1、 微服务间事务处理最优解决方案
现状:无微服务间事务
期望:其他更优解决方案,比如Seata?
场景
跨系统支付,电商订单库存等业务场景使用较多。
解决方案
Seata(Simple Extensible Autonomous Transaction Architecture)是一个开源的分布式事务解决方案,它由阿里巴巴开源。Seata 提供了 AT(自动事务)、TCC(尝试-确认/取消)、Saga 等事务模式,可以与Dubbo、Spring Cloud、gRPC等框架结合使用。
Dubbo 也不直接支持分布式事务,但可以通过以下方式实现:
Seata: Seata 支持 Dubbo,并提供了相应的集成插件。
2、 微服务间调用最优解决方案
现状:Feign调用、HttpURLConnection调用
期望:其他更优解决方案
解决方案
首先不推荐使用HTTP,开销过大,对性能影响非常严重。
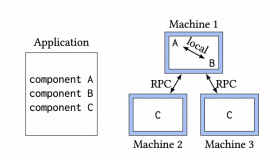
1、推荐dubbo框架,Dubbo 是一个高性能 RPC框架,它的服务调用更像是本地方法调用的远程扩展。提供服务治理能力,包括注册中心,服务探活,服务路由规则灵活可配置等。
Dubbo 框架本身对分布式事务有一定的支持:与 Seata 框架集成。
2、如果不需要服务发现和服务治理相关功能,可以考虑选择轻量级的RPC框架PB,性能更快,也可以支持非java代码,但是代码编写起来比dubbo要难上手一点。
3、 大数据处理的解决方案(TB级就行)
现状:无系统,想做大数据处理展示系统,一部分实时性、一部分天、月、年数据写入读取
期望:一套大数据解决方案
解决方案
1、非实时选型
推荐的开源生态:Hadoop生态系统
Hadoop Distributed File System (HDFS)
功能: 分布式文件系统,用于存储大规模数据。 特点: 高容错性、高吞吐量、适合大规模数据存储。
Hive 功能: 数据仓库工具,提供SQL接口进行数据查询和分析。 特点: 适合大数据的批量处理和复杂查询,易于使用。
Pig 功能: 高级数据处理语言,使用Pig Latin编写脚本进行数据处理。 特点: 适合复杂的ETL操作,提供了丰富的数据处理操作符。
HBase 功能: 基于HDFS的分布式NoSQL数据库,支持实时读写访问。 特点: 高性能、可扩展性强,适合需要低延迟访问的应用。
2、实时
Spark: 大规模数据处理框架,支持批处理、流处理、机器学习和图计算。 特点: 性能优越,易于编程,支持多种语言(Scala、Java、Python、R)。
Flink: 实时流处理和批处理框架,提供低延迟和高吞吐量的数据处理能力。 特点: 支持事件时间处理,适合复杂的流处理场景。支持SQL标准语法,代码一致性高,维护成本低
4、 分库分表的必要前提,最优解决方案
现状:分库分表、数据库间dblink用连接,会造成system空间很大等问题
期望:其他什么好的方案
分库分表必要前提:
分库主要解决并发量大,无法满足业务需求;
分表主要解决数据量大,影响业务需求;
分库分表前必要前提就是软件件优化后仍然不能满足业务需求:
1)硬件优化:CPU、磁盘、内存、网络优化 (若性价比不高,优先采用软件层面优化);
2)软件层面: SQL调优、表结构优化 、读写分离 优先于 分库分表
超级汇川拆分前:单表单库数据量大(几十G到几千G),请求量大,查询速度、写入速度慢,db可靠性降低
基于此进行拆库拆表:
按账户id取模分库分表,业务使用时依赖自研框架(genericDao)sharding功能,业界tddl、sharding-jdbc
硬件层面:主要是增加机器性能,性能瓶颈不外乎就是CPU、磁盘、内存、网络这些,要解决性能瓶颈最简单粗暴的方式就是提升机器性能,但是通过这种方式投入产出比往往不高,也不划算,所以重点还是要从软件层面去解决问题
软件层面:SQL 调优、表结构优化、读写分离、数据库集群、分库分表等;
分库分表其实不是数据库优化方案的最终解决办法,一般来说说能用优化SQL、表结构优化、读写分离等手段解决问题,就不要分库分表,因为分库分表会带来更多需要解决的问题,比如说分布式事务,查询难度增大等。
其实,分库主要解决的是并发量大的问题。因为并发量一旦上来了,那么数据库就可能会成为瓶颈,因为数据库的连接数是有限的,虽然可以调整,但是也不是无限调整的。
所以,当当你的数据库的读或者写的QPS过高,导致你的数据库连接数不足了的时候,就需要考虑分库了,通过增加数据库实例的方式来提供更多的可用数据库链接,从而提升系统的并发度。
比较典型的分库的场景就是我们在做微服务拆分的时候,就会按照业务边界,把各个业务的数据从一个单一的数据库中拆分开,分表把订单、物流、商品、会员等单独放到单独的数据库中。
分库主要解决的是并发量大的问题,那分表其实主要解决的是数据量大的问题。
假如你的单表数据量非常大,因为并发不高,数据量连接可能还够,但是存储和查询的性能遇到了瓶颈了,你做了很多优化之后还是无法提升效率的时候,就需要考虑做分表了。
通过将数据拆分到多张表中,来减少单表的数据量,从而提升查询速度。
一般我们认为,单表行数超过 500 万行或者单表容量超过 2GB之后,才需要考虑做分库分表了,小于这个数据量,遇到性能问题先建议大家通过其他优化来解决。
https://www.ljjyy.com/archives/2023/06/100683
总结一下水平拆分和垂直拆分的特点:
- 垂直切分:基于表或者字段划分,表结构不同。
- 水平拆分:基于数据划分,表结构相同,数据不同。根据表中字段的某一列特性,分而治之。
分库分表带来的问题
既然分库分表方案那么好,那我们是不是在项目初期就应该采用这种方案呢?莫慌,虽然分库分表解决了很多性能问题,但是同时也给系统带来了很多复杂性。下面我展开说说
1. 跨库关联查询
之前单体项目,我们想查询一些数据,无脑join就好了,只要数据模型设计没啥问题,关联查询起来其实还是很简单的。现在不一样了,分库分表后的数据可能不在一个数据库,那我们如何关联查询呢?
下面推荐几种方式去解决这个问题:
字段冗余:把需要关联的字段放到主表中,避免join操作,但是关联字段更新,也会引发冗余字段的更新;
数据抽象:通过ETL 等将数据汇总聚合,生成新的表;
全局表:一般是一些基础表可以在每个数据库都放一份;
应用层组装:将基础数据查出来,通过应用程序计算组装;
同特征的数据在一张表:举个例子:同一个用户的数据在同一个库中,比如说我们对订单按照用户id进行分表,订单主表、订单拓展信息表、跟订单有关联查询的表都按照用户id 进行分表,那么同一个用户的订单数据肯定在同一个数据库中,订单维度的关联查询就不存在跨库的问题了。
2. 分布式事务
单数据库我们可以用本地事务搞定,使用多数据库就只能通过分布式事务解决了。
常用的解决方案有:基于可靠消息(MQ)的最终一致性方案、二段式提交(XA)、柔性事务。
3. 排序、分表、函数计算问题
使用SQL 时,order by 、limit 等关键字需要特殊处理,一般都是采用数据分片的思路:现在每个分片路由上执行函数、然后将每个分片路由的结果汇总再计算,然后得出最终结果。
4. 分布式ID
既然分库分表了,主键id已经不能唯一确定我们的业务数据了,随之而来的就是分布式id,顾名思义就是在多个数据库多张表中唯一确定的ID。
常见的分布式Id 解决方案有:
UUID
基于全局数据库自增的ID表
基于Redis缓存生成全局ID
雪花算法(Snowflake)
原文链接:https://blog.csdn.net/m0_71777195/article/details/128640968
5、 大文本的存储解决方案
现状:新系统产品想页面上输入纯文字会超过数据库字段最大值,用LOB类型处理会增加程序处理的复杂性
期望:大文本的存储取得方案
- 外部存储服务:对于极其庞大的文本数据,可以考虑将其存储在专门的对象存储服务上,如阿里云OSS,并仅在数据库中保存指向该文件的URL或ID。这种方式非常适合需要频繁更新或者版本控制的大文档。(oss通过简单上传、表单上传、追加上传的方式上传单个文件,文件的大小不能超过5 GB。通过分片上传的方式上传单个文件,文件的大小不能超过48.8 TB)
- 数据压缩:在保存之前对文本进行压缩,然后在读取时解压。不过也难免会增加程序处理的复杂度
6、 Oracle统计信息设置优化方案
现状:数据量大了会造成统计信息过期,自动整理统计信息会失效
期望:如何防止自动整理统计信息会失效
- 自动统计信息收集:从Oracle 10g开始,默认情况下会启用自动统计信息收集功能(通过
DBMS_STATS包)。这个过程通常是在系统负载较低的时候自动运行的,比如晚上或者周末。不过,在一些情况下,如表的数据量非常大、变化频繁等,自动收集可能无法及时更新所有对象的统计信息。 - 手动统计信息收集:除了依赖自动收集外,DBA也可以根据需要手动触发特定表或整个模式下的统计信息收集。使用
DBMS_STATS.GATHER_TABLE_STATS或DBMS_STATS.GATHER_SCHEMA_STATS等过程可以实现这一点。对于特别大的表来说,这可能是确保其统计信息保持最新的一种好方法。 - 调整收集策略:可以通过修改
DBMS_STATS相关参数来自定义统计信息收集的行为,例如设置采样百分比、是否包括直方图等。合理配置这些选项可以帮助提高统计信息的质量和准确性。 - 监控与警告:利用Oracle提供的工具(如Enterprise Manager)来监控数据库的状态,并设置警报规则以便于发现潜在的问题。例如,当某个表的数据量增长超过了预设阈值时发出通知,提醒管理员考虑重新收集该表的统计信息。
7、 数据缓存处理解决方案
现状:数据缓存基本没用
期望:推荐比较好的spring的缓存解决方案
Spring Cache Abstraction:
- 这不是一种具体的缓存技术,而是Spring提供的一种抽象层,它允许开发者使用一致性的API来操作不同的底层缓存实现(如Caffeine, Redis等)。使用方法简单直观,只需要通过注解
@Cacheable,@CachePut, 和@CacheEvict等即可控制缓存的行为
本地缓存:Caffeine是一个高性能的Java 8缓存库。相比于Guava Cache,Caffeine提供了更好的性能以及更丰富的功能配置选项
Caffeine 是基于 JAVA 8 的高性能缓存库,并且在 spring5 (springboo 2.x) 后,spring 官方放弃了 Guava,而使用了性能更优秀的 Caffeine 作为默认缓存组件
Guava Cache 本质上还是使用了LRU淘汰算法,后续由前Google工程师发明的W-TinyLFU淘汰算法,提供了一个近乎最佳的命中率。Caffine Cache就是基于此算法而研发。
W-TinyLFU是如何解决LFU算法的缺点的呢?感兴趣可以看这里
https://jishuin.proginn.com/p/763bfbd358a0
原文链接:https://blog.csdn.net/qq_42651904/article/details/120210785
共享缓存:redis
- @Cacheable: 如果缓存没有命中则调用方法,然后缓存结果,以便下次直接返回缓存的结果.
- @CachePut: 更新缓存
- @CacheEvict: 从缓存中移除某条记录,或者清空缓存
- @EnableCaching: 启用缓存
8、 从Api接口中下载SQLite的数据库文件在安卓系统中使用
现状:在安卓系统中不断调用接口返回数据写入SQLite的数据库,比如1万条数据现需要调用10次,后台1000条数据调用一次接口。
期望:Api接口中下载SQLite的数据库文件在安卓系统中直接使用
直接生成SQLite数据库文件而不使用SQLite API或任何SQLite客户端工具(如sqlite3命令行工具)是非常具有挑战性的,因为SQLite数据库文件具有特定的内部结构。这种结构包括页头、表定义、索引以及其他元数据信息。手动创建这些内容不仅复杂而且容易出错。但是,如果你真的想尝试手动构建一个简单的SQLite数据库文件,这里提供了一个非常基础的例子来帮助理解其底层格式。
注意
- 本例仅用于教育目的,实际应用中强烈建议使用官方提供的API或工具。
- SQLite数据库格式可能随版本更新而变化,因此这种方法可能不适用于所有版本。
- 手动生成的数据文件可能会导致数据损坏或其他问题。
创建一个最简化的SQLite数据库文件
- 文件头部:
- 每个SQLite数据库以一个固定长度的页开始,称为“页面0”。这个页面包含了关于整个数据库的重要信息。
- 页面大小通常为1024字节(也可以是512, 2048等),其中前100字节被用来存储数据库的配置信息。
- 初始化文件:
- 创建一个新文件,并确保其大小至少为一页。
- 填充必要的头部信息。
下面是一个Python脚本示例,用于创建一个最小的SQLite数据库文件:
import struct # 定义基本的SQLite文件头 def create_sqlite_header(): # 文件头的基本布局 header = b'SQLite format 3\x00' # 版本号 header += b'\x00' * 6 # 保留空间 header += struct.pack('>H', 1) # 页大小 (1024) header += b'\x00' # 未使用的预留字段 header += struct.pack('>B', 64) # 最大嵌入式载荷大小 header += struct.pack('>B', 64) # 最小叶节点大小 header += b'\x00' * 32 # 文件更改计数器和数据库一致性检查码 header += b'\x00' * 20 # 自由列表页号 header += b'\x00' * 100 # 其他保留空间 return header.ljust(1024, b'\x00') # 补齐到完整的页大小 # 主函数 def main(): with open('test.db', 'wb') as f: # 写入第一个页面作为文件头 f.write(create_sqlite_header()) # 如果需要更多的空页,可以继续写入全零的页面 for _ in range(9): # 添加额外的9个空白页 f.write(b'\x00' * 1024) if __name__ == "__main__": main()
这段代码将创建一个名为test.db的SQLite数据库文件,它只包含一个有效的文件头以及一些空页。请注意,这只是一个非常基础的例子,没有实际的数据表或记录。对于更复杂的操作,如添加表格、索引等,你需要深入研究SQLite的文件格式规范,并且很可能最终会发现使用标准库或工具更加高效安全。