
本文较长,建议点赞收藏,以免遗失。
在大语言模型(LLM)的推理过程中,Attention机制是计算和内存消耗的主要瓶颈。FlashAttention和PagedAttention作为两项革命性优化技术,分别从计算效率和内存管理两个维度显著提升了LLM的推理性能。今天我将深度解析这两种注意力加速技术及其优化策略,希望对你有所帮助,如有遗漏,欢迎交流。
一、Transformer中的Attention机制与性能瓶颈
Transformer的核心在于自注意力机制,它通过计算序列中各token之间的关系权重,实现全局交互。标准自注意力机制的计算公式为:

其中Q(查询)、K(键)、V(值)是输入序列经过线性变换后的三个矩阵,dₖ为特征维度。

自注意力机制的时间复杂度为O(n²d),空间复杂度为O(n²+Nd),其中n为序列长度,d为特征维度。这种二次复杂度导致长序列处理时计算量和内存占用急剧增加,成为模型扩展的主要障碍。
在推理过程中,KV Cache需要存储所有已生成token的键值对,以便后续计算。传统实现要求KV Cache使用连续的显存空间,但实际序列长度各不相同,导致大量碎片化内存无法被有效利用。研究表明,由于碎片化和过度预留,现有系统浪费了60%-80%的显存。
(ps:这里补充一个知识点,如果你对KV Cache的工作原理和机制不了解,我这里也整理了一份小白都能看懂的技术文档,粉丝朋友自行查阅:《小白也能看懂的LLMs中的KV Cache,视觉解析》)
二、FlashAttention:I/O感知的精确注意力算法
FlashAttention是一种针对Transformer模型中注意力机制的计算优化技术,由斯坦福DAWN实验室于2022年提出。其并非注意力的近似算法,而是一种在数学上与标准注意力等价,但实现方式上完全不同的精确注意力算法。

FlashAttention的核心目标是减少对HBM的访问次数,最大限度地利用GPU上速度更快的片上SRAM,特别适用于处理长序列任务。
标准注意力机制使用HBM来存储、读取和写入注意力分数矩阵。具体步骤为将这些从HBM加载到GPU的片上SRAM,然后执行注意力机制的单个步骤,然后写回HBM,并重复此过程。
而Flash Attention采用分块计算(Tiling)技术,将大型注意力矩阵划分为多个块(tile),在SRAM中逐块执行计算。
核心原理
FlashAttention的核心思想是分块计算(tiling)和重计算(recomputation)。将输入矩阵Q、K、V分割成小块,每次只处理其中一块数据,在GPU的片上SRAM中进行计算,避免频繁访问高带宽内存(HBM)。同时,通过安全softmax(safe softmax)技术处理数值稳定性问题,并在反向传播中利用存储的中间统计量重新计算梯度,而非存储整个注意力矩阵。
分块策略将Q、K、V矩阵分割为多个小块,块大小的选择需平衡SRAM容量与计算效率。具体来说,将Q分成Tr块,每块大小为Br×d;将K和V分成Tc块,每块大小为Bc×d。在计算时,逐块加载Q、K、V到SRAM,计算局部注意力得分,再通过累积统计量(最大值和指数和)得到全局结果。
重计算机制在反向传播中不需要存储O(n²)的中间注意力矩阵,而是通过存储输出O、softmax归一化统计量(最大值m和logsumexp L)来重新计算梯度。
FlashAttention-2改进
2023年提出的FlashAttention-2进一步优化了工作分区(work partitioning),减少了非矩阵乘法运算的需求,并实现了序列长度上的并行化。

具体改进包括:消除频繁的系数更新,减少对非矩阵乘法运算的需求;在CUDA线程块内分配工作到不同warp上,减少通信和共享内存读写;仅存储logsumexp统计量,而非同时存储max和sum。
FlashAttention在A100 GPU上实现了显著的性能提升:BERT模型训练速度比MLPerf 1.1记录高出15%;GPT-2训练速度比HuggingFace实现高3倍,比Megatron高1.7倍;FlashAttention-2在A100上达到理论FLOPs的50-73%,训练速度提升至225 TFLOPs/s。
FlashAttention-3改进
2024年提出的FlashAttention-3针对Hopper架构(如H100 GPU)的硬件特性进行了深度优化,通过异步执行和低精度计算实现了突破性性能提升。
其核心改进包括:生产者-消费者异步,通过定义一个warp-specialized软件流水线方案,利用数据移动和Tensor Cores的异步执行,将生产者和消费者分为不同的warps,从而延长算法隐藏内存和指令发出延迟的能力。

在异步块状GEMM下隐藏softmax,通过重叠低吞吐量的非GEMM操作(如浮点乘加和指数运算)与异步WGMMA指令进行块矩阵乘法,重写FlashAttention-2算法以规避softmax和GEMM之间的某些顺序依赖性。

硬件加速的低精度GEMM调整前向传播算法以针对FP8 Tensor Cores进行GEMM,几乎翻倍了测量的TFLOPs/s。这需要弥合WGMMA在块布局一致性方面的要求,使用块量化和非相干处理来减轻由于转换为FP8精度而导致的精度损失。
在H100 GPU上实现里程碑式突破:FP16性能达到740 TFLOPs/s(75%理论峰值),较FlashAttention-2提升1.5-2.0倍;FP8性能接近1.2 PFLOPs/s,首次突破PetaFLOP级注意力计算;数值精度方面,FP8版本比基线FP8注意力降低2.6倍数值误差。

三、PagedAttention:高效的KV Cache内存管理
PagedAttention是一种显存管理优化技术,由UC Berkeley团队提出并集成到vLLM框架中。它借鉴了操作系统中虚拟内存和分页的经典思想,将KV Cache分割成固定大小的页面(pages),允许在非连续内存空间中存储连续的KV张量,从而有效解决显存碎片化问题。
核心问题:KV Cache管理的挑战
传统的KV Cache管理方式通常为每个请求预分配一个连续的大块内存,其大小等于模型的最大序列长度。这种方式存在严重问题:
内存浪费与碎片化:大部分请求的实际序列长度远小于最大长度,导致大量预分配的内存被浪费(内部碎片)。同时,不同请求序列长度各异,使得内存管理变得困难,容易产生无法被新请求利用的小块内存(外部碎片)。
并发吞吐量低:由于内存浪费严重,一块GPU能容纳的并发请求数受限,导致吞吐量低下。
复制开销大:在某些复杂的采样策略(如Beam Search)中,需要复制和管理多个序列的KV Cache,这在连续内存布局下意味着昂贵的memcpy操作。

核心原理
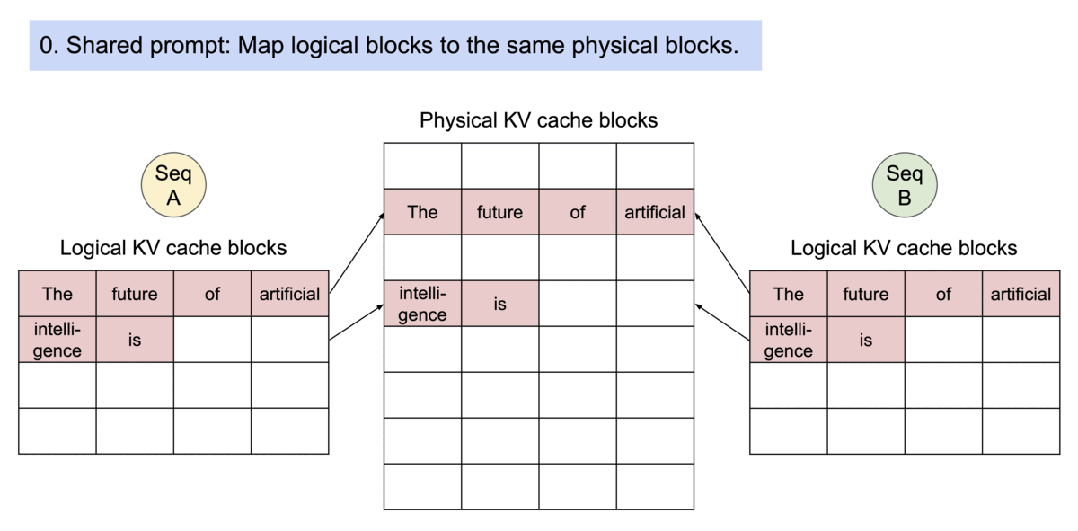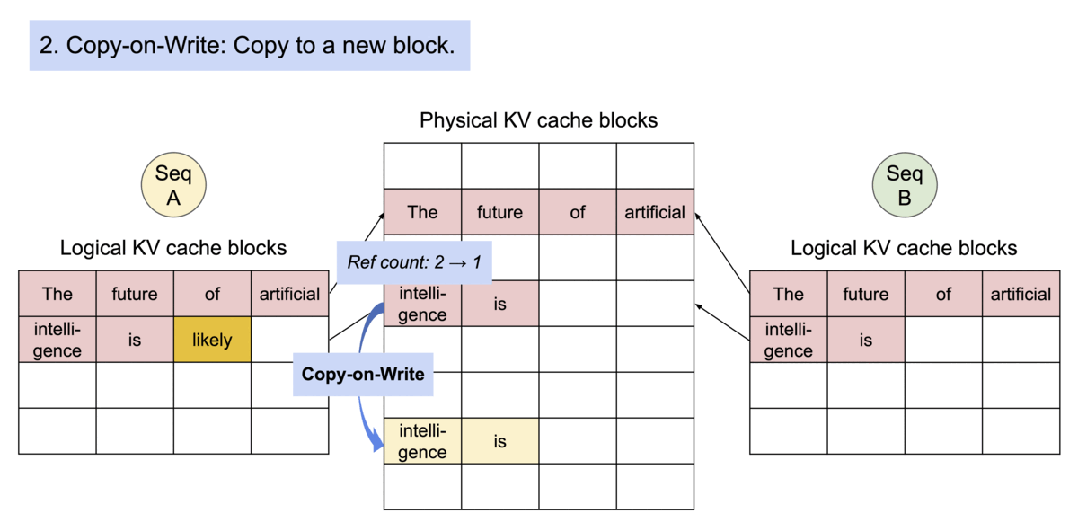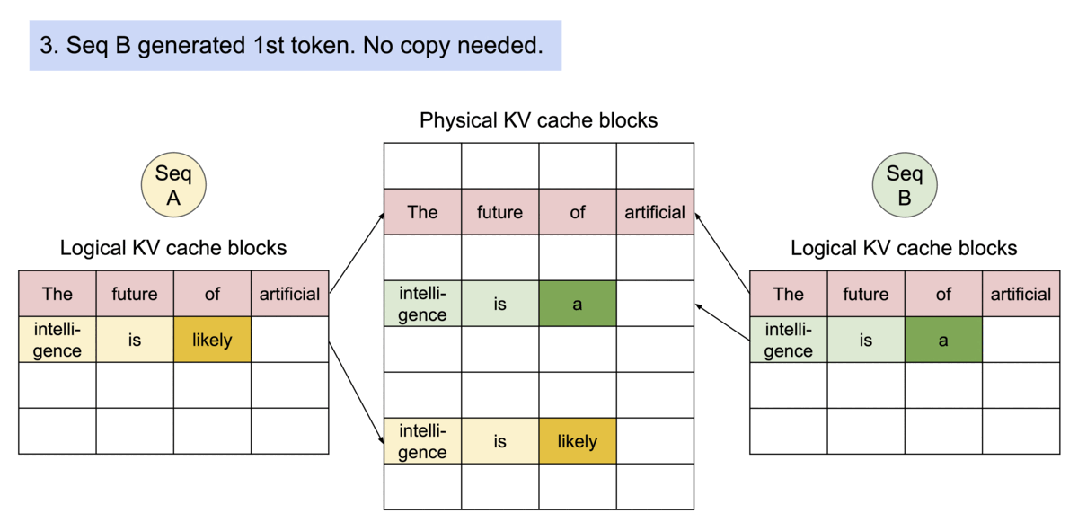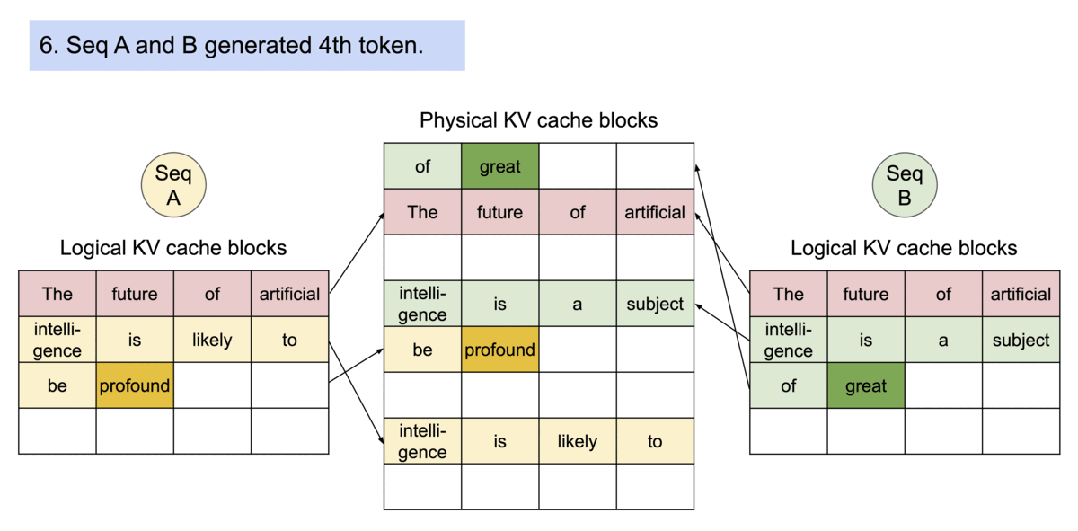
PagedAttention将每个序列的KV缓存进行分块,每个块包含固定长度的token的KV对。通过页面表(page table)维护逻辑地址到物理地址的映射,实现动态内存分配和共享。
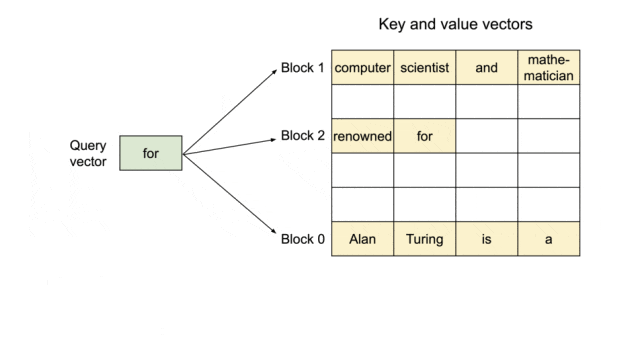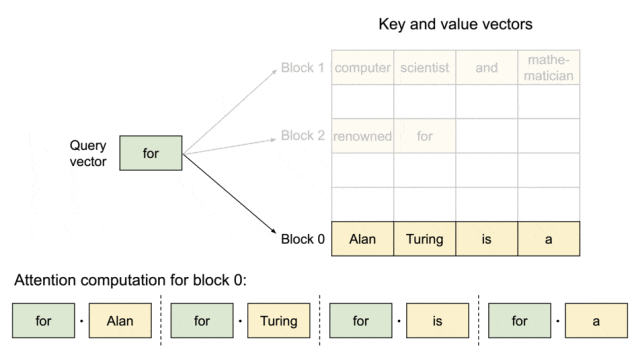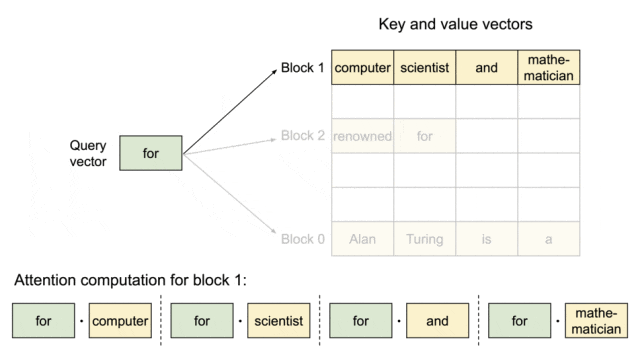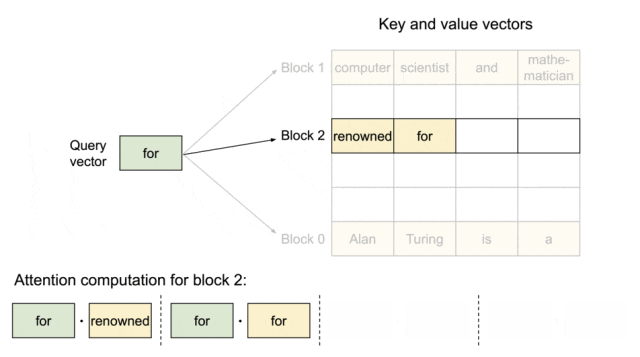
▲图示:PagedAttention:KV Cache 被划分成块。块在内存空间上不需要连续
PagedAttention将KV Cache划分成块,块在内存空间上不需要连续。系统为每个请求维护一个"块表"(类似于操作系统的页表),该表存储了逻辑块到物理块的映射关系。逻辑块是连续的,代表了token在序列中的位置;而物理块则是GPU显存中实际存储KV数据的、非连续的内存块。
当模型生成新token时,调度器只需为这个新token分配一个新的物理块,并更新该序列的块表即可。这种按需分配的方式避免了预先分配大块连续内存所造成的浪费。当一个请求结束时,其占用的所有物理块都可以被回收并用于其他请求。
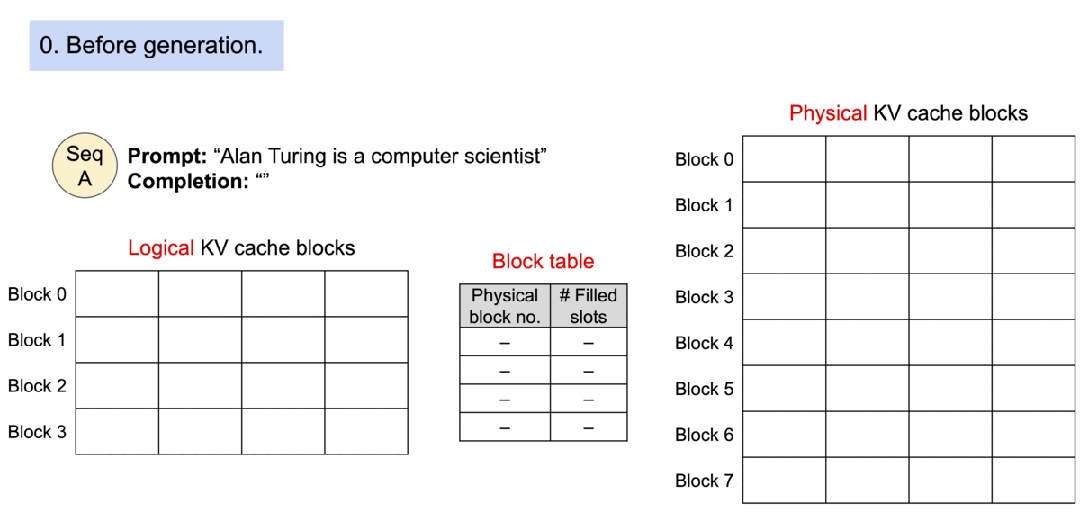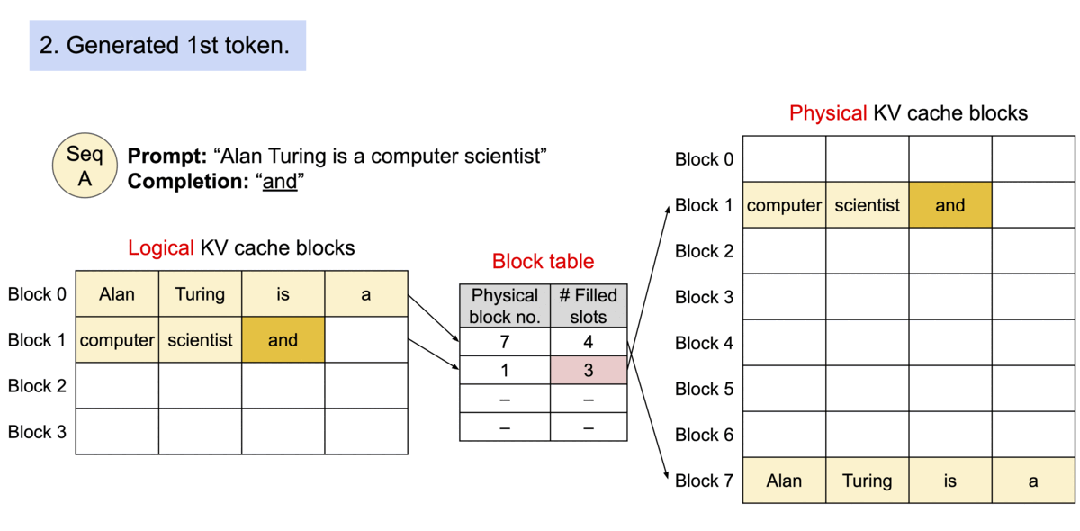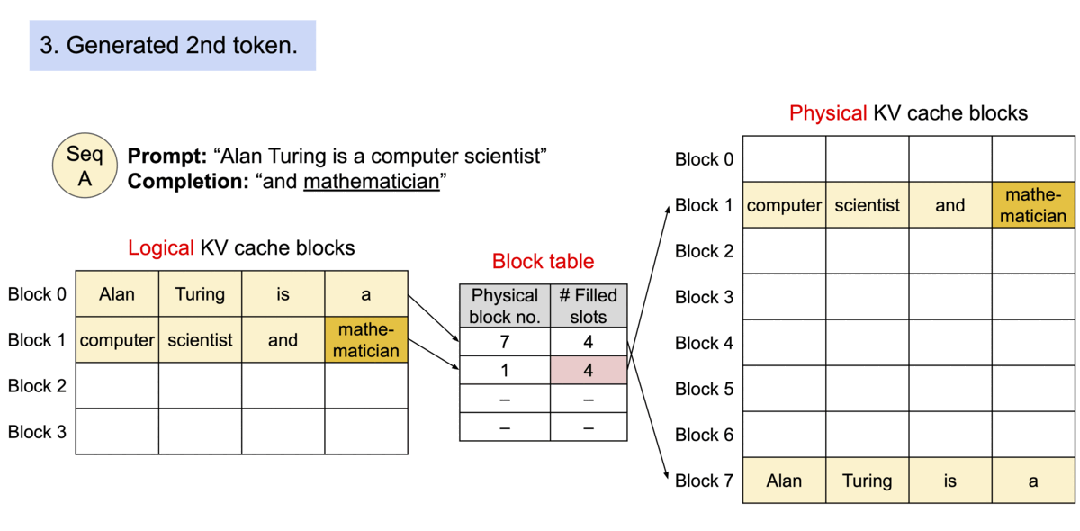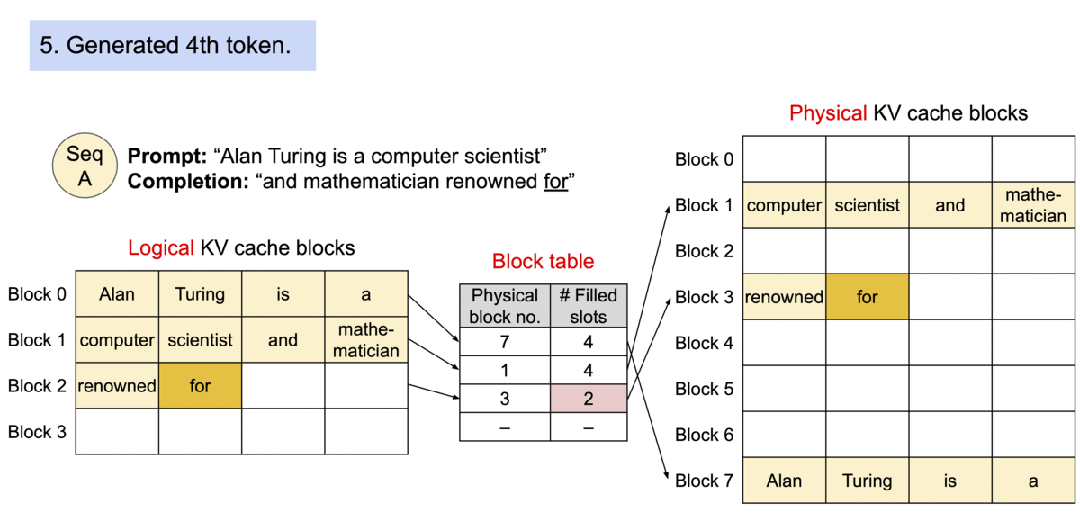
▲图示:具有 PagedAttention 的请求的示例生成过程
PagedAttention通过写时复制(Copy-on-Write,CoW)实现高效的内存共享。当多个序列共享同一个提示(prompt)时,它们的KV缓存页面可以指向同一个物理块。系统跟踪物理块的引用计数,当某个序列尝试修改共享页面时,才触发复制到新页面并更新引用计数。这种机制在并行采样和集束搜索中特别有效,可将内存使用量降低55%,吞吐量提升2.2倍。
▲图示:对多个输出进行采样的请求示例生成过程
性能优势
vLLM在相同延迟水平下,吞吐量较基线系统提升2-4倍,长序列、大模型场景优势更显著(如OPT-175B在Alpaca数据集上提升3.58倍)。内存浪费趋近于零,而基线系统浪费达61.8%-79.6%。在束搜索中内存共享节省37.6%-66.3%,共享前缀场景减少冗余计算16.2%-30.5%。块大小设为16时平衡并行性与碎片率,重计算较交换降低20%恢复开销。
写在最后
- FlashAttention是一种计算优化技术。它通过I/O感知的算法设计,将计算瓶颈从内存带宽转移回计算本身,是底层算法与硬件结构协同优化的典范。它主要在训练和单次长序列推理中发挥巨大作用。
- PagedAttention是一种内存管理技术。它通过精细化的内存分页和调度,解决了推理服务中KV Cache的管理难题,是系统工程层面的重大突破。它主要在高并发推理服务中提升系统吞吐量和资源利用率。
它们代表了大模型推理优化的两个重要方向:计算效率和内存管理,它们的结合使用使当前LLM推理性能的大幅提升。好了,今天的分享就到这里,如果对你有所帮助,记得点个小红心,我们下期见。
