
前言
在数字化时代,字符的编码与解码是信息传递的基础。当我们在屏幕上输入一个汉字、一个英文单词、一个阿拉伯数字,或是一个 emoji 表情时,背后都隐藏着一套精密的编码规则 —— 它们将人类可识别的字符转换为计算机可理解的二进制数据。然而,在计算机发展的早期,由于缺乏统一的编码标准,不同国家和地区各自制定了适用于本地语言的编码方案:英语国家广泛使用 ASCII 码,中国采用 GB2312 编码,日本使用 Shift-JIS 编码…… 这种 “各自为政” 的局面导致了严重的 “乱码” 问题:一篇包含多语言的文档在不同系统中打开时,往往会出现无法识别的符号,极大地阻碍了全球信息的流通。
为解决这一困境,Unicode 编码标准应运而生。它像一座桥梁,将全球几乎所有语言的字符纳入同一套编码体系,让跨语言、跨平台的信息交换成为可能。本文将全面解析 Unicode 编码的起源、原理、特点及其在现代信息技术中的应用,帮助读者理解这一 “数字世界通用语言” 的核心逻辑。

一、Unicode 简介
Unicode(统一码、万国码)是一套由 Unicode 联盟(Unicode Consortium)制定的字符编码标准,其核心目标是为世界上所有的字符(包括字母、数字、符号、表情符号等)分配一个唯一的数字编号,实现 “一码一字符” 的全球统一表示。
与传统编码标准(如 ASCII 仅包含 128 个字符)不同,Unicode 不局限于特定语言或地区,而是致力于覆盖人类历史上所有曾经使用过的文字系统,以及现代社会中出现的新字符(如 emoji 表情、特殊符号等)。截至 2023 年 9 月发布的 Unicode 15.0 版本,其已收录超过 14.9 万个字符,涵盖 161 种现代语言和 76 种古文字(如古埃及象形文字、甲骨文等)。
从本质上看,Unicode 是一个 “字符集”(Character Set)—— 它定义了字符与数字编号(称为 “码点”)的对应关系,但并不直接规定这些数字如何在计算机中存储或传输。具体的存储和传输方式由 “编码方案”(如 UTF-8、UTF-16、UTF-32)负责,这一点也是理解 Unicode 与其他编码关系的关键。

二、Unicode 的发展历程
Unicode 的诞生源于对 “编码混乱” 的反思,其发展历程折射出全球信息一体化的迫切需求。
1. 文本编码的起源
随着计算机的发展,科学家将文字转化为二进制码以便机器识别,1946年的ENIAC是其开端。回溯至1946年,随着第二台电子计算机ENIAC的诞生——同时也是世界上首台通用计算机的问世,它仅能解读由开关电路编织的二进制密码。面对这一局限,科学家们不得不将26个英文字母精心转化为由0和1构成的“摩尔斯电码”。
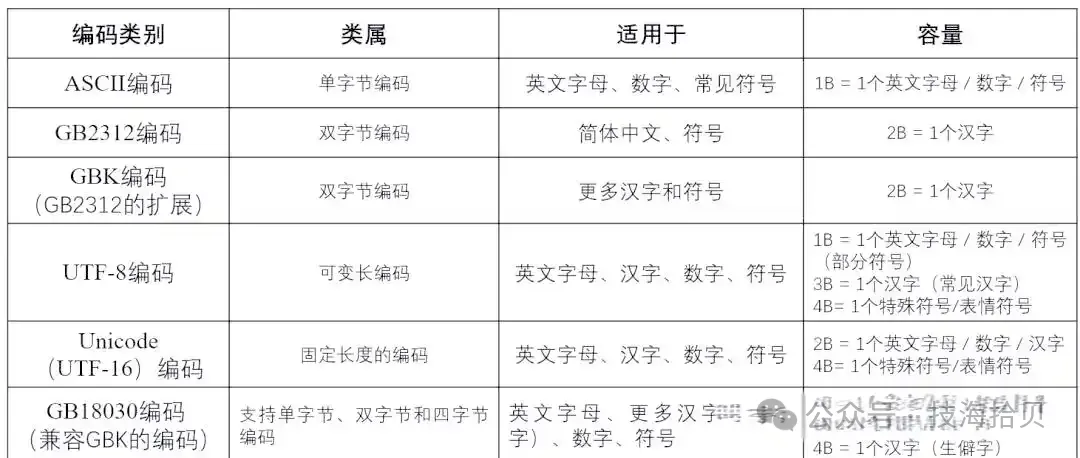
2. 早期编码的困境
ASCII于1963年诞生,用7位二进制数构建了一个包含128个字符的“数字字母表”,类似于我们熟悉的字典字库。这一里程碑式的成就让计算机首次拥有了属于自己的“语言词典”。尽管这大大扩展了计算机对字符文本的理解能力,但随着时间的推移和国际化进程的加速,单字节的ASCII编码在应对英语与数字之外的其他语系时,逐渐显现出其局限性。值得一提的是,这里的1B(字节)等于8bit(位),这是初中计算机知识中的基础知识。
20 世纪 60 年代,ASCII(美国信息交换标准代码)成为首个广泛应用的字符编码标准,它用 7 位二进制数(0-127)表示 128 个字符,包括英文字母、数字和常用符号。然而,ASCII 仅能满足英语国家的需求,对于包含大量字符的语言(如汉语、日语、阿拉伯语)完全无能为力。
为解决多语言编码问题,各国开始制定本地编码标准:中国推出了 GB2312(收录 6763 个简体汉字)和 GBK(扩展至 21003 个汉字),日本制定了 Shift-JIS,韩国采用了 EUC-KR…… 这些编码虽然解决了本地语言的表示问题,但存在两个致命缺陷:一是编码空间重叠(不同语言的字符可能对应相同的数字编号),二是兼容性差(一个系统无法同时正确显示多种语言的字符)。例如,在 GB2312 中,数字 “0xA3A0” 表示汉字 “啊”,但在 Shift-JIS 中,相同的数字可能对应一个日语假名,这就是 “乱码” 的根源。
3. Unicode 的诞生
1987 年,Xerox公司(施乐公司)的 Joe Becker 和 苹果公司的 Lee Collins 等人提出了 “统一字符编码” 的构想,旨在创建一套覆盖全球所有字符的编码标准。
1991 年,Unicode 1.0 版本发布,收录了约 7000 个字符,涵盖英语、法语、德语等欧洲语言,以及汉语、日语、韩语等东亚语言的常用字符。此时的 Unicode 采用 16 位编码空间(可表示 65536 个字符),即 “UCS-2”(通用字符集 - 2 字节)格式,这一设计为早期的 Java、Windows 等平台提供了基础支持。
Unicode在1987年由Joe Becker(Xerox)、Lee Collins(Apple)和Mark Davis(Apple)一起提出。他们的想法是建立一个通用的字符集,因为当时有许多互不兼容的纯文本编码标准:多个版本的8比特 ACSCII、大五码(繁体中文)、GB2312(简体中文)等等。在Unicode之前,不存在多语言的纯文本编码标准,不过有富文本系统(如苹果的WorldScript)支持组合不同的编码。
Unicode的第一份草案发布于1988年。此后项目继续进行,工作组也随之扩张。
1991年1月3日,Unicode联盟(Unicode Consortium)成立:
Unicode联盟是一个非盈利组织,致力于开发、维护和推广软件国际化的标准和数据,尤其是Unicode标准。
地点:美国加利福尼亚州。
成员:
初始成员包括 Xerox、Apple、Microsoft、IBM 等科技公司。
随后吸引了更多企业和学术机构加入。
使命
制定标准:定义 Unicode 字符集及其编码规则。
推广使用:推动 Unicode 在全球范围内的普及。
持续更新:根据语言和文化的变化扩展字符集。
Unicode 1.0的第一卷在1991年10月发布,第二卷在1992年6月发布。
4. 逐步扩展与完善
随着需求的增长,16 位编码空间逐渐无法满足需求(仅能覆盖基本多语言平面)。1996 年,Unicode 2.0 引入了 “辅助平面” 概念,将编码空间扩展至 21 位(0x0000 至 0x10FFFF),理论上可容纳 111 万个字符,这一设计沿用至今。
此后,Unicode 版本不断更新,每年新增数千个字符:2001 年加入古埃及象形文字,2010 年纳入 emoji 表情(最初仅 722 个,截至 2023 年已超过 3600 个),2021 年新增 “𓀀”(古埃及象形文字 “太阳”)等古文字字符。 Unicode 的扩展不仅是技术问题,还涉及文化、历史等多方面的考量 —— 每个新增字符都需经过语言学验证、文化适用性评估等严格流程。
三、Unicode 的核心特点
Unicode 之所以能成为全球通用的编码标准,与其独特的设计理念和技术特点密不可分。
1. 全球统一性
Unicode 最核心的特点是 “统一性”—— 它为每个字符分配唯一的 “码点”(Code Point),无论该字符属于哪种语言、哪个地区。例如:
英文字母 “A” 的码点是 U+0041;
汉字 “中” 的码点是 U+4E2D;
阿拉伯数字 “3” 的码点是 U+0033;
笑脸 emoji“😊” 的码点是 U+1F60A。
这种唯一性彻底解决了传统编码中 “同码不同字” 的问题,使得多语言文档在任何支持 Unicode 的系统中都能正确显示。
2. 可扩展性
Unicode 的编码空间为 21 位(0x0000 至 0x10FFFF),划分为 17 个 “平面”(Plane),每个平面包含 65536 个码点:
第 0 平面(U+0000 至 U+FFFF):基本多语言平面(BMP),包含世界上所有现代语言的常用字符;
第 1 平面(U+10000 至 U+1FFFF):辅助多语言平面,包含较少使用的语言字符(如古汉语、梵文);
第 2 平面至第 13 平面:尚未广泛使用,预留用于未来扩展;
第 14 平面(U+E0000 至 U+EFFFF):专用区,供用户自定义字符;
第 15-16 平面:私人使用区,用于企业或个人内部字符。
这种分层设计为 Unicode 的长期扩展预留了充足空间,确保其能适应未来新字符(如新兴 emoji、人造语言符号)的纳入。
3. 与编码方式分离
Unicode 仅定义 “字符 - 码点” 的对应关系,不规定码点如何存储为字节 —— 这一任务由 “编码方案”(Encoding Scheme)完成。常见的编码方案包括 UTF-8、UTF-16、UTF-32 等,它们各有优缺点,适用于不同场景。这种 “字符集与编码方案分离” 的设计,使得 Unicode 能灵活适配不同的存储和传输需求。
4. 兼容性
Unicode 对传统编码保持了良好的兼容性。例如,它将 ASCII 码完全纳入基本多语言平面的前 128 个码点(U+0000 至 U+007F),这意味着 ASCII 编码的文档可以直接被 Unicode 系统识别,无需额外转换。对于 GB2312、Shift-JIS 等编码,Unicode 也通过 “映射表” 建立了与自身码点的对应关系,方便旧文档的迁移。
四、Unicode 的工作原理
要理解 Unicode 的运作机制,需从 “码点”“平面”“代理对” 等核心概念入手。
1. 码点(Code Point)
码点是 Unicode 中字符的唯一标识,通常用 “U+” 前缀加十六进制数字表示,例如 U+4E2D(“中”)、U+1F60A(“😊”)。码点的取值范围是 0x0000 至 0x10FFFF,共 1114112 个可能值(其中大部分尚未分配字符)。
2. 平面划分
如前所述,Unicode 的 21 位编码空间被划分为 17 个平面,每个平面包含 2^16(65536)个码点:
基本多语言平面(BMP):U+0000 至 U+FFFF,是最常用的平面,涵盖绝大多数现代语言的字符和常用符号;
辅助平面:U+10000 至 U+10FFFF,包含较少使用的字符(如古文字、 emoji 等)。
3. 代理对(Surrogate Pairs)
由于早期的 Unicode 实现(如 UCS-2)仅支持 16 位编码空间(即 BMP 平面),无法表示辅助平面的字符(码点 ≥ U+10000)。为解决这一问题,Unicode 引入了 “代理对” 机制:用两个 16 位的 “代理字符”(Surrogate Code Units)组合表示辅助平面的码点。
具体来说,代理对的编码规则如下:
辅助平面的码点范围是 U+10000 至 U+10FFFF,共 0x100000 个字符;
将码点减去 U+10000,得到一个 20 位的数值(范围 0x00000 至 0xFFFFF);
将这 20 位数值拆分为高 10 位和低 10 位;
高 10 位加上 0xD800,得到第一个代理字符(高代理,范围 0xD800 至 0xDBFF);
低 10 位加上 0xDC00,得到第二个代理字符(低代理,范围 0xDC00 至 0xDFFF)。
例如,笑脸 emoji“😊” 的码点是 U+1F60A:
计算:0x1F60A - 0x10000 = 0xF60A(二进制为 1111011000001010);
高 10 位:0xF60A 的前 10 位是 0011110110(即 0x01F6);
低 10 位:0xF60A 的后 10 位是 00001010(即 0x000A);
高代理:0x01F6 + 0xD800 = 0xD83D;
低代理:0x000A + 0xDC00 = 0xDC0A;
因此,“😊” 在 UTF-16 中表示为两个字节序列:0xD83D 和 0xDC0A。
代理对机制确保了 Unicode 能向下兼容早期的 16 位实现,同时支持更大的编码空间。
五、Unicode 编码示例
以下通过具体例子展示 Unicode 码点与不同编码方案的对应关系,帮助理解其实际应用。
1. 基本字符(BMP 平面)
以汉字 “中” 为例:
Unicode 码点:U+4E2D(十六进制);
十进制值:4E2D 转换为十进制是 20013;
在 UTF-16 中:直接用 2 字节表示,即 0x4E2D;
在 UTF-8 中:需用 3 字节表示,计算过程如下:
4E2D 的二进制是 100111000101101;
UTF-8 对 3 字节字符的格式是:1110xxxx 10xxxxxx 10xxxxxx;
拆分二进制位并填充:11100100 10111000 10101101,即 0xE4 0xB8 0xAD;
在 UTF-32 中:用 4 字节表示,即 0x00004E2D。
2. 辅助平面字符(以 emoji 为例)
以 “❤️”(爱心 emoji)为例:
Unicode 码点:U+2764(基本平面)+ U+FE0F(变体选择符),组合为 “❤️”;
在 UTF-8 中:
U+2764 对应 3 字节:0xE2 0x9D 0xA4;
U+FE0F 对应 3 字节:0xEF 0xB8 0x8F;
因此,“❤️” 的 UTF-8 编码为 0xE2 0x9D 0xA4 0xEF 0xB8 0x8F。
以 “🤖”(机器人 emoji)为例:
Unicode 码点:U+1F916(辅助平面);
代理对计算:0x1F916 - 0x10000 = 0xF916 → 高 10 位 0x03E ,低 10 位 0x116;
高代理:0x03E + 0xD800 = 0xD83E;
低代理:0x116 + 0xDC00 = 0xDD16;
在 UTF-16 中表示为 0xD83E 0xDD16;
在 UTF-8 中:需 4 字节表示,即 0xF0 0x9F 0xA4 0x96。
六、Unicode 与其他编码的区别
Unicode 常与 ASCII、UTF-8、GBK 等编码一同被提及,但它们的本质不同。需明确:Unicode 是 “字符集”,而 ASCII、UTF-8、GBK 等是 “编码方案”(部分既是字符集也是编码方案)。
1. Unicode 与 ASCII
ASCII 是最早的字符集和编码方案,仅包含 128 个字符(7 位),适用于英语;
Unicode 是更全面的字符集,包含 ASCII 的所有字符(码点 U+0000 至 U+007F),二者兼容;
关系:ASCII 是 Unicode 的子集,Unicode 可视为 ASCII 的超集扩展。
2. Unicode 与 GBK、Shift-JIS 等
GBK、Shift-JIS 等是 “区域性编码方案”,既是字符集(定义本地字符)也是编码方案(规定存储方式);
它们的编码空间有限,且与其他编码重叠,无法支持多语言;
关系:Unicode 通过映射表与这些编码建立对应关系,可实现相互转换,但需注意部分生僻字可能无法完全映射。
3. Unicode 与 UTF-8、UTF-16、UTF-32
这是最易混淆的一组概念:Unicode 是字符集(定义码点),而 UTF-8/16/32 是 “Unicode 编码方案”(将码点转换为字节序列的规则)。
UTF-8:
可变长度编码:1 字节(ASCII 字符)、2 字节(欧洲字符)、3 字节(大部分汉字)、4 字节(辅助平面字符);
优点:节省空间(英文文档与 ASCII 相同)、兼容 ASCII、无字节序问题;
缺点:对辅助平面字符编码较长,解码需判断字节长度;
应用:互联网(HTML、URL)、Linux 系统、编程语言(Python、Java 字符串内部转换)。
UTF-16:
可变长度编码:2 字节(BMP 字符)或 4 字节(辅助平面字符,通过代理对);
优点:平衡空间与效率,适合东亚语言(汉字多为 2 字节);
缺点:存在字节序问题(需用 BOM 标识),英文文档比 UTF-8 占用更多空间;
应用:Windows 系统、Java 字符串存储、.NET 框架。
UTF-32:
固定长度编码:每个码点均用 4 字节表示;
优点:编码 / 解码简单(无需判断长度);
缺点:空间占用大(是 UTF-8 的 2-4 倍);
应用:较少用于存储和传输,主要用于内部处理(如字体渲染)。
简言之:Unicode 是 “字典”(字符与码点的对应表),UTF-8/16/32 是 “翻译器”(将码点转换为字节的工具)。
七、Unicode 的应用场景
Unicode 已成为现代信息技术的基础标准,其应用渗透到数字世界的方方面面。
1. 操作系统与软件
几乎所有主流操作系统(Windows、macOS、Linux、Android、iOS)均以 Unicode 为核心编码标准,确保系统界面、文件名称、输入法等支持多语言。例如:
Windows 从 Windows 2000 开始采用 UTF-16 作为内核编码;
Linux 和 macOS 默认使用 UTF-8 处理文件和终端输出。
2. 编程语言与开发
多数现代编程语言将 Unicode 作为字符串的默认编码:
Java、C# 的字符串内部采用 UTF-16 存储;
Python 3 的字符串基于 Unicode 码点,支持所有 Unicode 字符;
JavaScript 的字符串使用 UTF-16 编码,与 Java 兼容。
这使得开发者无需关注底层编码细节,即可直接处理多语言字符。
例如:
Java 中的 char 是一种基本数据类型,专门用于表示单个字符。Java 使用 Unicode 作为字符编码标准,char 类型直接映射到 Unicode 的 16 位编码(UTF-16)
常见字符示例:
'A'的 Unicode 码点是\u0041。'中'的 Unicode 码点是\u4E2D。
char c1 = 'A'; // 单个字母
char c2 = '中'; // 汉字
char c3 = '😀'; // 表情符号(Unicode 扩展字符)
char c4 = '\u0041'; // Unicode 编码表示(等价于 'A')
3. 互联网与通信
互联网的全球化依赖 Unicode 的支持:
HTML5、XML、JSON 等标准均以 Unicode 为基础,默认使用 UTF-8 编码;
电子邮件(SMTP)、即时通讯(如微信、WhatsApp)通过 Unicode 实现多语言消息传输;
URL 中的非 ASCII 字符(如汉字)需通过 “百分号编码” 转换为 UTF-8 字节序列后传输。
4. 文档与出版
数字文档格式(如 PDF、Office 文档、电子书 EPUB)均采用 Unicode 编码,确保在不同设备和系统中正确显示多语言内容。例如,PDF 中的字体信息包含 Unicode 码点与字形的映射,使得一份包含中英日三种语言的文档可在全球任何设备上打开。
5. emoji 与符号
emoji 作为现代数字通信的重要元素,其标准化完全依赖 Unicode:每个 emoji 都有唯一的 Unicode 码点(如 “👍” 对应 U+1F44D),确保在不同平台(手机、电脑、社交软件)上显示一致(尽管外观可能因设计风格略有差异)。
八、结束语
Unicode 编码标准的出现,是人类应对全球化信息浪潮的重要技术突破。它不仅解决了 “乱码” 这一长期困扰数字世界的问题,更构建了一套跨越语言、文化、平台的字符沟通体系,让信息在全球范围内的自由流动成为可能。
从 1991 年的 7000 个字符到如今的 14.9 万个字符,Unicode 的发展历程不仅是技术的演进,更是人类文化多样性在数字世界的映射。它收录的不仅是字符,更是语言、历史和文明 —— 古埃及象形文字的加入让数千年的文明遗产得以数字化保存,emoji 的标准化则反映了现代通信方式的革新。
未来,随着人工智能、元宇宙等新技术的发展,Unicode 仍将发挥核心作用:它将继续收录新的字符(如新兴符号、人造语言文字),优化编码效率,为更复杂的多语言交互场景提供支持。在这个意义上,Unicode 不仅是一套编码标准,更是数字时代的 “世界语”,连接着不同的文化与思想,推动着全球信息文明的进步。


