数据湖与数据仓库:初学者的指南
在当今大数据时代,企业需要处理和存储海量数据。数据湖与数据仓库作为两种主要的数据存储解决方案,各自有其独特的优势与适用场景。本文将为初学者介绍数据湖与数据仓库的基本概念、特点及其应用场景,并通过代码示例帮助大家更好地理解。
数据湖 vs. 数据仓库
数据湖是一个中心化存储库,可以存储各种格式的原始数据,无论是结构化、半结构化还是非结构化数据。数据湖的主要特点如下:
- 存储类型多样:支持存储结构化、半结构化和非结构化数据。
- 成本低:通常基于Hadoop或云存储,适合存储大规模数据。
- 灵活性高:数据无需转换即可存储,可根据需求进行处理。
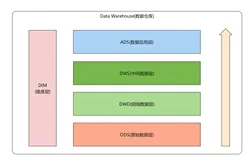
数据仓库是一种针对结构化数据进行存储、处理和分析的系统,通常用于商业智能和数据分析。数据仓库的主要特点如下:
- 结构化数据存储:主要用于存储结构化数据,需要预先定义数据模式。
- 高性能查询:针对复杂查询进行了优化,适合高性能数据分析。
- 数据清洗:数据需在加载前进行转换和清洗,保证数据的一致性和准确性。
数据湖与数据仓库的适用场景
数据湖和数据仓库在不同的应用场景中各有优势。以下是一些常见的适用场景:
数据湖的应用场景:
- 数据科学与机器学习:数据湖支持存储原始数据,数据科学家可以从中提取有用的信息进行模型训练。
- IoT数据存储:数据湖适合存储来自物联网设备的大量半结构化或非结构化数据。
- 大数据分析:数据湖可用来存储和处理海量数据,适合进行大规模数据分析。
数据仓库的应用场景:
- 商业智能(BI):数据仓库适用于商业智能工具,可以帮助企业进行决策支持和数据分析。
- 报表生成:由于数据仓库中的数据经过清洗和转换,适合生成准确的业务报表。
- 历史数据分析:数据仓库适合存储历史数据,进行趋势分析和预测。
代码示例
以下是如何在AWS上创建数据湖和数据仓库的简要示例。
数据湖(S3+Glue+Athena):
import boto3
# 创建S3客户端
s3_client = boto3.client('s3')
# 创建S3存储桶
bucket_name = 'my-data-lake-bucket'
s3_client.create_bucket(Bucket=bucket_name)
# 上传数据到数据湖
s3_client.upload_file('local-data.csv', bucket_name, 'data/local-data.csv')
# 使用Glue创建数据目录并进行数据爬取
glue_client = boto3.client('glue')
# 创建Glue数据库
database_name = 'my_data_lake_db'
glue_client.create_database(DatabaseInput={
'Name': database_name})
# 创建Glue爬取器
crawler_name = 'my_data_crawler'
glue_client.create_crawler(
Name=crawler_name,
Role='AWSGlueServiceRole',
DatabaseName=database_name,
Targets={
'S3Targets': [{
'Path': f's3://{bucket_name}/data/'}]}
)
# 启动爬取器
glue_client.start_crawler(Name=crawler_name)
# 使用Athena查询数据
athena_client = boto3.client('athena')
query = "SELECT * FROM my_data_lake_db.local_data"
response = athena_client.start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database': database_name},
ResultConfiguration={
'OutputLocation': f's3://{bucket_name}/output/'}
)
数据仓库(Amazon Redshift):
-- 创建Redshift集群
CREATE EXTERNAL TABLE redshift_spectrum_schema.my_table (
id INT,
name STRING,
value DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://my-data-warehouse-bucket/data/';
-- 加载数据到Redshift
COPY my_schema.my_table
FROM 's3://my-data-warehouse-bucket/data/local-data.csv'
IAM_ROLE 'arn:aws:iam::account-id:role/RedshiftCopyUnload';
-- 查询数据
SELECT * FROM my_schema.my_table WHERE value > 100;
结论
数据湖与数据仓库各有其独特的优势和适用场景,理解它们之间的差异对于选择合适的数据存储解决方案至关重要。数据湖适用于存储海量、多样化的原始数据,适合数据科学和大数据分析;而数据仓库则专注于高性能的数据查询和分析,适合商业智能和报表生成。在实际应用中,企业可以根据自身需求,灵活运用数据湖和数据仓库,打造高效的数据管理体系。