
本文的第(一)部分介绍了SoccerNet数据集、SoccerNet 2025挑战赛、以及SoccerNet 2025挑战赛的赛题一;第(二)部分介绍了SoccerNet 2025挑战赛的赛题二;第(三)部分介绍了SoccerNet 2025挑战赛的赛题三。以下是本文的最后一部分,将介绍SoccerNet 2025挑战赛的赛题四。
赛题四:比赛状态重建
基于足球比赛视频实现的球员定位与识别,能用来支撑多类下游应用,包括估计球员的跑动距离、理解球队的战术、支持教练员和球员训练、提升观众观看比赛的视觉效果等[1]。场上球员的定位与识别可以由人工来进行标注,不过费时费力,成本较高;而采用计算机视觉技术来自动、可靠地从比赛视频中抽取球员的定位和识别信息,正受到越来越多的关注。
SoccerNet 2025挑战赛的“比赛状态重建”(Game State Reconstruction)赛题要求仅根据单个摄像机的拍摄,来定位、识别出足球赛场上的球员,并生成俯视角度的小地图(Minimap,如下图底部所示)[2]。
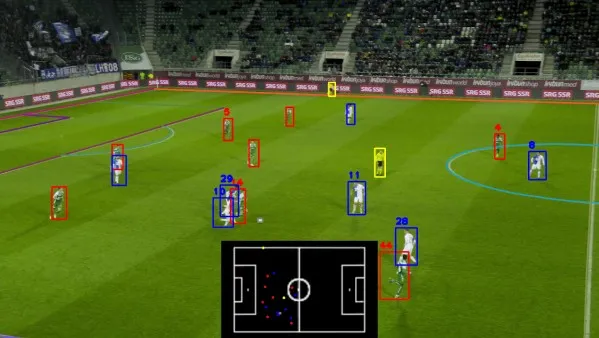
该赛题中,具体需要从比赛视频中定位、识别的信息包括[2]:
- 足球场上所有人员的位置;
- 上述人员的角色分类,包括球员、守门员、裁判员、以及其它(教练员、队医等不属于前三个类别的人员)四类;
- 上述球员和守门员的球衣号码;
- 每个球员和守门员所属的球队(摄像画面中的左方球队还是右方球队)。
该赛题的训练数据、公开测试数据、以及不公开的挑战赛数据均出自于SoccerNet-GSR数据集[1]。SoccerNet-GSR数据集围绕上述的“比赛状态重建”任务,收集并标注了200个足球比赛视频片段,每片段视频的时长为30秒。
该赛题的数据集和代码库都放在了GitHub上(https://github.com/SoccerNet/sn-gamestate)。
“比赛状态重建”任务可以分解成以下多个子任务[1]:
- 场地定位(Pitch Localization)、相机标定(Camera Calibration);
- 人员的检测(Detection)、重识别(Re-Identification)、跟踪(Tracking);
- 人员角色分类(Role Classification)、球队归属(Team Affiliation)、球衣号码识别(Jersey Number Recognition)。
评测指标
“比赛状态重建”任务有点类似于“多目标跟踪”(Multi-Object Tracking)任务。然而“多目标跟踪”任务的评测指标(如MOTA和HOTA)无法用来衡量“比赛状态重建”任务中球员所属球队、球员球衣号码、场上人员角色等的信息抽取的准确性。此外,“多目标跟踪”的评测指标中常用IoU来衡量人员等目标的边界框预测的准确程度,而在“比赛状态重建”任务中,人员用场地坐标系中的点来表示,无法使用IoU来衡量位置预测的准确程度。
基于上述原因,SoccerNet-GSR数据集的论文[1]提出了专用于“比赛状态重建”这一任务的GS-HOTA评测指标。本届挑战赛的“比赛状态重建”赛题也采用了GS-HOTA这一指标来进行评测。
GS-HOTA指标是“多目标跟踪”的评测指标HOTA[3]的一个改进版。HOTA指标的公式是:
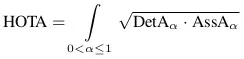
其中,DetA和AssA分别是检测和关联的准确度,α是预测值与真实值之间相似度的阀值。
在HOTA指标的计算中,预测值与真实值之间相似度的计算涉及到目标的边界框的IoU值。在GS-HOTA指标中,有关相似度的计算得到了改进(计算公式稍后列出);使用改进后的相似度、以及上述原始的HOTA指标的计算公式,就能计算出GS-HOTA评测指标。改进后的相似度计算公式为:
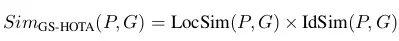
其中,
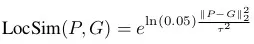
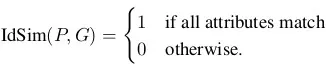
LocSim(P, G)根据预测的点P和真实的点G之间在场地坐标系中的欧氏距离,计算出人员位置预测的准确程度。
IdSim(P, G)的值是1或者0,1表示球员所属球队、球员球衣号码、人员角色等人员属性的预测值P与真实值G完全匹配,0表示人员属性的预测值P中至少有一项不准确。
基线方案
赛题的基线方案采用了SoccerNet-GSR数据集论文[1]中的GSR-Baseline方案。该方案将“比赛状态重建”任务分解成多个子任务,每个子任务均采用了SOTA的开源解决方法。为了支撑复杂流程的开发,该方案使用了多目标跟踪框架TrackLab(https://github.com/TrackingLaboratory/tracklab)。
比赛结果
经评测,有十余支参赛队的方案表现优于基线方案[2]。
在目标检测子任务中,采用微调后的检测模型成为了标准做法,较多采用的模型包括YOLO-X、YOLOv8、YOLOv11、RF-DETR等。
在人员跟踪子任务中,通过检测进行跟踪(Tracking-by-Detection)是各参赛队的主流做法,较多采用的算法包括Deep-EIoU、BoT-SORT和GTA(Global Tracklet Association)。
在相机标定子任务中,较多涉及的方法包括特征点检测、单应性估计(Homography Estimation)等,较多涉及的Pipeline包括NBJW、PnLCalib和Broadtrack。
在人员特征提取子任务中,基于CLIP和OSNet的特征提取表现良好。LLaMA-Vision、Qwen2 VL Instruct等视觉-语言模型用于球衣号码识别较为成功。
参考文献
[1] SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap
https://arxiv.org/abs/2404.11335
使用许可协议:CC BY
https://creativecommons.org/licenses/by/4.0/
[2] SoccerNet 2025 Challenges Results
https://arxiv.org/abs/2508.19182
使用许可协议:CC BY
https://creativecommons.org/licenses/by/4.0/
[3] HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking
https://arxiv.org/abs/2009.07736
封面图:Riccardo、pexels


