引言
在当今大数据时代,如何高效地从海量信息中获取所需知识,成为一个亟待解决的问题。检索增强的生成模型(Retrieval-Augmented Generation, RAG)应运而生,它结合了检索技术和生成模型的优点,旨在提高生成模型的回答质量和准确性。作为一名热衷于自然语言处理(NLP)领域的开发者,我有幸在多个项目中应用了RAG技术,并取得了不错的成效。本文将从我个人的实际经验出发,详细介绍如何使用RAG技术来构建一个问答系统,希望能够帮助那些已经对RAG有一定了解并希望将其应用于实际项目中的开发者们。
数据预处理
数据预处理是构建任何NLP模型的第一步。对于RAG来说,我们需要准备两部分数据:一部分是用于训练生成模型的对话数据;另一部分是用于构建检索库的知识库数据。
对话数据处理
对话数据通常包含问题和答案对,我们需要对其进行清洗和整理。这包括去除无关字符、纠正拼写错误、统一格式等。此外,还需要将对话数据划分为训练集、验证集和测试集。
示例代码:对话数据清洗
import pandas as pd
def clean_text(text):
# 清洗文本的函数
return text.strip().lower()
data = pd.read_csv('qa_data.csv')
data['question'] = data['question'].apply(clean_text)
data['answer'] = data['answer'].apply(clean_text)
构建检索库
检索库是RAG模型的核心组成部分之一。它通常由一系列文档组成,每个文档包含有关某一主题的信息。这些文档可以来自于互联网、书籍、论文等多种来源。为了提高检索效率,我们需要将文档转换为适合检索的格式,比如TF-IDF向量或BERT嵌入。
示例代码:构建TF-IDF向量
from sklearn.feature_extraction.text import TfidfVectorizer
documents = ['...']
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(documents)
训练生成模型
有了预处理好的数据之后,下一步就是训练生成模型。在RAG框架中,我们通常使用Transformer模型(如BERT或T5)作为生成模型的基础。
训练生成模型
我们可以使用PyTorch或TensorFlow等深度学习框架来训练生成模型。在训练过程中,除了常规的损失函数外,我们还需要考虑检索部分的影响。
示例代码:训练T5模型
from transformers import T5Tokenizer, T5ForConditionalGeneration, Trainer, TrainingArguments
tokenizer = T5Tokenizer.from_pretrained('t5-small')
model = T5ForConditionalGeneration.from_pretrained('t5-small')
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
trainer.train()
系统集成测试
一旦生成模型训练完毕,我们需要将其与检索系统集成,并进行全面的测试。
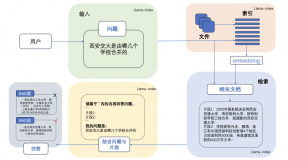
集成检索与生成
在集成阶段,我们需要确保检索系统能够正确地返回相关的文档片段,并将这些片段传递给生成模型作为上下文信息。生成模型则根据输入的问题和上下文信息生成答案。
示例代码:集成检索与生成
def retrieve_documents(question, top_k=5):
# 使用TF-IDF矩阵检索文档
query_vector = vectorizer.transform([question])
similarities = (tfidf_matrix * query_vector.T).toarray()[0]
top_indices = similarities.argsort()[-top_k:][::-1]
return [documents[i] for i in top_indices]
def generate_answer(question, context):
input_ids = tokenizer.encode(question + ' ' + context, return_tensors='pt')
output_ids = model.generate(input_ids)
answer = tokenizer.decode(output_ids[0], skip_special_tokens=True)
return answer
测试与评估
最后,我们需要对集成后的系统进行全面的测试,包括准确性、响应时间和鲁棒性等方面的评估。
优化技巧与常见问题解决
在实际应用过程中,可能会遇到一些挑战。以下是一些优化技巧和解决常见问题的方法:
- 性能优化:使用更高效的检索算法,如Faiss,来加速检索过程。
- 过拟合:通过早停法(Early Stopping)或数据增强来防止过拟合。
- 上下文选择:优化上下文选择算法,确保生成的答案与问题高度相关。
- 部署问题:在部署时,考虑到服务器资源限制,可能需要对模型进行剪枝或量化。
结语
通过本文的介绍,相信你已经对如何使用RAG技术来构建一个问答系统有了较为全面的认识。RAG技术结合了检索和生成的优点,能够有效提升问答系统的性能。希望本文能够为你在实际项目中应用RAG提供一些参考和启发。如果你有任何疑问或想要分享自己的经验,请随时留言交流。让我们一起探索更多NLP领域的可能性吧!