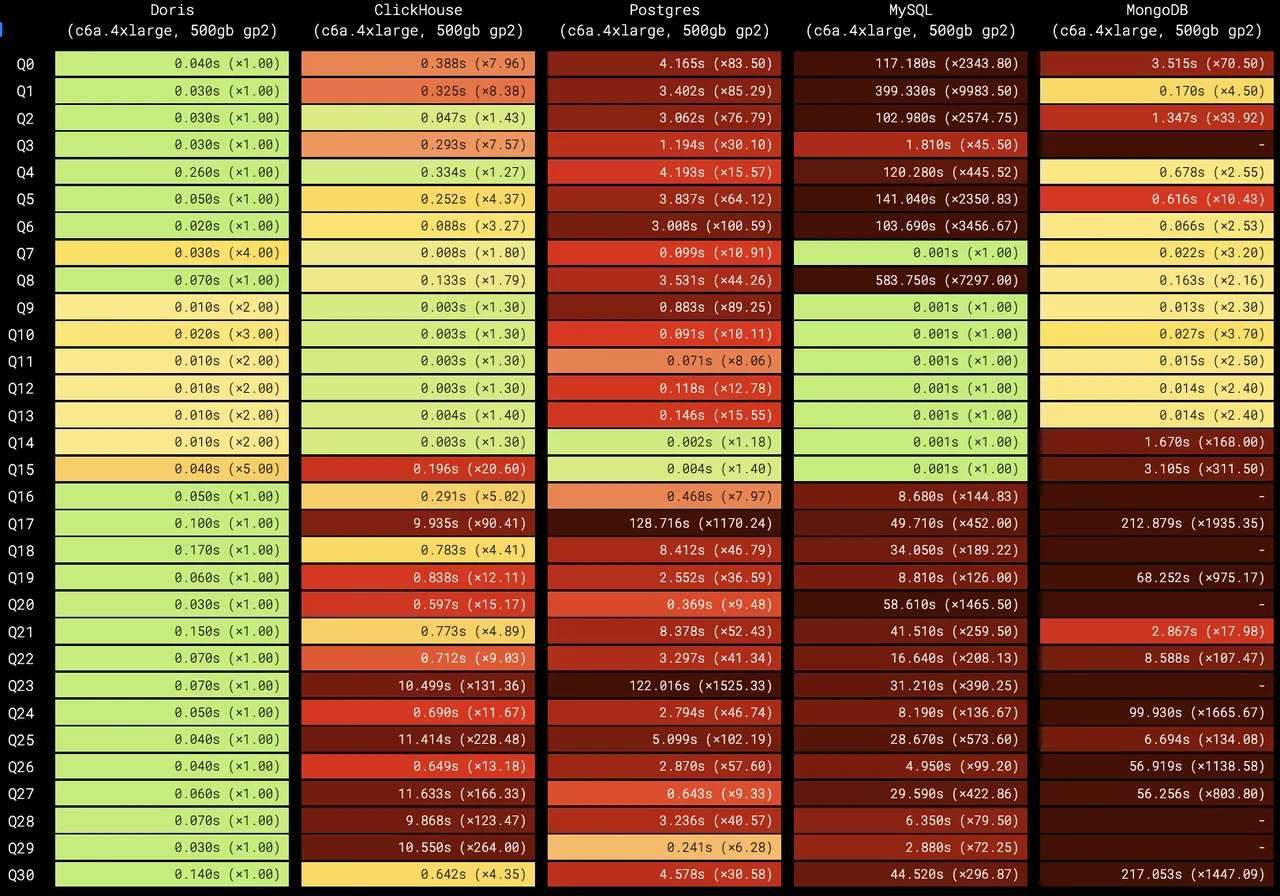
性能领先背后的秘密
Apache Doris 能够在 RTABench 中脱颖而出,并非偶然,而是源于其在执行引擎与优化器方面的持续创新与深度优化:
- MPP 架构与列式存储 Doris 采用大规模并行处理(MPP)架构,结合列式存储和高效压缩算法,从而确保计算任务充分分布且并行执行。在查询过程中,仅需读取相关列,极大降低了 I/O 开销,为大规模数据的实时分析提供了坚实基础。
- Pipeline 引擎 Doris 使用 Pipeline 将查询分解为多个子任务并行执行,充分利用多核 CPU 的能力。
- 通过限制查询线程数,有效解决了传统执行模式下线程膨胀的问题;
- 减少数据拷贝与共享,降低了系统开销;
- 针对排序、聚合等核心操作进行深度优化,大幅提升查询效率和整体吞吐量。
- 向量化执行 Doris 支持批量处理数据(向量化执行),充分利用现代 CPU 指令集,减少函数调用开销。与 Pipeline 执行引擎配合,进一步提升了复杂分析查询的响应速度。
- 智能优化器(CBO + RBO) Doris 的优化器融合了 RBO(基于规则)、CBO(基于代价)的多重策略,多层次优化策略确保 Doris 在各种复杂查询场景下,都能生成性能最优的执行计划。
正是凭借这些组合,Apache Doris 在 RTABench 的实时分析测试中,取得了远超 TimescaleDB、ClickHouse、MongoDB、PostgreSQL 等数据库的成绩,登顶榜首。
实时分析的新王者
在 RTABench 的测试场景下,Apache Doris 证明了自己是实时分析领域最值得信赖的数据库之一:
- 兼顾多表关联与单表点查;
- 保持卓越的查询性能;
- 面向大规模实时数据的处理游刃有余。
无论是初创团队还是大型企业,Apache Doris 都能帮助业务在 毫秒级洞察 中抢占先机。







