
在前两节中,我们熟悉了Scala 的基础语法和流程控制。现在,我们将深入探讨Scala 代码组织的两大核心构建块:方法 和 函数。在许多语言中,这两个术语可以互换使用,但在 Scala 中,它们有着明确而重要的区别。理解这种区别是掌握Scala 函数式编程思想的关键一步。
思维导图
一、方法
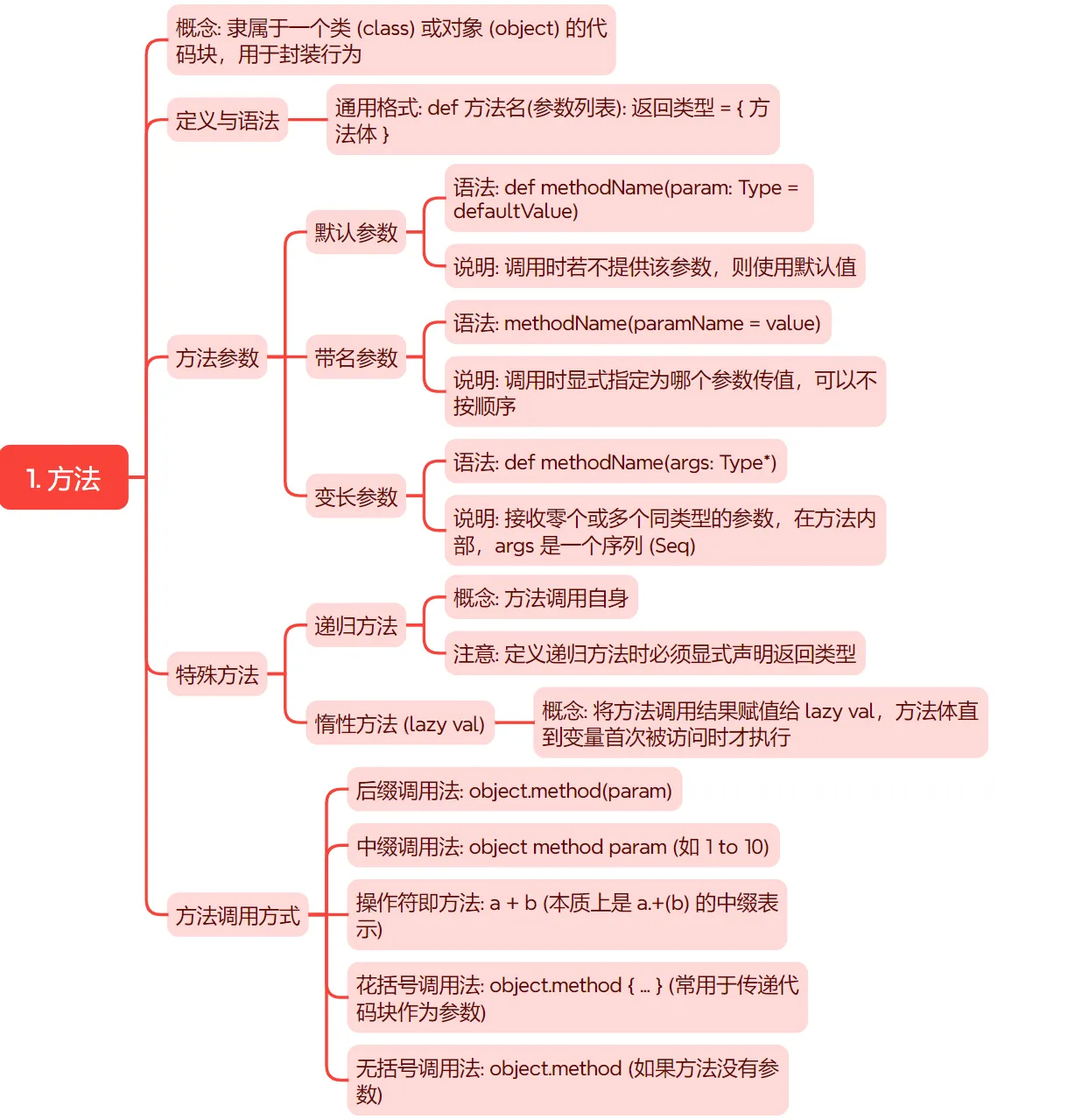
方法是 隶属于一个 类 (class) 或 对象 (object) 的 代码块,用于 封装行为。你可以把它 理解为一个 对象的“能力”或 “动作”。定义与语法:
def 方法名(参数列表): 返回类型 = { 方法体 }
| 语法部分 | 说明 | 示例 |
|---|---|---|
def |
定义方法的关键字。 | def add(...) |
方法名 |
遵循小驼峰命名规范。 | calculateSum |
(参数列表) |
(param1: Type1, param2: Type2),参数名在前,类型在后。 |
(a: Int, b: Int) |
: 返回类型 |
方法执行后返回值的类型。 | : Int |
= |
连接方法签名和方法体。 | |
{ 方法体 } |
包含方法执行逻辑的代码块。如果方法体只有一行,花括号 {} 可以省略。 |
{ a + b } |
return 关键字: 在方法体中通常是
可选的,因为方法会
默认返回最后一个表达式的值。
过程: 如果方法返回
Unit (无特定返回值),则称为过程,其定义时
可以省略等号。
代码案例:
scala // 完整定义 def add(a: Int, b: Int): Int = { return a + b // return 关键字可选 } // 省略返回类型 (编译器可推断) def subtract(a: Int, b: Int) = { a - b // 默认返回最后一个表达式的值 } // 单行方法体可省略花括号 def multiply(a: Int, b: Int) = a * b // 过程 (返回 Unit),等号可以省略 def printSum(a: Int, b: Int) { println(s"The sum is: ${a + b}") }
方法参数:
| 参数类型 | 语法/示例 | 说明 |
|---|---|---|
| 默认参数 | def greet(name: String = "Guest") |
调用时若不提供该参数,则使用默认值。 |
| 带名参数 | sendMessage(to = "Bob", from = "Alice") |
调用时显式指定为哪个参数传值,可以不按参数列表的顺序。 |
| 变长参数 | def sum(args: Int*) |
使用 * 定义,可以接收零个或多个同类型的参数。在方法内部,args 是一个序列 (Seq[Int])。 |
代码案例:
// 默认参数
def greet(name: String = "Guest", message: String = "Welcome"): Unit = {
println(s"$message, $name!")
}
greet() // 输出: Welcome, Guest!
greet("Alice") // 输出: Welcome, Alice!
greet(message = "Hello") // 输出: Hello, Guest!
// 带名参数
greet(name = "Bob", message = "Hi") // 顺序无关
greet(message = "Good day", name = "Charlie")
// 变长参数
def sum(numbers: Int*): Int = {
var total = 0
for (n <- numbers) {
total += n
}
total
}
println(sum(1, 2, 3)) // 输出 6
println(sum()) // 输出 0
递归方法: 方法调用自身。注意: 定义递归方法时必须显式声明返回类型。
```scala
// 递归计算阶乘
def factorial(n: Int): Int = {
if (n <= 1) 1 else n factorial(n - 1)
}
* <font color="navy">**惰性方法 (`lazy val`):**</font> 将<font color="olive">方法的调用结果</font>赋值给一个 `lazy val` 变量,该<font color="darkcyan">方法体内的代码</font>直到变量<font color="saddlebrown">首次被访问时</font>才会执行。scala
def expensiveCalculation(): String = {
println("Performing an expensive calculation...")
"Done"
}
lazy val result = expensiveCalculation()
println("Lazy val defined, but not yet evaluated.")
println(s"Accessing for the first time: $result") // 此时才打印 "Performing..."
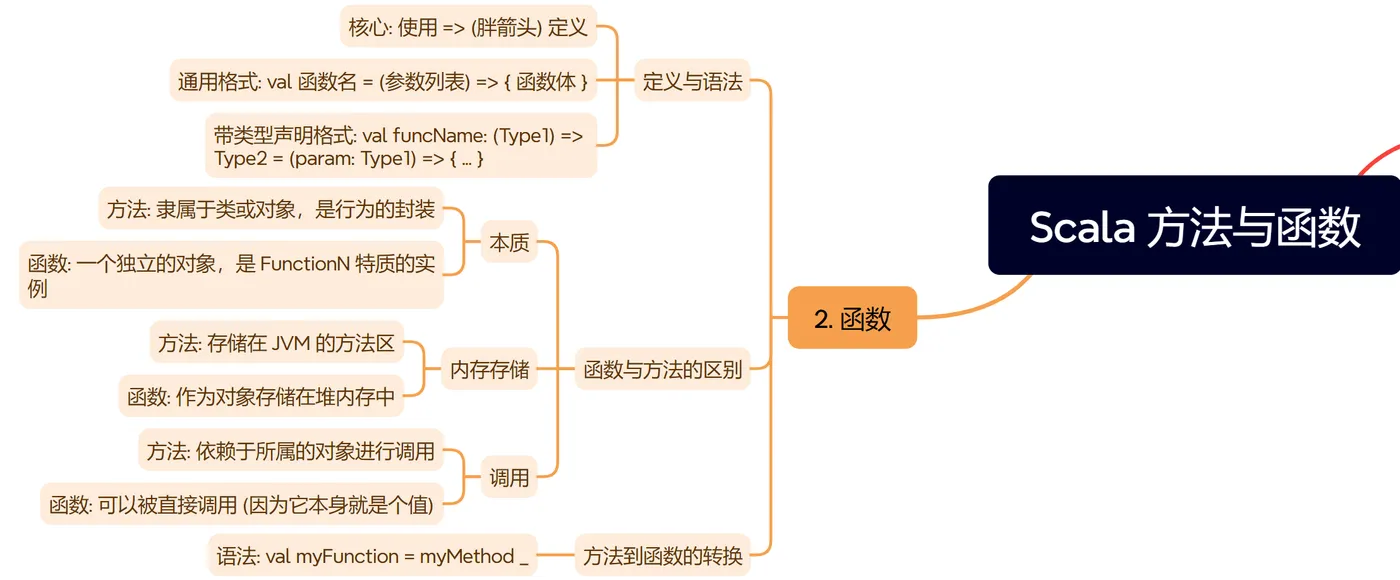
<font color="darkmagenta">**方法调用方式:**</font> Scala 提供了<font color="firebrick">多种灵活</font>的方法调用语法。 | 调用方式 | 语法 | 示例 | | :--- | :--- | :--- | | **后缀调用法** | `object.method(param)` | `Math.abs(-10)` | | **中缀调用法** | `object method param` | `1 to 10` (等价于 `1.to(10)`)<br>`List(1,2) drop 1` | | **操作符即方法** | `a + b` | 在 Scala 中,所有操作符<font color="darkslategray">本质上都是方法</font>。`1 + 2` 是 `1.+(2)` 的<font color="indigo">中缀表示法</font>。 | | **花括号调用法** | `object.method { ... }` | `println { "Hello" }`<br>常用于<font color="blue">传递代码块</font>作为参数。 | | **无括号调用法** | `object.method` | 如果方法<font color="red">没有参数</font>,调用时<font color="green">可以省略括号</font>。例如 `"hello".length`。 | ## <font color="navy">二、函数</font> <font color="orange">函数</font>在 Scala 中是<font color="purple">一等公民</font>,这意味着它<font color="teal">本身是一个对象 (值)</font>,可以被<font color="brown">赋值给变量</font>、<font color="darkgreen">作为参数</font>传递或<font color="darkred">作为返回值</font>。 <font color="navy">**定义与语法: `val 函数名 = (参数列表) => { 函数体 }`**</font> `=>` (胖箭头) 是<font color="olive">定义函数</font>的<font color="darkcyan">核心</font>。 **代码案例:**scala
// 定义一个接收 Int,返回 Int 的函数
val square: Int => Int = (x: Int) => x x
// 类型推断可以让定义更简洁
val add = (a: Int, b: Int) => a + b
// 调用函数,就像调用一个变量
println(square(5)) // 输出 25
println(add(10, 20)) // 输出 30
```
*函数与方法的区别:
| 方面 | 方法 | 函数 |
|---|---|---|
| 本质 | 隶属于类或对象,是行为的封装。 | 一个独立的对象,是 FunctionN (如 Function1, Function2) 特质的实例。 |
| 内存 | 存储在 JVM 的方法区。 | 作为对象存储在堆内存中。 |
| 调用 | 依赖于所属的对象进行调用。 | 可以被直接调用 (因为它本身就是个值)。 |
在实际应用中,经常需要将一个 已定义的方法当作 函数来传递 (例如,传递给
map,
filter 等高阶函数)。
使用 部分应用 (ETA Expansion)
_ 操作符可以将方法
转换为一个
函数对象。
格式:
val myFunction = myMethod _
代码案例:
scala // 定义一个方法 def triple(x: Int): Int = x * 3 // 将 triple 方法转换为一个函数 val tripleFunction = triple _ // 现在可以像使用函数一样使用 tripleFunction val numbers = List(1, 2, 3) val tripledNumbers = numbers.map(tripleFunction) // map 需要一个函数作为参数 println(tripledNumbers) // 输出: List(3, 6, 9) // Scala 编译器通常可以自动进行这种转换,所以以下写法也有效 val tripledNumbers2 = numbers.map(triple) println(tripledNumbers2)
理解
_ 的转换过程对于
深入掌握 Scala 的
函数式特性至关重要。
---
## 练习题
题目一:方法定义
定义一个名为 getGreeting 的方法,它接收一个 String 类型的 name 参数,并返回一个 String 类型的问候语,如 "Hello, [name]!"。
题目二:默认参数
重写 getGreeting 方法,使其 name 参数有一个默认值 "World"。这样,如果不传递参数调用 getGreeting(),它将返回 "Hello, World!"。
题目三:带名参数
定义一个方法 createPerson(name: String, age: Int, city: String)。使用带名参数的方式调用它,但参数顺序为 city, age, name。
题目四:变长参数
定义一个方法 average,它可以接收任意数量的 Double 类型参数,并返回它们的平均值。如果没有任何参数传入,应返回 0.0。
题目五:递归方法
定义一个递归方法 sumUpTo(n: Int),计算从 1 到 n 的所有整数之和。必须显式声明其返回类型。
题目六:中缀调用法
给定一个 List(1, 2, 3, 4, 5),使用中缀调用法调用 map 方法,使其每个元素加 1。
题目七:操作符即方法
将 10 * 5 这个表达式用标准的后缀调用法重写。
题目八:函数定义
定义一个名为 isEven 的函数 (不是方法),它接收一个 Int 参数,如果该数是偶数则返回 true,否则返回 false。
题目九:方法到函数的转换
定义一个 isOdd 的方法。然后,将 List(1, 2, 3, 4) 使用 .filter() 方法和转换后的 isOdd 函数进行过滤,得到只包含奇数的列表。
题目十:Unit 过程
定义一个名为 log 的过程 (返回 Unit 的方法),它接收一个 String 类型的 message,并在控制台打印出带时间戳的日志,如 [YYYY-MM-DD HH:MM:SS] message。
题目十一:无括号调用
给定 val s = "Scala",使用无括号调用法获取其长度。
题目十二:lazy val 与方法
定义一个方法 connectToDatabase(),它会打印 "Connecting to database..." 并返回字符串 "Connection successful"。然后,创建一个 lazy val dbConnection 来调用此方法。在程序中先打印 "Script started.",再打印 dbConnection 的值,并观察输出顺序。
题目十三:花括号调用法
定义一个方法 executeBlock(block: => String),它会打印 "Starting execution...",然后执行并打印传入的代码块的结果,最后打印 "Execution finished."。使用花括号调用法向其传递一个简单的字符串 "Hello Block"。
题目十四:方法与函数区别
简述方法和函数在“本质”和“内存存储”上的核心区别。
题目十五:综合应用
定义一个方法 processString(s: String, f: String => String),它接收一个字符串 s 和一个函数 f。该方法应用函数 f 到字符串 s 上,并打印结果。然后,定义一个 reverseString 的函数,并用 processString 方法调用它处理字符串 "abcde"。
答案与解析
答案一:
def getGreeting(name: String): String = {
s"Hello, $name!"
}
解析: 这是一个标准的方法定义,包含参数、返回类型和方法体。
答案二:
def getGreeting(name: String = "World"): String = {
s"Hello, $name!"
}
println(getGreeting()) // 输出 Hello, World!
解析:
name: String = "World"为name参数设置了默认值。
答案三:
def createPerson(name: String, age: Int, city: String): Unit = {
println(s"$name, $age, from $city")
}
createPerson(city = "New York", age = 30, name = "John")
解析: 带名参数允许调用者不按声明顺序传递参数,提高了代码的可读性。
答案四:
def average(numbers: Double*): Double = {
if (numbers.isEmpty) 0.0 else numbers.sum / numbers.length
}
解析:
Double*定义了变长参数。在方法内部,numbers是一个Seq[Double],可以直接使用.sum和.length等集合方法。
答案五:
def sumUpTo(n: Int): Int = {
if (n <= 0) 0 else n + sumUpTo(n - 1)
}
解析: 递归方法必须显式声明返回类型 (
: Int),以便编译器可以进行类型检查。
答案六:
val numbers = List(1, 2, 3, 4, 5)
val incremented = numbers map (_ + 1)
println(incremented) // 输出: List(2, 3, 4, 5, 6)
解析:
numbers map (_ + 1)是numbers.map(_ + 1)的中缀表示法。_ + 1是一个匿名函数。
答案七:
val result = (10).*(5)
println(result)
解析:
10 * 5是10.*(5)的中缀语法糖。标准的后缀调用法需要将对象 (10) 用括号括起来以调用.方法。
答案八:
val isEven = (n: Int) => n % 2 == 0
println(isEven(4)) // true
println(isEven(5)) // false
解析:
val isEven = ...定义了一个函数值。=>是函数定义的标志。
答案九:
// 方法
def isOdd(n: Int): Boolean = n % 2 != 0
val numbers = List(1, 2, 3, 4)
// 将 isOdd 方法转换为函数并传递给 filter
val oddNumbers = numbers.filter(isOdd _)
println(oddNumbers) // 输出: List(1, 3)
解析:
isOdd _使用 ETA Expansion 将isOdd方法转换成一个函数对象,使其可以被filter方法接受。
答案十:
def log(message: String): Unit = {
// 简单的时间格式化
val timestamp = new java.text.SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new java.util.Date())
println(s"[$timestamp] $message")
}
log("User logged in.")
解析: 返回类型为
Unit的方法称为过程,表示它执行一个动作但不返回有意义的值。
答案十一:
val s = "Scala"
val len = s.length
println(len)
解析: 对于无参方法,调用时可以省略括号
()。
答案十二:
def connectToDatabase(): String = {
println("Connecting to database...")
"Connection successful"
}
lazy val dbConnection = connectToDatabase()
println("Script started.")
println(s"Connection status: $dbConnection")
输出顺序:
Script started.
Connecting to database...
Connection status: Connection successful
解析:
connectToDatabase()方法直到dbConnection第一次被访问时才执行。
答案十三:
def executeBlock(block: => String): Unit = {
println("Starting execution...")
println(s"Result: $block")
println("Execution finished.")
}
executeBlock {
"Hello Block"
}
解析:
block: => String定义了一个“传名参数”,它在被调用前不会被求值。花括号{}是向只有一个参数的方法传递代码块的常用语法。
答案十四:
本质: 方法是类或对象的成员,是代码行为的封装。函数是一个独立的对象,是
FunctionN特质的实例。
内存存储: 方法存储在JVM的方法区 (与类定义一起)。函数作为对象存储在堆内存中。
答案十五:
// 方法,接收一个字符串和一个函数
def processString(s: String, f: String => String): Unit = {
val result = f(s)
println(s"Processed result: $result")
}
// 函数
val reverseString = (s: String) => s.reverse
// 调用
processString("abcde", reverseString) // 输出: Processed result: edcba
解析:
processString是一个高阶方法,因为它接收另一个函数f作为参数。reverseString是一个函数值,被传递给processString进行应用。
